特征可视化、倒置、对抗样本
卷积神经网络的内部真正的工作原理是什么?我们已经在课上见到了如何训练卷积神经网络,以及如何构建不同类型架构来解决不同的问题。但是这些神经网络的内部到底是怎么运行的,它们是如何完成各自特定的工作,这些都还没有解释。它们要寻找的特征类型是什么,以及所有与这些相关的问题。
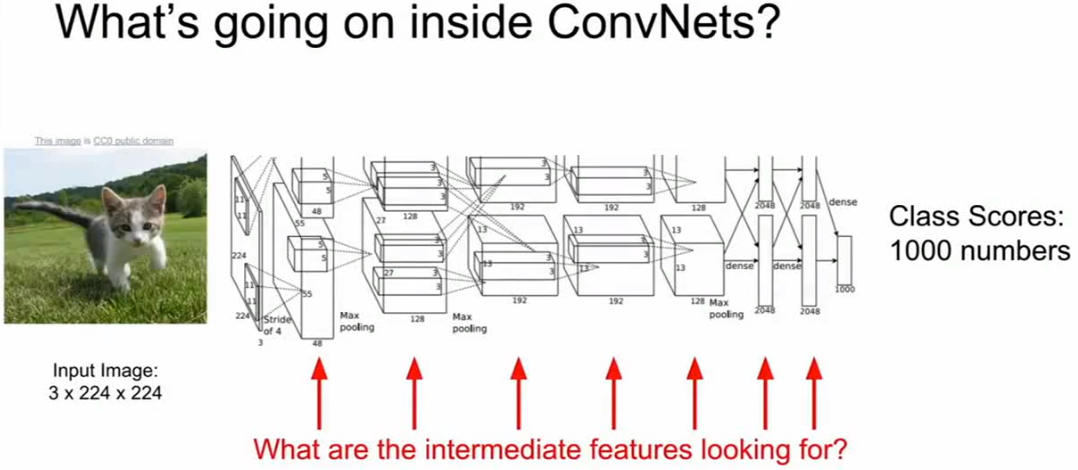 神经网络的内部到底是怎么运行的?(来自cs231n)
神经网络的内部到底是怎么运行的?(来自cs231n)
到目前为止,我们一直把卷积神经网络看成一个黑箱子,包含原始像素的输入图像,从黑箱子的一端进来,它经过了卷积网络的很多层,并且进行了许多不同的转换,在卷积网络的输出端,我们会得到一些类的分值,或是可被理解以及可被解释的输出,比如类的分值、边框的位置,或是标记的像素之类的。但问题是这些中间层的作用是什么?在输入图片中,它们在寻找什么?我们是否能再次根据直觉来判断CNN是如何工作的,它们在图像中寻找的东西是什么样的,并且对于分析网络的内部结构,我们可以使用什么样的技术。
相对来说,第一层比较简单,并且之前我们已经讲过第一层的相关知识,现在来回忆下。第一个卷积层由一个卷积核组成,例如在AlexNet中,第一个卷积层由许多卷积核组成,每个卷积滤波器的形状是3*11*11,这些卷积核在输入图像上来回滑动,我们取图像块和卷积核权重的内积(即点积),这就是我们在第一个卷积层的输出。在AlexNet中有64个卷积核,但是现在因为在第一个卷积层中,得到了卷积层的权重与输入图像像素的内积。所以我们可以通过简单的可视化得到卷积核的权重,作为图像本来得到卷积核需要的东西。
 可视化第一层卷积核的权重(来自cs231n)
可视化第一层卷积核的权重(来自cs231n)
所以,对于每个AlexNet里形状为11*11*3的卷积核,我们可以把这个滤波器看成有三个通道的形状为11*11的图像,并给定红色、绿色、蓝色的值。因为这里有64个卷积核,我们可以把它看成有64个通道的形状为11*11的图像。如上图所示,这是从PyTorch Model Zoo的预训练模型中提取的卷积核,并且我们正在观察卷积核,AlexNet第一层的卷积核,即ResNet-18、ResNet-101,以及DenseNet-121的权重,并且你可以看到,这些层中卷积核正在寻找什么。你可以看到它们都在寻找有向边,比如明暗线条,从不同的角度和位置来观察输入图像。我们可以看到完全相反的颜色,比如绿色和粉色,或者橙色和蓝色等相反的颜色,这与我们谈论的Hugo和Wiesel的研究有关。
在第一节课中,我们谈论到人类的视觉系统,是用来察觉有向边之类的物体,这些卷积神经网络,包括卷积神经网络的第一个卷积层,倾向于做一些类似于人类视觉系统早期阶段的工作。而且有趣的是,无论你连接的体系结构,或者在卷积神经网络上的训练数据类型是什么,你几乎总是能得到任何一个卷积神经网络中的第一个卷积层的权重。如上图所示,有向边和相反的颜色,观察一下输入图像。
Q:为什么要可视化卷积核的权重?
是为了让你知道卷积核在寻找什么,这个直觉来源于模板匹配和内积。想象一下,如果有一些模板向量,然后你通过模板向量和一些任意的数据之间的点积,得到了标量输出。然后当这两个向量相互匹配,输入将在范数约束的条件下被最大化,不管你在什么时候进行内积,你正在进行内积的对象是内积的结果最大化的因素,所以这就是为什么我们要可视化权重,以及它们能提供给我们第一卷积层寻找的东西的原因。
所以神经网络的第一层总是卷积层,无论你何时观察图像或思考图像数据,还是训练卷积神经网络,通常都会把卷积层放在第一层。
Q:是否可以在神经网络开放的中间层进行同样的可视化?这是接下来要做的事。
如果我们对中间的卷积层做相同的可视化,虽然它做的工作是相同的可视化,但实际上它的可解释性会差很多,所以切记使用在课程网站上运行的小型的卷积演示网络,无论你在什么时候登录这个网站,这个神经网络的第一层都是7*7的卷积和16个卷积核,网络第一层权重的可视化,就像我们之前一页见到的。第二层的权重经过卷积之后,这里有一些ReLU激活函数和一些其他的非线性激活函数。但是第二个卷积层接收了16个频道的输入,并且使用20个卷积核进行7*7的卷积,所以问题是你不能直接将这些图像可视化,但是你可以尝试一下下面这个方法,因为输入图像的深度是16维的,并且我们有卷积核,每个卷积核的形状是16*7*7,并且沿着整个深度延伸,然后我们有20个相同的卷积核用来产生下一层的输出平面,但问题是我们并不能从卷积核权重里面得到太多的信息。
这里的做法是,对于单一的16*7*7的卷积核,我们可以把16*7*7的卷积核平面展开成16*7*7的灰度图像,这就是我们所做的这些小灰度图像,显示了第二层某个卷积核的权重。因为这层有20个输出,然后第二个卷积层拥有20个形状为16*7*7的卷积核。如果我们把那些卷积核的权重看做图像,那么可以发现这里有一些空间结构,但是它并不会给你直观的感觉,因为这些卷积核并没有直接连接到输入图像。
回想一下,第二层的卷积核与第一层的输出相连接,所以这让我们认识到,在第一次卷积后,什么类型的激活模式会使第二个激活层的卷积的激活最大化,但是这并不是可以解释的,因为我们并不知道那些第一层的卷积在图像像素上呈现出的样子是什么样的。所以我们需要开发一些更奇特的方法来明白在中间层到底发生了什么。
在之前的幻灯片中,对于所有的可视化,把权值设定在
0-255这个区间内。实际上那些权值可以是无限的(任意的),它们可以在任意范围之内,但是为了得到比较好的可视化效果,并且没有限定权值范围的可视化也没有考虑到这些层的偏置,所以我们需要对它们进行缩放,所以你们应该要记住模型可视化的恰当的时机。
 可视化更高层卷积核的权重(来自cs231n)
可视化更高层卷积核的权重(来自cs231n)
现在我们来讨论模型的最后一层。
记住在卷积网络的的最后一层,我们通过大概1000个类的得分,来告诉我们数据集中每个类的得分。而且在最后一层之前,我们通常有一些完全连接的层,以AlexNet为例。
我们用4096维的特征向量来表示我们的图像,然后将其输入到最后一层,来预测最终类的得分。另一种用来解决可视化和理解卷积神经网络的方式是,尝试去理解在神经网络的最后一层到底发生了什么,我们可以做的是,通过我们训练的卷积神经网络提取一些数据集来检测一些图像,并且为每一个图像标记对应的4096维的向量,并试着可视化最后一个隐层,而不是卷积神经网络的第一层。
 可视化最后一层卷积核的权重(来自cs231n)
可视化最后一层卷积核的权重(来自cs231n)
所以,你可能会想着尝试使用近邻法,记住在第二讲中,我们看到在左边的图片中有一个近邻分类器。在CIFAR 10的图像中,我们根据像素空间来寻找近邻。当你观察CIFAR 10图像里近邻之间的像素空间,你会发现,你打开的图像和查询的图像看起来非常相似。所以再强调一遍,左边的一列是在CIFAR 10数据集中的图像,接下来的5列图像是在那些测试图像集中与行首图像像素空间的近邻。
 可视化最后一层卷积核的权重(来自cs231n)
可视化最后一层卷积核的权重(来自cs231n)
举个例子,你看到的这只白色的狗,与这只白色的狗在像素空间上是近邻关系的,是这些具有白色斑点的东西,那可能不是狗,但是至少这些图像的原始像素非常相似,所以我们可以对这些近邻图像做相同类型的可视化计算。
与其根据像素空间来计算近邻,不如在由卷积神经网络计算的4096维的特征空间中计算近邻。在右边的图像中,我们可以看到一些实例,第一列图像来自于图像网络分类数据集的一些实例,后序的列中的图像是在4096维空间中由AlexNet计算的测试集图像的近邻,并且你可以发现,这和根据像素空间确定近似的方法非常的不同,因为图像的像素在它的近邻和特征空间之间是非常不同的。然而这些图像的语义内容在特征空间中是相似的,举个例子,如果你在第二层中要查询的图像,是这只站在图像的左侧,并且有绿草地作为背景的大象,它在图像集中的(排行在第三的)近邻,实际上是一只站在图像右侧的大象,这真的非常有趣。因为在左边的大象和右边的大象之间,它们的像素几乎完全不同。
然而在神经网络学习到的特征空间中,这两个图像彼此之间非常相似,也就是说,特征空间的特性是捕捉这些图像的语义内容,这真的很酷。一般来说,观察这些近邻的可视化结果是非常快速,并且直观地了解这里到底发生了什么的方法。
Q:通过标准的监督学习过程,对分类网络的分类训练来说,能够毫无遗漏地把这些特征紧密地联系在一起。
的确是这样的,这是一个巧合,它们最终会联系在一起,因为我们并没有在训练这些特征时告诉它们应该联系在一起,然而有时人们在训练神经网络时会使用对比损失,或是三元组损失的方法,这些方法实际上可以在神经网络上精确地做出预测和约束,这些特征最终得到了在度量空间上的解释,但AlexNet至少没有专门为此训练。
Q:图像的近邻需要做什么?
我们把这个图像通过神经网络运行,比如在神经网络的最后一个隐层,就是通过4096维的向量运行。因为在神经网络的末端有完全连接层,所以我们在做的是写出每个图像的4096维向量,然后通过神经网络计算的4096维的向量计算相应的图像近邻。
Q:从另一个角度来观察,最后一层到底发生了什么?
是通过一个叫降维的概念,上过CS229课程的同学可能见过类似PCA的东西,可以让你把像4096维的特征向量的高维表示压缩到二维空间,以便让你更加直观地可视化这个特征空间。
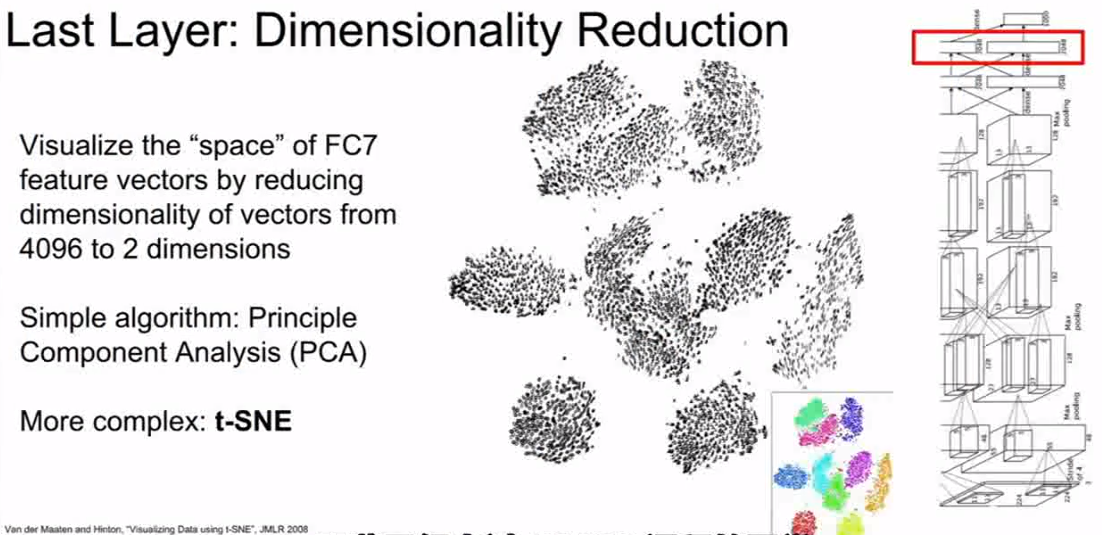 可视化最后一层卷积核的权重(另一个角度)(来自cs231n)
可视化最后一层卷积核的权重(另一个角度)(来自cs231n)
所以,主成分分析(也就是PCA)是一种降维的方法,但是还有一种真正强大的算法,叫t-SNE,也就是t-分布邻域嵌入的缩写。这是一个更强大的方法,t-SNE是一种人们经常在深度学习中可视化特征的非线性降维方法。
这是t-SNE的一个应用实例。这里的可视化显示了mnist数据集上的t-SNE降维,mnist是由手写的0到9之间的手写数字构成的数据集,每个图像都是28*28的灰度图像,现在我们使用t-SNE把28*28维的原始像素特征空间作为mnist,现在把它压缩到2维,在这个压缩的二维表示中,可视化每个mnist数据,当你对原始像素和mnist数据集使用t-SNE降维法,你可以看到这些自然集群的出现,这些集群对应了mnist数据集中的数据,所以现在我们可以做相同类型的可视化工作,也就是在我们训练的图像网络分类器最后一层的特征上应用这个t-SNE降维技术。
更具体一点地说,我们在这里做的工作是提取大量的图像,并且让它们在卷积神经网络上运行。我们记录了每个图像在最后一层的4096维的特征向量,而且4096维的特征向量数目非常庞大,现在我们通过t-SNE降维的方法,把4096维的特征空间压缩到2维特征空间,现在我们在压缩后的2维特征空间中布局网络,并且观察这个2维特征空间中,网格中每个位置会出现什么类型的图像。
 可视化最后一层卷积核的权重(另一个角度)(来自cs231n)
可视化最后一层卷积核的权重(另一个角度)(来自cs231n)
通过这种做法,你可以粗略地感觉到,这个学习到的特征空间的几何结构应该是什么样子的,这些图像很难被肉眼观察到。
基本的想法是,假设我们有一张图像,并且我们得到了关于这张图像的三个不同的信息,其中包括图像的像素、图像对应的4096维的向量,然后我们使用t-SNE降维,把4096维的向量转换成2维向量,然后我们取图像的原始像素,把它们放在二维坐标上,对应于4096维特征向量的降维版本。
Q:二维特征向量可以解释多少变量?
讲师不确定确切的数字,因为当谈论到t-SNE,讲师也会感到有些混乱。因为它是非线性的降维法。
Q:是否可以在神经网络的上层进行相同的分析?
当然可以,但是在这里并没有进行可视化。
Q:在我们降维时是否会造成图像的重叠?
是的,当然会。这就像在规则的网格中提取图像像素的近邻,然后选择比较接近网格点的图像。这不是表示特征空间不同部分的密度,而是更多的关于这个特征空间特性的可视化。
针对这些中间层的特征,你可以做的另一件事是,我们在之前的幻灯片中讨论过,可视化中间层权重的解释性并不是那么强,但实际上可视化中间层的激活映射图在某些情况下是具备可解释性的。
再次将AlexNet作为例子,AlexNet的卷积层给我们提供了形状为128*13*13维的张量,我们可以这样想,作为128个不同的形状为13*13的二维网格,我们实际上可以把特征映射图的每13*13个元素可视化为灰度图像,这让我们意识到,卷积神经网络层要寻找的特征在输入中是什么类型的。
 可视化激活图(另一个角度)(来自cs231n)
可视化激活图(另一个角度)(来自cs231n)
对于可视化中间层特征,我们可以做的另一件非常有用的事情是,可视化输入图像中什么类型的图像块可以最大限度地激活不同的特征,不同的神经元。
我们这里的做法是,选取AlexNet的卷积层,记住AlexNet卷积层的每一个激活量,给我们提供了128*13*13的三维数据,然后我们选择128个通道其中的一个,也许是17号通道,现在我们将要做的是,通过卷积神经网络运行很多的图像,对于每一个图像记录它们的卷积特征,然后我们可以观察到,那个特征映射图的部分已经被我们图像的数据集最大地激活,因为这是卷积层,卷积层中的每个神经元在输入部分都有一些小的感受野,每个神经元的管辖部分并不是整个图像,它们只针对于这个图像的子集合,然后我们要做的是,从这个庞大的图像数据集中可视化来自该特定层、特定特征的最大激活的图像块,然后我们可以根据这些激活块,在特定层的激活程度来解决这个问题。这是一些来自激活特定神经元的输入图像块的实例,神经网络的本身并不重要,这些是最大化激活图像块的可视化,我们从神经网络的每一层选择一个神经元,根据从大型数据集中提取的图像,对这些神经元进行排序,这会使这个神经元被最大程度地激活,这些可以让你了解这些神经元可能在寻找什么特征。
 最大限度地激活不同的特征,不同的神经元(另一个角度)(来自cs231n)
最大限度地激活不同的特征,不同的神经元(另一个角度)(来自cs231n)
举个例子,在第一行,我们在图像中看到很多种类的东西,大部分是眼睛,也包括这个蓝色的圆形区域。然后这个神经网络在特定层的特定神经元寻找的特征,可能是输入图像中蓝色的圆形物体,或者是在中间的特征。我们有寻找不同颜色文本的神经元,或是不同颜色和方向的弯曲边缘。这里说的一个神经元,是卷积激活映射图的一个缩放值。但是因为是卷积的,所以一个通道内的所有神经元共享相同的权重。已经选取了一个通道,对于任意一层的所有卷积核,你会得到大量的神经元,由于事物的卷积性质,这些图像块可以从这个图像的任何地方被绘制出来。并且在图像底部我们可以看到,相同神经网络较高层的一些被最大程度激活的神经元的图像块,因为它们来自神经网络的较高层,所以它们具有更广阔的感受野,它们可以感受到输入图像的更大的图像块,并且我们可以发现它们在寻找输入图像中较大的结构。第二排看起来可能是在寻找人或者人脸,其他的一些可能在寻找相机部分或者是更大的不同类型的物体。
另一个我们可以做的实验,是来自于Zeiler and Fergus在2014年ECCV发表的论文,这个实验的想法是排除,我们想做的是,弄清楚究竟是输入图像的哪个部分导致神经网络作出分类的决定。
我们将会把一头大象的图像作为我们的输入图像,我们将在该输入图像中遮挡某个区域的某个部分,然后把它替换成数据集的平均像素值。现在通过神经网络运行被遮挡的图像,然后记录遮挡图像的预测概率。现在将这个遮挡图像块划过输入图像的每个位置,然后重复相同的过程,然后绘制图像的热力图,这张热力图显示了,什么函数作为我们图像遮挡部分的预测概率输出。这个想法是,如果我们遮挡图像的某个部分,并且导致了神经网络分值的急剧变化,那么这个遮挡的输入图像部分可能对分类决策起到非常重要的作用。
这里我们展示了遮挡实验的三个不同实例。对于底部的这个卡丁车实例,你可以看到这里的红色区域对应于低预测概率,白色和黄色的区域对应于高预测概率。当我们遮挡卡丁车图像前面的部分,卡丁车类的预测概率下降了很多,这就让我们意识到输入图像这部分的像素对于神经网络作出分类的决策有重要关系。
 遮挡实验(来自cs231n)
遮挡实验(来自cs231n)
Q:这张图像的背景图的作用是什么?
如果图像太小,以至于不能分辨。但这里实际上还有卡丁车的赛道,并且在背景图里还有一对其他的卡丁车。所以当遮挡背景图中的其他卡丁车,或者那里的地平线,同样也会影响分值。也许地平线对于检测卡丁车来说是个有用的特征,地平线有时会有点难以分辨,但这确实是一个很酷的可视化。
Q:针对这个实例,我们提取一张图像,然后遮挡这个图像的所有部分。
这并不是说你直接提取这些信息,然后直接在训练过程中不断循环。相反这是让人们理解训练神经网络时进行计算的类型的工具,这更多的是为了你们更好地理解,而不是为了提高性能本身。
Q:为什么地平线特征是有用的?
第二个相关的问题是显著图。
 显著图(来自cs231n)
显著图(来自cs231n)
这种情况下我们也有相同的问题,即给出一只狗的输入图像,以及狗的预测类标签,我们想要知道输入图像中的哪部分像素对于分类是重要的。我们发现遮挡是解决这个问题的一种方法,但是显著图是从另一个角度解决这个问题的方法。
几年前,在Karen SImonenian的论文中提到一个比较简单的方法,即计算相对于输入图像像素的预测类别分值,这将直接告诉我,在一阶近似意义上对于输入图像的每个像素,如果我们进行小小的扰动,那么相应类的分类分值会有多大的变化,这是另一种用来解决输入图像的哪个部分的像素用于分类。
当我们通过显著图的方法运行这张小狗的图像,我们很好地看到了图像中小狗的轮廓。这告诉我们神经网络正在寻找的特征可能在这张图像的这些像素之间。
当我们对不同的图像进行相同类型的操作,我们意识到神经网络在寻找合适的区域,这让人感到有些欣慰。
 显著图(来自cs231n)
显著图(来自cs231n)
Q:人们在进行语义分割时,是否也会使用显著图的方法?
答案是肯定的。来自Karen的论文,里面谈到了使用显著图的方法,在没有任何直接标签数据的情况下来进行语义分割。这里他们使用的是Grabcut分割算法,但是对于这个算法的细节,我并不想过多的深入。但是这是一种你可以使用的交互式分割算法,当你把显著图和Grabcut分割算法结合起来,你可以细分出图像中的对象。这种结合有点脆弱,一般来说,这可能会在可以获得监督和训练时间的神经网络上效果非常不好,我不确定它的实用性到底如何,但是它能够起到作用,这真的很酷。它的应用场合可能比明确地训练与监督分割的情况少的多。
 显著图:无监督语义分割(来自cs231n)
显著图:无监督语义分割(来自cs231n)
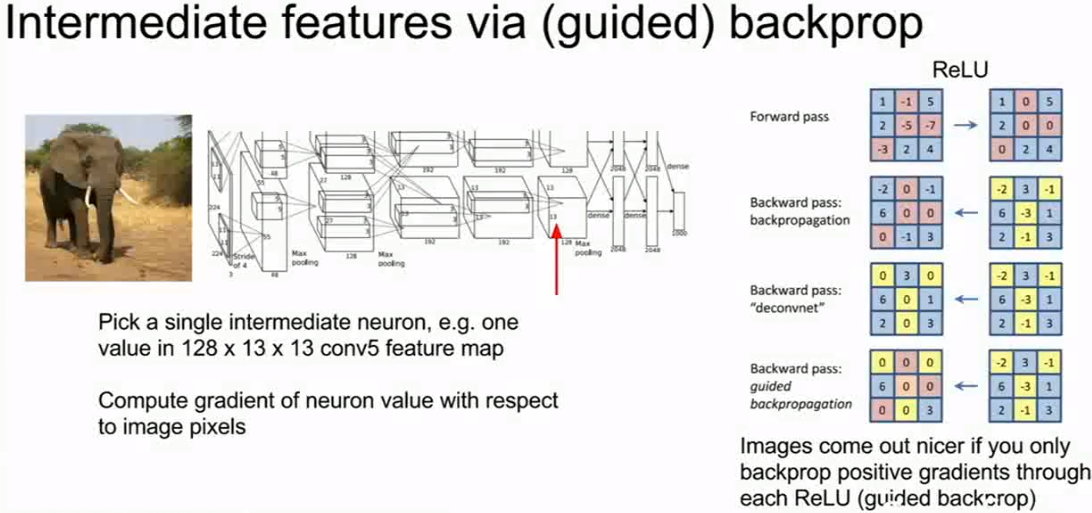
另一个相关的想法是引导式反向传播,对于一个特定的图像,我们仍然想要解决这个问题,而不是看类的分值。
我们想要了解并选取神经网络中间层的一些中间神经元,再次提问,输入图像的哪个部分影响了神经网络内部神经元的分值,那么你可以想像,通过显著图来计算神经元的分值,而不是计算相对于图像像素的类的分值。你可以计算神经网络中某些中间值相对于图像像素的梯度,并且这些梯度会告诉我们,输入图像中的哪些像素会影响特定神经元的值,这将使用正常的反向传播。
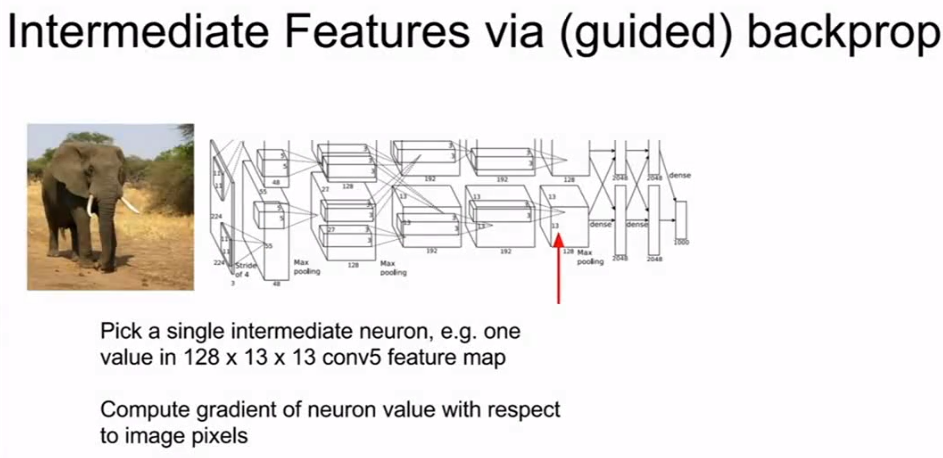 引导式反向传播(来自cs231n)
引导式反向传播(来自cs231n)
但事实证明,我们可以对这个反向传播的过程做一些微调,最终得到一些稍微干净些的图像。所以这就是来自Zeiler和Fergus的2014年论文中的传导式反向传播的思想,这是一项奇怪的调整,通过ReLU非线性激活函数改变了反向传播的方式,但只有通过ReLU激活函数传播正梯度,而不是传播负梯度,所以你不再需要计算正确的梯度,相反你只需要跟踪整个神经网络正面积极的影响,如果你想了解这个好想法的细节,应该阅读这些参考论文。
 引导式反向传播(来自cs231n)
引导式反向传播(来自cs231n)
但从经验上来讲,当你使用引导式反向传播,而不是定期反向传播时,你可能更容易得到更清晰、更好的图像,告诉你输入图像的哪部分像素影响了那个特定的神经元,我们可视化的结果是相同的。我们在之前的幻灯片中看到了最大程度激活的图像块,除了可视化最大程度激活的图像块之外,我们也进行引导式反向传播来告诉我们这些图像块的哪个部分影响了神经元的分值。
 引导式反向传播(来自cs231n)
引导式反向传播(来自cs231n)
请记住顶部这个实例,我们认为这个神经元可能在寻找输入图像块中圆形紧凑的部分,因为这里有大量的圆形紧凑的图像块,当我们把目光转向引导式反向传播,从直觉上来说,我们感觉这个想法是正确的。因为输入图像块中的圆形部分的确影响了神经元的分值,这对图像合成,以及理解这些不同的中间神经元正在寻找什么是十分有用的。
但是,关于引导式反向传播或计算显著量图是一件非常有趣的事情是,总有一个固定输入图像的函数,这个函数告诉我们,对于一个固定输入的图像,输入图像的哪个像素或哪个部分影响了神经元的分值。
Q:如果我们在一些输入图像上移除这种依赖性,而你们可能会问什么类型的输入会激活这个神经元?
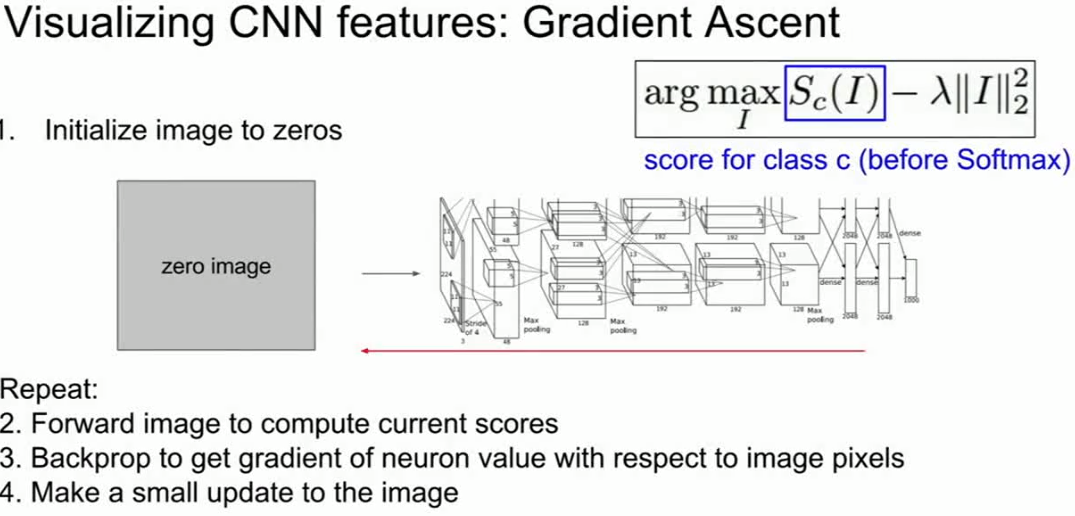
我们可以通过梯度上升算法来解决这个问题。
我们总是在训练卷积神经网络时,使用梯度下降来使函数损失最小化。而现在我们想要修正训练的卷积神经网络的权重,并且在图像的像素上执行梯度上升来合成图像,以尝试和最大化某些中间神经元和类的分值。在执行梯度上升的过程中,我们不再优化神经网络中保持不变的权重,相反我们试图改变一些图像的像素,使这个神经元的值或这个类的分值最大化。
除此之外,我们需要一些正则项,在看到正则项尝试阻止神经网络权重过拟合训练数据之前,我们需要类似的东西来防止我们生成的图像过拟合特定网络的特性,所以这里我们经常会加入一些正则项。我们需要具备两个特定属性的生成图像,第一个属性是我们想要最大程度地激活一些分值或神经元的值,第二个属性是我们希望这个生成图像看起来是自然的,即我们想要生成图像具备在自然图像中的统计数据。这些主观上的正则项是强制生成图像看起来像是自然图像的东西。
 梯度上升算法(来自cs231n)
梯度上升算法(来自cs231n)
接下来,我们将会看到几个不同的正则项实例,一般的策略其实很简单。我们要做的是,把初始图像初始化为0,或是通过添加高斯噪声作为初始输入来进行图像去噪,然后通过3D神经网络重复转发图像,并计算你感兴趣的神经元分值,通过反向传播来计算相对于图像像素神经元分值的梯度,然后对图像像素本身执行一个小的梯度下降或梯度上升更新,以使神经元分值最大化,不断地重复上述的步骤,直到你拥有一个漂亮的图像。
 梯度上升算法(来自cs231n)
梯度上升算法(来自cs231n)
然后,我们讨论了图像正则化。
一个非常普通的图像正则化的想法是,惩罚生成图像的L2范数,这在语义上来说并不是那么有意义,这是我们在文献中看到的最早的生成图像类型论文的正则项之一。当你在训练的神经网络上惩罚生成图像的L2范数,你可以看到现在我们正在尝试最大化左上角哑铃的生成图像分值。这是生成的图像,可能它是有点难以用肉眼看到,这里有许多不同形状的哑铃,各种各样的不同部分的叠加,如果我们尝试去生成杯子的图像,我们可以看到一堆不同的叠加的杯子。这些斑点犬有点酷,因为我们可以看见黑色或是白色的斑点犬品种,那是斑点犬的一些特征。对于柠檬,我们可以在图像中看到不同的斑点。
 梯度上升算法(来自cs231n)
梯度上升算法(来自cs231n)
Q:为什么这些彩虹是彩色的?
通常来说,可视化获得真实的颜色是非常棘手的。因为任何实图的像素值都会被限定在0到255之间,它实际上是约束优化问题,但如果对梯度上升问题使用通用的方法,这将演变成无约束的问题,你可以使用投射梯度上升算法,或者在最后重新缩放图像,你在可视化中看到的颜色有时候不能太把它们当真。
我们看到,这里有很多的多模态以及相应的方法解决多模态问题,实际上我们会看到这是改善整个可视化工作的第一步。
解决这个问题的另一个角度是,通过改善正则化来改善可视化图像,在Jason Yesenski和他的一些合作者的另一篇论文中,他们增加了一些令人印象深刻的正则化。除了L2范数约束之外,我们还定期在优化过程中对图像进行高斯模糊处理;我们同时也将一些低梯度的小的像素值修改为0,可以看到这是一个投射梯度上升算法,我们定期投射具备良好属性的生成图像到更好的图像集中。
举个例子,进行高斯模糊处理后,图像获得的特殊平滑性,所以对图像进行高斯模糊处理后,更容易获得清晰的图像。现在这些火烈鸟、黑天鹅都显得更加逼真,这些台球实际上看起来令人印象深刻,现在你可以看到台球桌的结构,一旦你加入更好的正则化方法,生成图像会一点点变得更加清晰。现在我们可以不仅对类的最后分值执行这个程序,也可以对中间神经元。
举个例子,我们可以对最大化某个中间层的其中一个神经元的分值,而不是最大化台球桌的分值。
 梯度上升算法(来自cs231n)
梯度上升算法(来自cs231n)
Q:这里的几个例子是什么?
回顾前面讨论过的图像随机初始化,这四个图像是输入图像的4个不同的随机初始化图像。
我们可以使用这些相同的程序来可视化以及合成图像,即最大限度激活神经网络的中间神经元,然后你就可以了解到这些中间神经元寻找的东西是什么,也许神经网络第四层的神经元在寻找螺旋状的东西,或者在寻找体型较大的毛毛虫,这有点难以分辨。但一般来说,当你把图片放的越大,神经元的感受野范围也会越大,所以使用者应该寻找图像中较大的图像块。神经元则倾向于寻找图像当中更大的结构或更复杂的类型。
 梯度上升算法(来自cs231n)
梯度上升算法(来自cs231n)
人们对改善可视化效果非常狂热,他们基本上通过保留额外的特征来改善可视化效果。
这是一个针对性解决多模态问题的论文。在这篇论文中尝试在优化的过程中考虑多模态问题,即对每一个类运行聚类算法,以使这些类分成不同的模型,然后用接近这些模型其中之一的类进行初始化,那么当你这样做的时候,你就可能考虑多模态形式,从直觉上来说,右边的八个图像都是杂货商店,虽然最上面的一排是货架上产品的特写,但是同样被标记为杂货商店,而且最下面一排的图像是在杂货店附近行走的或是在排队结账的人们,诸如此类。
同样它们也被标记成杂货商店,可是它们的视觉呈现是截然不同的,很多这些类最终都是排序类型的多模态,如果你在生成图像时把这些多模态的问题考虑进去,你将得到更好的图像。当你观察类的生成图像,你可以看到像甜椒、草莓之类的非常漂亮的生成图像。
可以添加更加强大的先验图像,然后生成非常漂亮的图像。这些生成图像都是通过最大化一些图像类的分值得到的,一般的想法是尝试优化图像在FC6潜在空间中的表示,而不是直接优化输入图像的像素,它们需要使用特征反演网络,具体可以阅读论文来了解。
 梯度上升算法(来自cs231n)
梯度上升算法(来自cs231n)
重点是,当你开始在自然图像建模时添加先验图像,你最终可以得到一些非常真实的图像,它们让你了解到神经网络究竟在寻找什么特征。这是一件我们可以用这个策略做的事情,但通过图像像素的梯度来合成图像的想法实际上非常强大。
针对这个,另一件我们可以做的非常酷的事情是愚弄图像,即选取一些任意的图像。比如我们提取一张大象的图像,然后我们告诉神经网络,我们想要最大化这张图像中考拉熊的分值,然后我们要做的是改变这个大象的形象,让神经网络将它归类为考拉熊,你可能希望的是也许这头大象更像一只考拉熊,以及它会长出一对可爱的耳朵。但是这不是在实际中发生的事,因为这太让人惊讶了。
 愚弄图像(来自cs231n)
愚弄图像(来自cs231n)
如果你提取这张大象的图像,然后告诉神经网络它是考拉熊,并且尝试改变大象的图像,使得它被神经网络归类为考拉熊,你将会发现右边的第二幅图像实际上被归类为考拉熊,但是它在我们看来和左边第一幅图一样,那是非常令人惊讶的。同样在底部,我们看到了一艘帆船的图像,帆船是这个类的形象,然后我们告诉神经网络将其归类为iPod,第二个实例在我们看来依旧和第一列第二个图像是一样的,但是神经网络认为这是一个iPod,这两个图像之间在像素上是没有差异的,如果你放大这些差异,并不会真的在这些差异中看到IPod或考拉熊的特征,它们就像随机的噪声模式。
这就是对抗样本的原理。
 对抗样本(来自cs231n)
对抗样本(来自cs231n)