损失函数和优化
引言
上节课只是讲了线性分类器的思想,还没讲怎么选择W,怎么使用训练数据来得到W的最优取值。对于W的某个取值,我们可以用这个W得到任意图片的10个分类的得分,有些分类得分更高,有的更低。
这里有一个简单的例子,这里是一个只有3张图片的训练集,然后用某个W预测这些图片的所有共10个类别的得分,可以看到有些分高,有些分低一点。
如果我们看一下猫这个类别的得分,这个W设置下的分类器,对这种图属于猫这个分类的得分是2.9,然而属于青蛙分类的得分是3.78,可能这个分类器对这张图不是很有效,得分应该是最高的。对于其他类,可以看到车这个类别的得分是6,比起其他类别都要高,这就很好。第三张图在青蛙这个分类里的得分是-4,比其他都很低,这就很糟糕了。
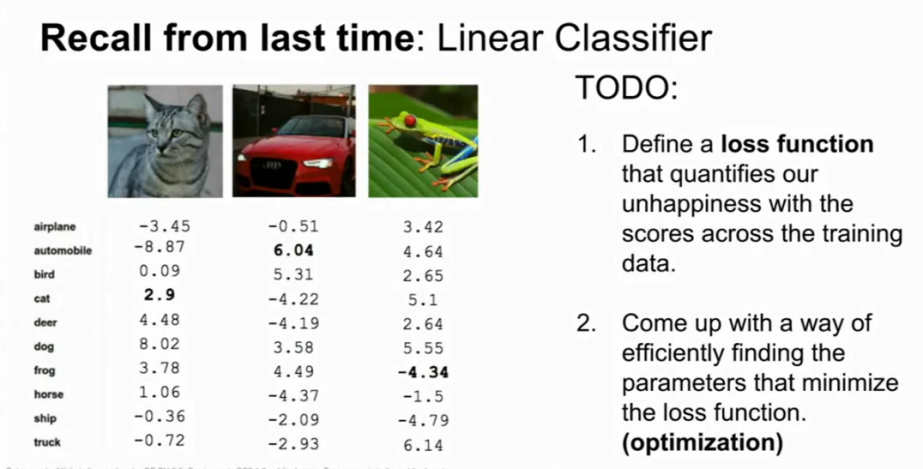 图片在线性分类器下不同类别的得分(来自cs231n)
图片在线性分类器下不同类别的得分(来自cs231n)
损失函数
上面这是手动的方法,用人眼看一下这些分数,哪些是好的,哪些是坏的。但如果为这些写一个算法,自动决定哪些W是最优的,就需要一个度量任意某个W的好坏的方法,可以用一个函数把W当做输入,然后看一下得分,定量地估计W的好坏,这个函数被称为损失函数。这节课我们会看到几个例子,比如对图像分类问题可以选择几种不同的损失函数,
 线性分类器的损失函数(来自cs231n)
线性分类器的损失函数(来自cs231n)
正式一点来说,一般所谓的损失函数,比方说,有一些训练数据集x和y,通常我们说有N个样本,其中x是算法的输入,在图片分类问题里,X其实是图片每个像素点所构成的数据集,y是你希望算法预测出来的东西,通常称之为标签,在图片分类问题里,要记住我们是在尝试把CIFAR-10中的每个图片分类到10个类中的1个里面,所以标签y是一个在1到10之间的整数,或者0-9也一样。这个整数表明对每个图片x哪个类是正确的。
我们把损失函数记作L_i,我们有了关于x的预测函数之后,这个函数就是通过样本x和权重矩阵W给出y的预测,在图片分类问题中,就是给出10个数字中的一个。我们可以给出一个损失函数L_i的定义,通过函数f给出预测的分数和真实的目标,或者说标签y,可以定量地描述训练样本预测的好不好,最终的损失函数L是在整个数据集中N个样本的损失函数的总和的平均。这是一个通用的公式,可以拓展到图片分类以外的问题,对于任何问题这可以说是一个通用的设置,有了x和y你想要用某个损失函数定量的描述出参数W是否令人满意,然后在所有的W中找到在训练集上损失函数极小化的W。
我们要看的是对单个例子的损失函数L_i,我们的计算方式除了真实的分类Y_i以外,对所有的分类Y都做加和,也就是说我们在所有错误的分类上作和,比较正确分类的分数和错误分类的分数,如果正确分类的分数比错误分类的分数高,比错误分类的分数高出某个安全的边距,我们把这个边际设为1。如果真实的分数很高,或者说真实分类的分数比其他任何错误分类的分数都要高很多,那么损失为0。接下来把图片对每个错误分类的损失加起来,就可以得到数据集中这个样本的最终损失。然后还是一样的对整个训练集取平均。
多分类SVM loss
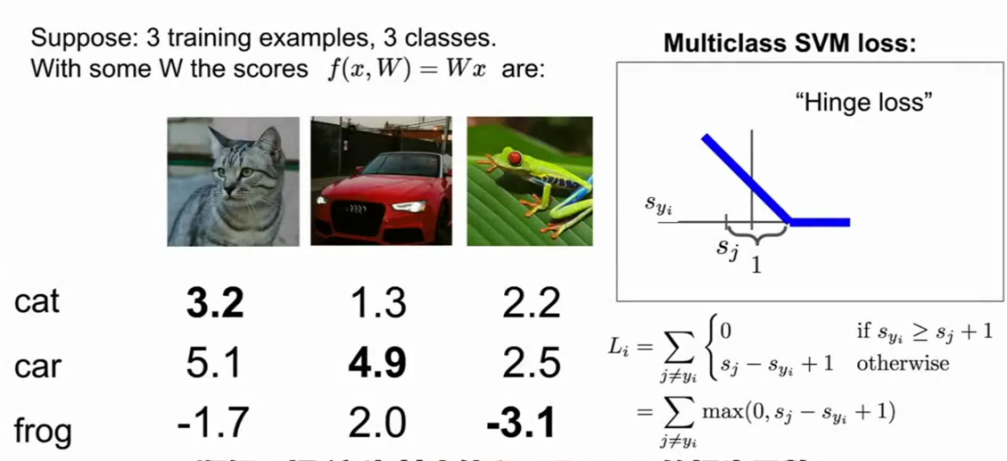 SVM分类器的损失函数(合页损失函数,来自cs231n)
SVM分类器的损失函数(合页损失函数,来自cs231n)
上图中S yi是真实的分数,S j是损失,可以看到随着真实分类的分数的提升,损失会线性下降,一直到分数超过了一个阈值,损失函数就会是0。因为我们已经为这个样本成功地分对了类。
S是通过分类器预测出来的类的分数,如果一个是猫类,一个是狗类,那么S1和S2分别就是猫和狗的分数,Y_i这个整数表示这个样本的正确的分类标签,S_Y_i代表了训练集的第i个样本的真实分类的分数。 这个式子到底在算什么?这个损失是在说如果真实分类的分数比其他的分数高很多,那我们会满意,一般需要高出一个安全的边距,如果真实分类的分数还不够比其他分类高出那么多,那么我们会得到一些损失,这样是不好的情况。
下面对刚刚那个迷你数据集来具体地算一算。
把分情况讨论的记号换成了刚刚的0-1记号,
 SVM分类器的损失函数计算某一个损失项(来自cs231n)
SVM分类器的损失函数计算某一个损失项(来自cs231n)
如果我们对第一个训练样本计算多分类SVM损失函数,左边要记住我们要对所有不正确的分类全都循环一遍,那么这个分类来看,猫是正确的分类,所以我们要对汽车和青蛙类都要做一遍运算。上述例子中的2.9是我们的分类器对于这一个训练样例训练得多好的一个量化衡量指标。
思考下,这是多分类的损失函数,对于回归来说,损失函数又是怎么样的?这个分数是怎么得来的?
最终我们对于整个训练数据集的损失函数是这些不同的样例的损失函数的平均值。所以当你相加这些损失函数并且求平均值后得到了5.3。这在一定程度上量化的反映了我们的分类器在数据集上有多不好。
 SVM分类器的损失函数计算得到的损失(来自cs231n)
SVM分类器的损失函数计算得到的损失(来自cs231n)
为什么要选择加1?
这其实在一定程度上是一个任意的选择,这实际上就是一个出现在损失函数中的常数,因为我们并不关心损失函数中分数的绝对值,我们只关心这些分数的相对差值,我们只需要正确分类的分数要远远大于不正确分类的分数,所以实际上如果你把你的整个W参数放大或缩小,那么所有的分数都会相应地放大或缩小,最终1这种自由参数会在这种放缩操作中被消去,就像对于整个参数W的放缩一样。
问一些不同的问题对于直观地理解损失函数如何运行很有帮助。
第一个问题是,如果我们稍微改变了汽车的分数,损失函数会发生什么变化吗?不会
因为这里只关注分数比,只要汽车分数是最高的,只是稍微改变了一丢丢,那么1的界限依然奏效,损失函数并不会改变,我们依然得到为0的损失函数。
另一个问题,
SVM损失函数的可能的最大/最小值可能是多少?
损失函数的最小值是0,因为你可以想象所有的分类,如果我们的正确分数非常大,那么我们会得到所有分类的损失函数为0,那么损失函数就为0。
最小值是0,最大值是无穷大。
另一个问题,当你初始化这些参数,并且开始从头训练,通常你先使用一些很小的随机值来初始化
W,你的分数的结果在训练的初期倾向于呈现较小的均匀分布的值,并且问题在于如果你所有的S,也就是你所有的分数都近乎为0,并且差不多相等,那么当你使用多分类SVM时,损失函数预计会是如何呢?分类的数量减去1
因为如果我们对所有不正确的类别遍历了一遍,实际上遍历了C-1个类别,在这些类别中的每一个,这两个分数差不多相同,所以我们就会得到一个值为1的损失项。因为存在着1的边界,我们将会得到C-1。这是一个有用的调试策略,当你使用这些方法的时候,当你刚开始训练得时候,你应该想到你预期的损失函数该是多大。如果在刚开始训练的时候你的损失函数在第一次迭代的时候损失函数并不等于C-1,这意味着你的程序可能有一个Bug,你得去检查一下你的代码,所以这实际上在实际应用中是一个有用的结论。
另一个问题,如果我们将对于SVM的所有错误的分数求和会发生什么,如果我们将所有正确的分数求和会发生什么,如果我们将所有的都求和呢?损失函数会加1
实际应用中这么做的原因是,通常损失函数为0的时候说明算法很好,所以你没有损失什么,这就很好了,就不会再去寻求同样的分类器了,如果你实际上求和遍历了所有的类别,但是我们忽略了正确的类别,那么我们的最小损失函数为0。
另一个问题,如果我们使用平均值而不是求和呢?不会改变
所以分类的数量需要提前确定,当我们选择数据集的时候,因为这只是将整个损失函数缩小了一个倍数,所以这并没有什么影响,任何缩放操作都不会有什么影响。因为我们实际上并不在意真正的分数值,或者是损失函数的真实值。
如果在损失函数中的
max上加一个平方,这还会是同一个问题吗?或者说这会成为另一个不同的分类算法吗?会变得不同
这里用了一种非线性的方法改变了在好和坏之间的权衡,实际上我们计算了另一种损失函数。关于合页损失函数的平方项的想法有时候确实会在实际中应用,这是另一个技巧,当你针对你自己的问题,构成你自己的损失函数的时候。
为什么要用平方项损失函数?放大错误
损失函数就是这样,你告诉你的算法是什么类型的错误,你关心什么类型的错误,他应该折中,取决于你的应用。
 SVM分类器的损失函数代码示例(来自cs231n)
SVM分类器的损失函数代码示例(来自cs231n)
正则化
关于损失函数的另一个问题,
假设你很幸运找到一个
W损失值为0,你根本不会失去。但是有一个问题,具备损失值为0的W到底是不是唯一的?不是唯一的,还有其他的
 Loss==0, is W unique?(来自cs231n)
Loss==0, is W unique?(来自cs231n)
关于把整个问题扩大或缩小的问题,取决于W,可以拿W乘以2,这个两倍的W也将实现零损失。
如果损失函数是要告诉我们的分类器哪个W是我们想要的,哪个W我们是关心的,那么问题来了,分类器到底如何在这些都是0值的损失函数间做出选择呢?
我们所做的只是在数据方面的损失,我们仅仅是告诉分类器,它需要尝试找到可以拟合训练集的W,但实际上我们并不关心和训练集的拟合度,而是关心和测试集的拟合度。所以只是告诉分类器拟合训练集的话,你会发现分类器可能会行为反常。
在这里我们要为损失函数添加一个附加的项,除了数据丢失之外,除了高数分类器,需要拟合训练集之外,我们通常会添加一个项到损失函数里。这个项成为正则项,鼓励模型以某种方式选择更简单的W,这里所谓的简约取决于任务的规模和模型的种类,这实际上也体现了奥卡姆剃刀的理念,也就是科学发现最基本的思想就是要让一个理论的应用更广泛,也就是说,如果你有许多个可以解释你观察结果的假设,一般来讲,你应该选择最简约的,因为这样可以在未来将其用于解释新的观察结果。我们运用这种直觉的方式,基于这一思想并运用于机器学习中,我们会直接假设正则化惩罚项,通常记为R。这样一来标准损失函数就有了两个项:数据丢失项和正则项,这里有一些超参数,用来平衡这两个项,这个参数在实践应用中需要调整。
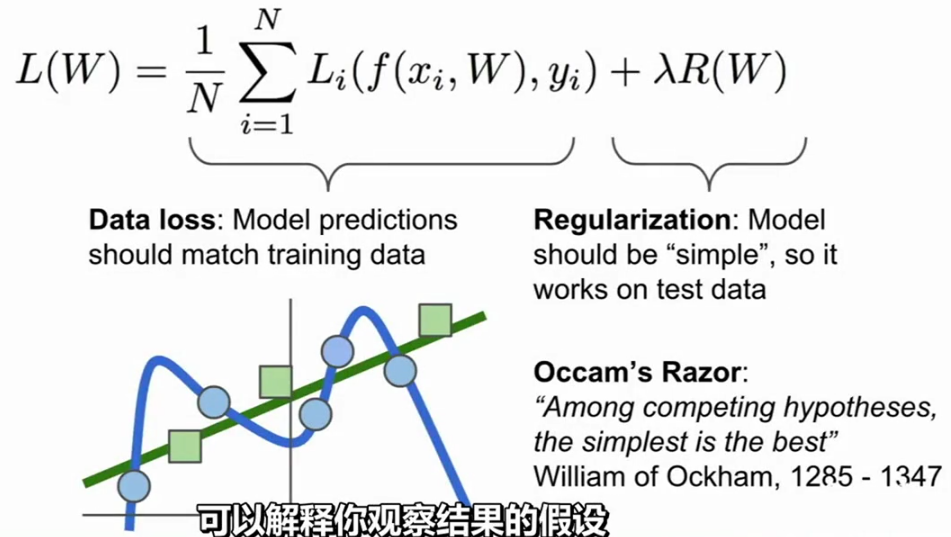 为损失函数添加一个附加的项(来自cs231n)
为损失函数添加一个附加的项(来自cs231n)
什么让一条弯弯的曲线变成了一条直直的绿线?
实际上有很多不同类型的正在实践中使用的正则化,
 不同类型的正则化(来自cs231n)
不同类型的正则化(来自cs231n)
正则化的宏观理念是,你对你模型做的任何事情,也就是种种所谓的惩罚,主要目的是为了减轻模型的复杂度,而不是去试图拟合数据。
L2正则化
L2正则化如何度量复杂性的模型?
假设我们这里有一些训练的样本x,有两个不同的W我们正在考虑,这里X是一个包含四个1作为元素的四维向量,对于W我们来考虑两种不同的可能性。
第一种情形是W首元素是1,另外三个元素都是0,另一种情形W的每个元素都是0.25。
当我们进行线性分类时,我们真正讨论的是x与w的点乘结果,在线性分类的语境下,两种w其实是一样的,因为点乘结果是一样的,那么哪种情形下的L2回归性会好一些?
0.25的,因为它具有比较小的范数
L2回归可以用一种相对粗糙的方式去度量分类器的复杂性
需要记住的是在线性分类器中,W所反映的是x向量的值在多大程度上对输出有影响。
所以L2正则化的作用是它更加能够传递出x中不同元素值得影响,它的鲁棒性可能会更好。当你输入的x存在变化的时候,我们的判断会铺展开来,并主要取决于x向量的整体情况,而不是取决于x向量中某个特定元素。
L1正则化
L1正则化具有完全相反的解释,如果采用L1正则化,我们更加倾向于首元素为1,其他为0的w,因为L1正则化对复杂性具有不同的概念,即那个模型可能具有较小的复杂度,有可能在权重向量中我们用数字0来描述模型的复杂度。L1更喜欢稀疏的向量,它倾向于让你大部分的W元素接近0,少量元素可以除外。
L1更多考虑的是非0元素的个数,而L2更多考虑的是W整体分布所有元素具有较小的分布,所以这取决于你的数据以及具体的问题。
所以如何度量复杂度视不同的问题而定,针对你特殊的模型和数据及不同的设置,你需要思考在该任务中,复杂度应该如何度量。
softmax loss
可以想到不同类型的损失函数
另一个非常流行的选择,除了多类别SVM损失函数之外,深度学习中另外一个流行的选择是多项Logistic回归或者叫softmax loss。
 softmax损失函数(来自cs231n)
softmax损失函数(来自cs231n)
 softmax损失函数计算(来自cs231n)
softmax损失函数计算(来自cs231n)
 softmax .vs. svm(来自cs231n)
softmax .vs. svm(来自cs231n)
我们有一些x和y的数据集,我们使用我们的线性分类器来获得一些分数函数,根据我们的输入x计算我们的分数S。然后我们将使用损失函数也许softmax或SVM或其他损失函数来定量计算我们的预测有多糟糕。Y这个比较真实的目标,然后我们经常会增加这个损失函数一个正则化的术语试图在训练数据之间进行权衡并喜欢更简单的模型,所以这是一个非常通用的概述。很多我们称之为监督学习的东西。随着我们的前进,我们将在深入的学习中看到,通常你会想要指定一些函数f,这在结构上可能非常复杂,指定一些确定的损失函数,你的算法做的如何,给定参数的任何值,一些正则化的术语,如何惩罚模型的复杂性,然后你把这些东西结合在一起,并试图找到W,这最小化了这个最终的损失函数。
但问题是,我们如何才能真正发现这个W使损失最小化,这就是优化了。
 简要回顾loss损失(来自cs231n)
简要回顾loss损失(来自cs231n)
优化
有了损失函数以后,就可以定量地衡量任意一个W到底是好是坏,我们要找一种有效的方式来从W的可行域里找到W取什么值是最不坏的情况,这个过程会是一个优化过程。
当我们做优化,我们通常在步行方面考虑事情,围绕着一些大的山谷,所以这个想法是你在这个大山谷里散步,有不同的山川、山谷和溪流和东西,以及这个景观的每一点,对应于参数W的一些设置。而你就是这个在山谷里散步的小家伙,你正在努力寻找以及每个点的高度,等于这个设定W所带来的损失。现在这个小个子的工作走在这个风景,你需要以某种方式找到这个山谷的底部。总的来说,这是一个棘手的问题。你可能会想你很聪明,可以真正想到分析性质,我的损失函数,我所有的正则化,也许我可以只写下最小化,而且这样会对应魔法传送,一直到这个山谷的底部。
 用山谷来比喻优化(来自cs231n)
用山谷来比喻优化(来自cs231n)
但在实践中,一旦你的预测函数F、你的损失函数和你的正则化,一旦这些事情变得庞大而复杂,并使用神经网络,试图写下来真的没有多少希望,一个明确的分析解决方案直接把你带到最低限度。所以在实践中,我们倾向于从某个解决方案开始,使用多种不同的迭代方法,然后逐步对它进行改进,所以你能想到最傻的事就是随机搜索。你需要很多权重值、随机采样,然后将它们输入损失函数,在看看它们效果如何,这绝对是个很烂的算法。你很可能并不会这样使用,但至少它很有可能会出现在你的脑海里。
随机搜索
 一个坏的方法:随机查找(来自cs231n)
一个坏的方法:随机查找(来自cs231n)
事实上,我们可能这样做,我们通过随机搜索训练一个线性分类器,对CIFAR-10来说,就有10个类别。
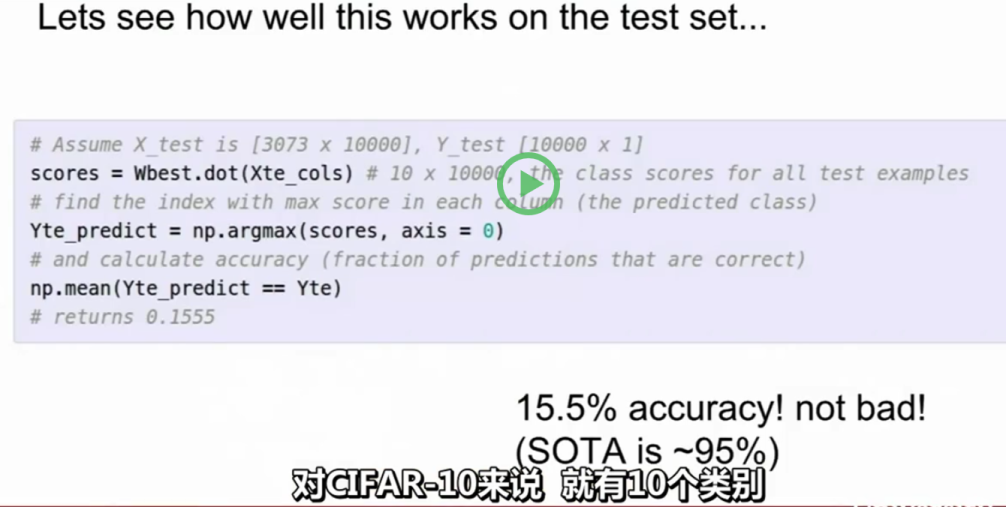 在CIFAR-10上面的效果(来自cs231n)
在CIFAR-10上面的效果(来自cs231n)
所以随机概率就10%,在全凭运气的情况下,通过几次随机试验,我们会得到W值的设定,使精确度达到15%,所以它是好于随机概率的,但最高水平是95%,它们之间还有差距,所以可能也不能使用这种方法,但你可能认为这个方法在实践中是可用的。
梯度下降
利用当地地形形状可能是个好的策略,当你一个人走在这样的地方,你可能不能看到一条直接的线路下到谷底,但你可以凭借脚上的感觉感知当地地形的几何形状。如果我站在这里哪条路可以让我下到山下,你可以凭借脚上的感觉知道哪个方向地面的倾斜是朝向下山的方向,然后你朝那个方向走一步你就下降了一点,然后再次用你的脚找出下山的方向,就这样一次一次的重复,最终希望你能到达谷底,所以这看起来是一个简单的算法,只要你能把每个细节做对,在实践中就能得到很好的结果。所以这正是我们在训练大型神经网络、线性分类器和其他东西时普遍使用的方法。这只是一个简短的说明。
那什么是斜率?如果你还记得微积分,至少在一维上斜率就是函数的导数,所以如果我们有一个一维函数f,它将X作为标量,输出为曲线的高度,我们就能计算出任何想象中的一点的斜率。如果我们向任何方向前进一步h,然后比较这一步前后函数值的差别,然后将步长趋近于0的时候,我们就能得到那一点上函数的斜率。
而且很容易将它推广到多元函数,所以在实际使用时,x可能并不是标量,而是整个向量。记住,x可能是整个向量,所以我们需要有多元(多参数)这个概念。在多元情况下生成的导数就叫梯度。所以梯度就是偏导数组成的向量,梯度有和x一样的形状,梯度中的每个元素可以告诉我们相关方向上函数f的斜率。正是梯度有这样优秀的特性,所以梯度就成为偏导数的向量,它指向函数增加最快的方向,相应地,负梯度方向就指向了函数下降最快的方向。概括起来,如果你想知道这个地形任意方向的斜率,它就等于这一点上梯度和该点单位方向向量的点积。所以梯度非常重要,因为它给出了函数在当前点的一阶线性逼近,所以在实践中深度学习都是在计算函数的梯度,然后用这些梯度迭代更新你的参数向量。
 1维函数的导数(来自cs231n)
1维函数的导数(来自cs231n)
有限差分法
在计算机上,计算梯度的一个简单的方法是有限差分法,这又回到了梯度的极限定义,在左边我们设想当前的W是这个向量参数,它给了我们当前的损失可能是1.25,我们的目标是计算梯度dW,它是和W相同维数的向量,梯度中每个元素都会告诉我们在相关方向上每移动一小步损失变化多少。所以你可能会猜想计算有限差分只是将W的第一个元素累加一个很小的值h,然后用我们的损失函数重新计算损失值,以及我们的分类器和所有这些。在这个设置中如果我们在第一维做微小的改变,损失值将从1.2534降低为1.25322,然后我们可以使用这个有限差分在梯度的第一维实现有限差分逼近。
 计算梯度:有限差分法-改变第一维(来自cs231n)
计算梯度:有限差分法-改变第一维(来自cs231n)
现在你可以想象重新将第一维的值恢复为原值,在第二维重复这样的过程,在第二维方向上增加一小步,计算损失使用有限差分逼近,在第二个位置计算出梯度的近似值。
 计算梯度:有限差分法-改变第二维(来自cs231n)
计算梯度:有限差分法-改变第二维(来自cs231n)
再在第三个位置计算,如此反复,
 计算梯度:有限差分法-改变第n维(来自cs231n)
计算梯度:有限差分法-改变第n维(来自cs231n)
事实上这是一个很可怕的想法,因为它非常慢。你可以想象,如果这个卷积神经网络非常大,计算这个函数f会很慢,这个参数向量W,可能并不是像这里一样有10个输入,而是以千万计,在一些复杂的深度学习模型中,甚至是以亿计,所以在实际使用中你绝不会想计算梯度的有限差分,可能你会等待上亿次的函数估计来得到一个梯度,而且非常慢,结果也并不好。
使用微积分,计算分析梯度下降
幸运的是你并不需要这样做,庆幸你曾经学过微积分课程,我们只需要写下损失的表达式,然后使用微积分,只需要写下梯度的表达式,比起使用有限差分法对它进行计算分析,这将很有效率。第一,它非常精确;第二,因为我们只需要计算一个表达式,所以它会很快。
 损失仅是权重W的函数(来自cs231n)
损失仅是权重W的函数(来自cs231n)
现在如果我们回到当前的W这张图,它看起来是这样的,与迭代计算所有W维度不同。我们提前计算出梯度的表达式,然后将它写下来,从W值开始计算dW,或每步的梯度。在实际使用中这种方法更好。
 计算每步的梯度(来自cs231n)
计算每步的梯度(来自cs231n)
概括起来,在实际使用中,你可能并不会使用数值梯度,但它很简单也很有意义。实际上当在计算梯度时,你将总是使用解析梯度。然而有趣的是,数值梯度却非常有用的调试工具。就是说当你已经写了一些代码,然后再写一些代码来计算损失和梯度的损失,你怎么进行调试,你怎样验证你写入代码的解析表达式是正确的,所以通常的策略是使用数值梯度作为单元测试来确保你的解析梯度是正确的。当你使用数值梯度进行检查时,这个过程非常缓慢,并且不精确,你需要减少问题的参数数量,让它能在一个合理的时间内运行,但当你写你自己的梯度计算时,它确实是非常有用的调试策略,所以在实践中它非常常用,并且你们也需要在你们的作业里实践它。
 总结一下(来自cs231n)
总结一下(来自cs231n)
所以一旦我们知道怎样计算梯度,它将我们引向一个超级简单,好像只需三行代码的梯度下降算法,但事实上,它却是计算巨大,也最为复杂的深度学习算法的核心。
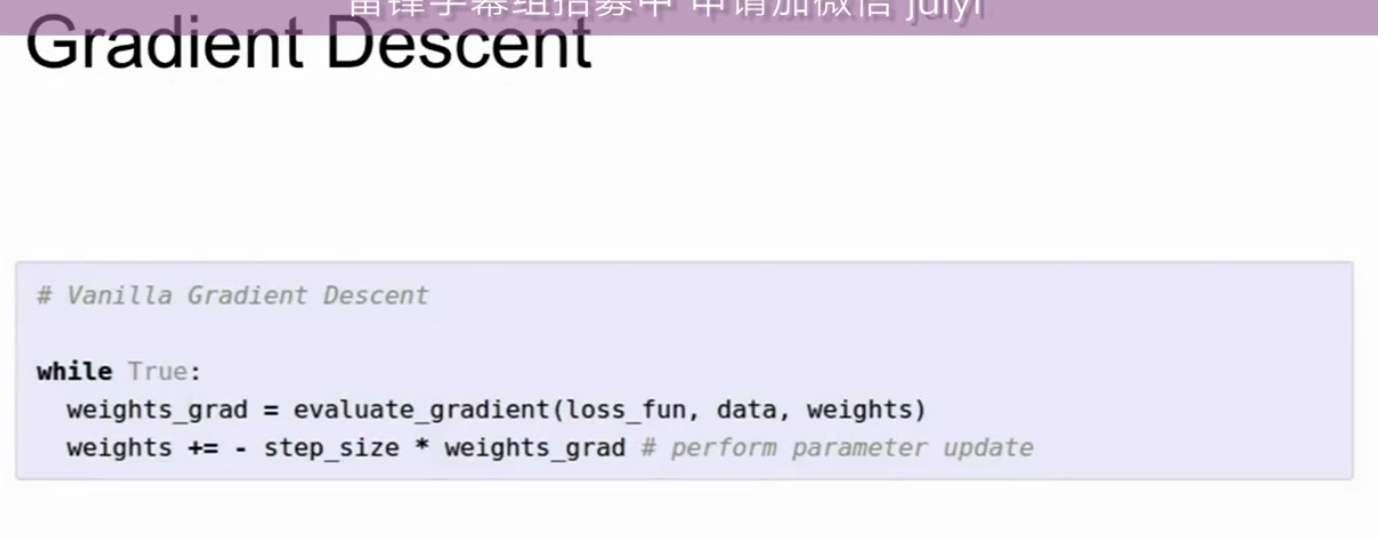 梯度下降 代码示例(来自cs231n)
梯度下降 代码示例(来自cs231n)
在梯度下降算法中,首先我们初始化W为随机值,当为真时,我们计算损失和梯度,然后向梯度相反的方向更新权重值。因为你需要记住,梯度是指向函数的最大增加方向,所以梯度减小则是指向函数最大减小的方向,所以我们向梯度减小的方向前进一小步,然后一直重复,最后网络将会收敛,皆大欢喜。但是步长是一个超参数,这就告诉我们每次计算梯度时,在那个方向前进多少距离,这个步长也被叫做学习率,它可能是你需要设定的最重要的一个超参数。对于我来说,当我训练神经网络时,确定这一步长,或者说学习率,是我要检查的第一个超参数,其他比如模型大小,需要多少正则化,我会晚点再做。找到合适的学习率或步长是我首先要做的事情。
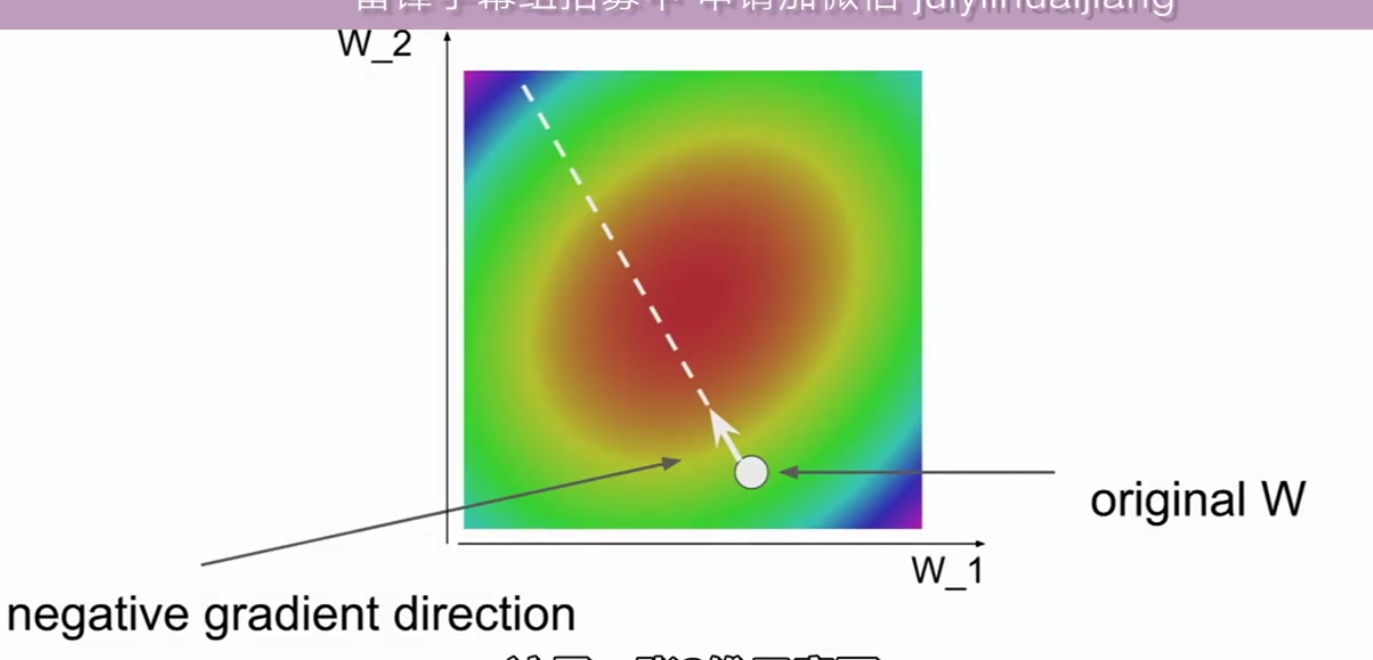 梯度下降 2维图示(来自cs231n)
梯度下降 2维图示(来自cs231n)
所以如图所示,这是一张2维示意图,这里我们可以说这是一个碗形表示我们的误差函数,中心的红色区域表示误差值较低,是我们的目标。这些靠近边缘的蓝色和绿色区域代表较高的误差值,是我们要避免的。
现在我们以一个空间内的随机点来开始我们的W,然后计算梯度的反方向,我们希望它将指向最终的最小值。如果我们重复这一过程,那最终我们会达到最小值。
实际上的效果如下图所示,如果我们不断重复这一过程,我们在某个点初始,每次以小梯度改进,最终你会看到参数朝着中心点迂回前进,不断逼近最小值。这就是你想达到的,因为你想得到低误差值。
 梯度下降 2维过程(来自cs231n)
梯度下降 2维过程(来自cs231n)
在接下来的介绍中,我们会看到更加高级一点的走法,它们运用一些更加新的法则,你可以采取稍微好一点的步骤,在多步中整合梯度下降的步骤,类似这些,似乎在实际中稍微好用一些,也更常用,当我们实践中训练这些参数时比这种普通梯度下降法更好用。下图展示这些更高级的用法如何优化这些问题。效果如下,
 梯度下降 2维不同的过程(来自cs231n)
梯度下降 2维不同的过程(来自cs231n)
黑色的是原来的,这两个其他曲线运用了更高级的迭代规则,来选择如何使用梯度信息决策下一步,其中一种是带动量的梯度下降,另一种是Adam优化器。但其思想就是一个非常基本的算法,即梯度下降。利用每一步的梯度决定下一步的方向,有不同的更新策略决定究竟如何使用梯度信息,但背后都基于同样的基本算法,每一步都试着往下坡走。
随机梯度下降
 随机梯度下降 SGD(来自cs231n)
随机梯度下降 SGD(来自cs231n)
这里有一点需要注意的地方。记得我们已经定义了误差函数,我们定义了一种损失误差计算我们的分类器在训练样本中的每一步表现有多糟糕,然后我们设定数据集的总误差是整个训练集误差的平均值,但实际中,N可能会非常非常大,例如如果你用的是ImageNet数据库,N可能会大至130万,所以要算这损失值,计算成本非常高,可能对这一函数需要上百万次的运算,这样会很慢。因为梯度是一个线性运算符,当你试着计算表达式的梯度时,你会发现误差函数的梯度值是每个单项误差梯度值的总和。
所以如果我们需要再次计算梯度,好像就需要我们迭代整个训练数据集迭代所有N个样本。如果我们的N是一百万,那就会变得非常慢,我们需要等待非常长的时间才能更新一次W。所以在实际操作中,我们往往使用随机梯度下降,它并非计算整个训练集的误差和梯度值,而是在每一次迭代中选取一小部分训练样本成为minibatch(小批量),按惯例,这里都取2的n次幂,如32,64,128是常用数字。然后我们利用这一minibatch来估算误差总和以及实际梯度,就是随机的,因为你可以把它当做对真实数值期望的一种蒙特卡洛估计,这就让我们的算法稍微高级一点,但仍然只需要四行,所以这里就是:为真时,随机取一些minibatch数据,评估minibatch的误差值和梯度,然后更新各个参数基于这一误差值的估计,以及梯度的估计。
重复说一遍,这里我们将会看到更高级的更新规则,在过程中如何整合多个梯度,但这是一个基本的训练算法,我们在深度神经网络中经常用到。
线性分类器使用随机梯度下降来训练它们,可以在网上随机梯度下降 Web Demo看看用梯度下降来训练线性分类器是怎么回事。
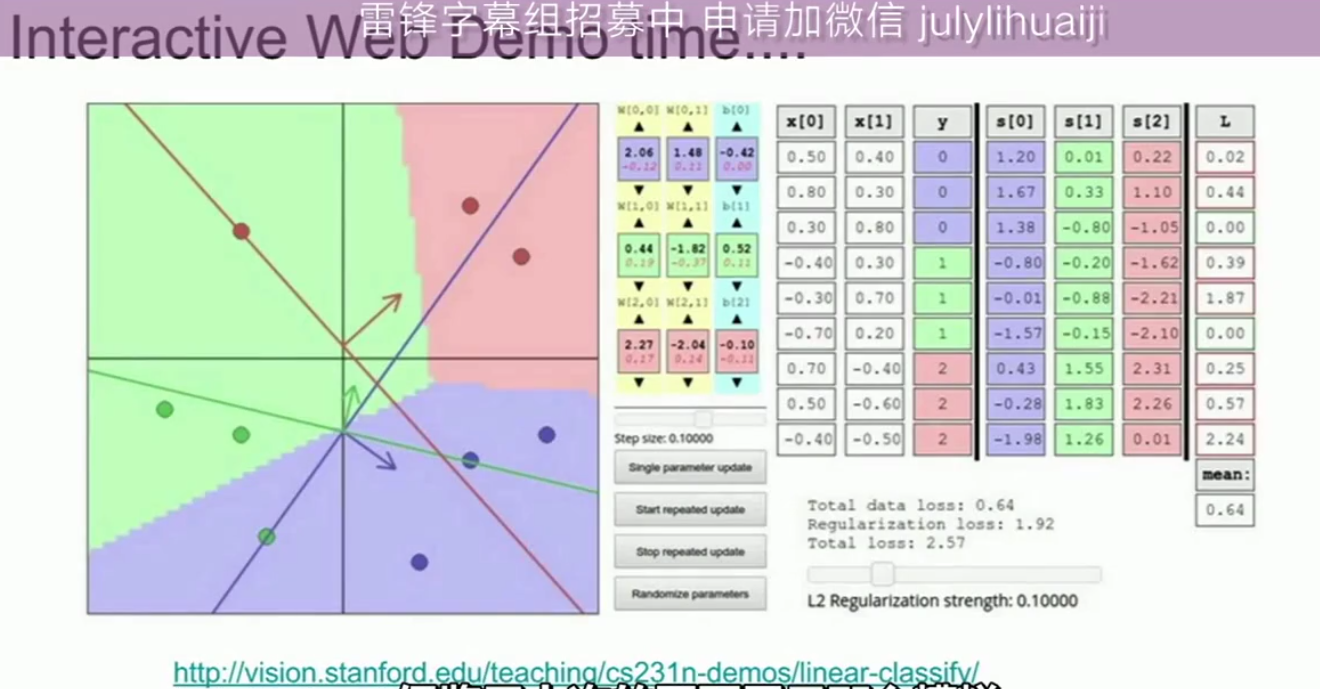 随机梯度下降 Web Demo(来自cs231n)
随机梯度下降 Web Demo(来自cs231n)
番外:图像的特征
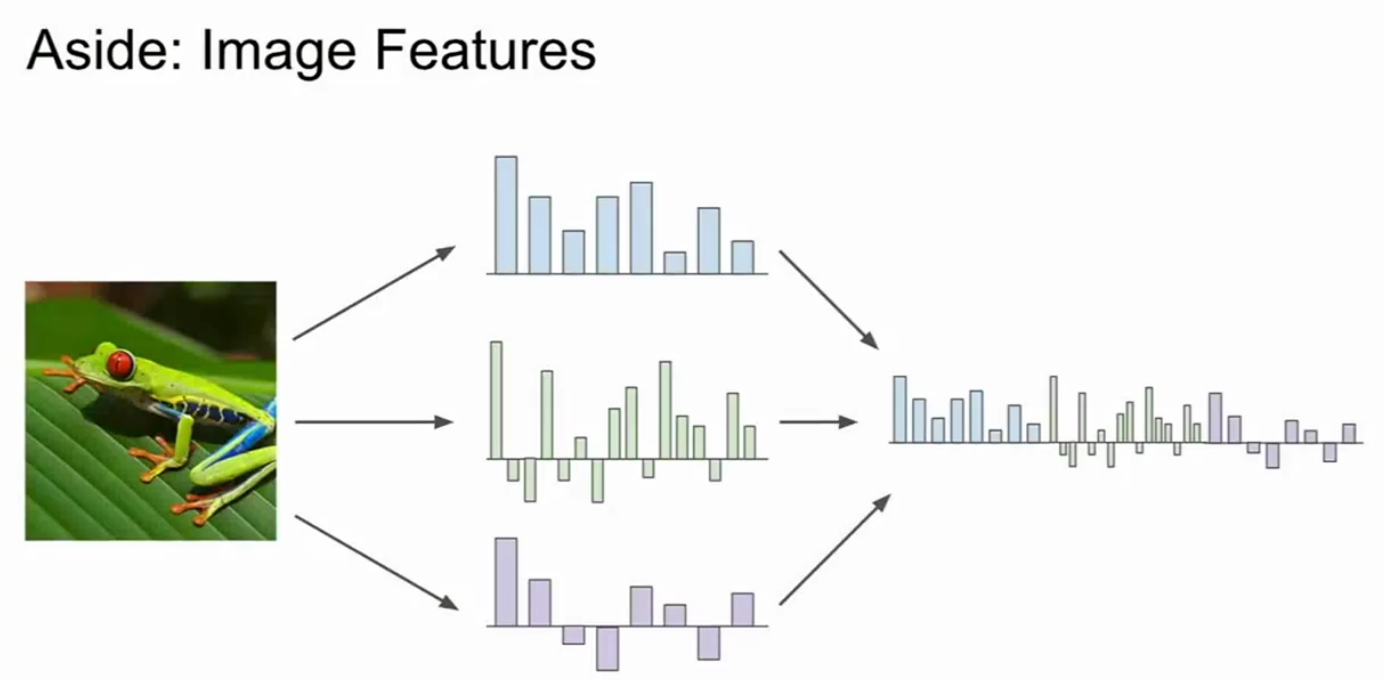 图像的特征(来自cs231n)
图像的特征(来自cs231n)
前面已经讲了,线性分类器就是将我们的原始像素取出,将这些原始像素直接传入线性分类器,但如上节课所讲,这样做可能不太好,因为多模态之类的原因,所以实际操作中,如果直接输入原始像素值传递给线性分类器表现似乎不太好,所以当神经网络大规模运用之前,常用的方式是使用两步走策略,首先拿到图像,就按图片的各种特征代表,例如可能计算与图片形象有关的数值,然后将不同的特征向量合到一块得到图像的特征表述。现在这一关于图像的特征表述会作为输入源传入线性分类器,而不是将原始像素传入分类器。这么做的动机是什么呢?
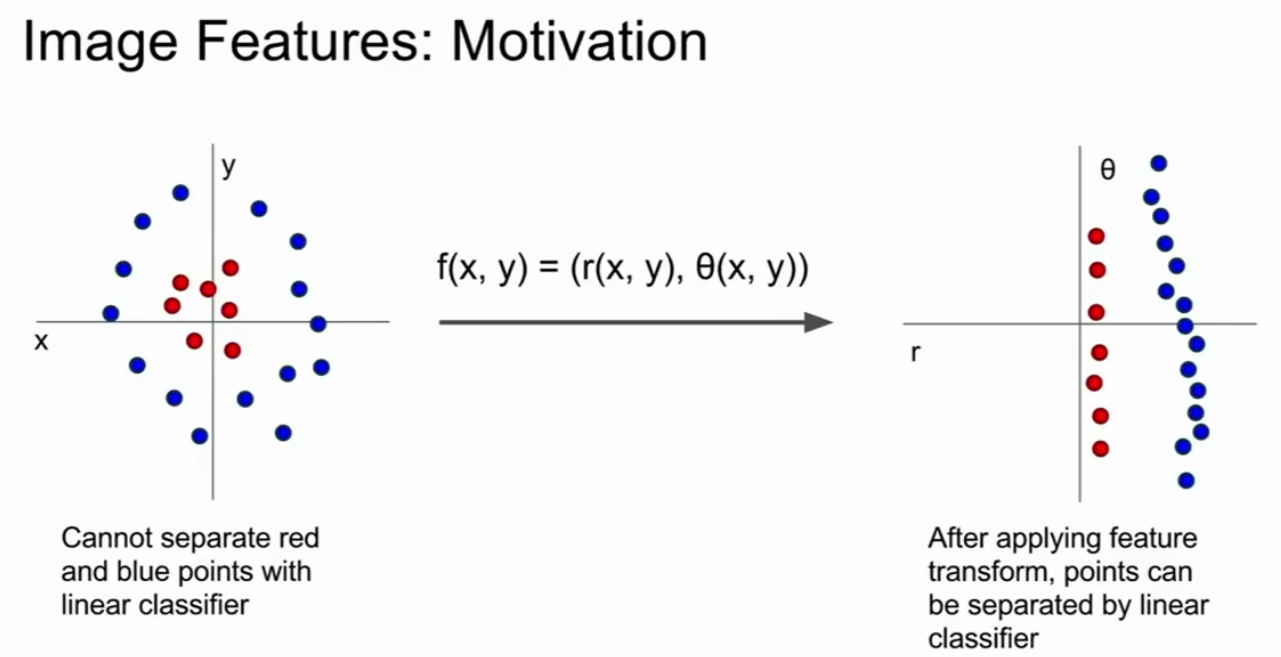 图像的特征:动机(来自cs231n)
图像的特征:动机(来自cs231n)
想象一下,训练数据集如左边所示,红点分布在中间,蓝点分布在他们周围。对于这种问题我们不能用一个线性决策边界将红点从蓝点中分开。但是如果我们采用一个灵活的特征转换,在这个例子中我们运用极坐标转换,现在我们得到转换特征就可以把复杂的数据集变成线性可分的,然后可以由线性分类器正确分类。
这里整个策略就是找到正确的特征转换从而计算出所关心问题的正确指标。对于图像而言把原始像素值转换成极坐标并不能起什么作用,但事实上有可能起作用的图像特征表示也许能帮助你解决问题,同时会比将原始像素放入分类器具有更好的效果。
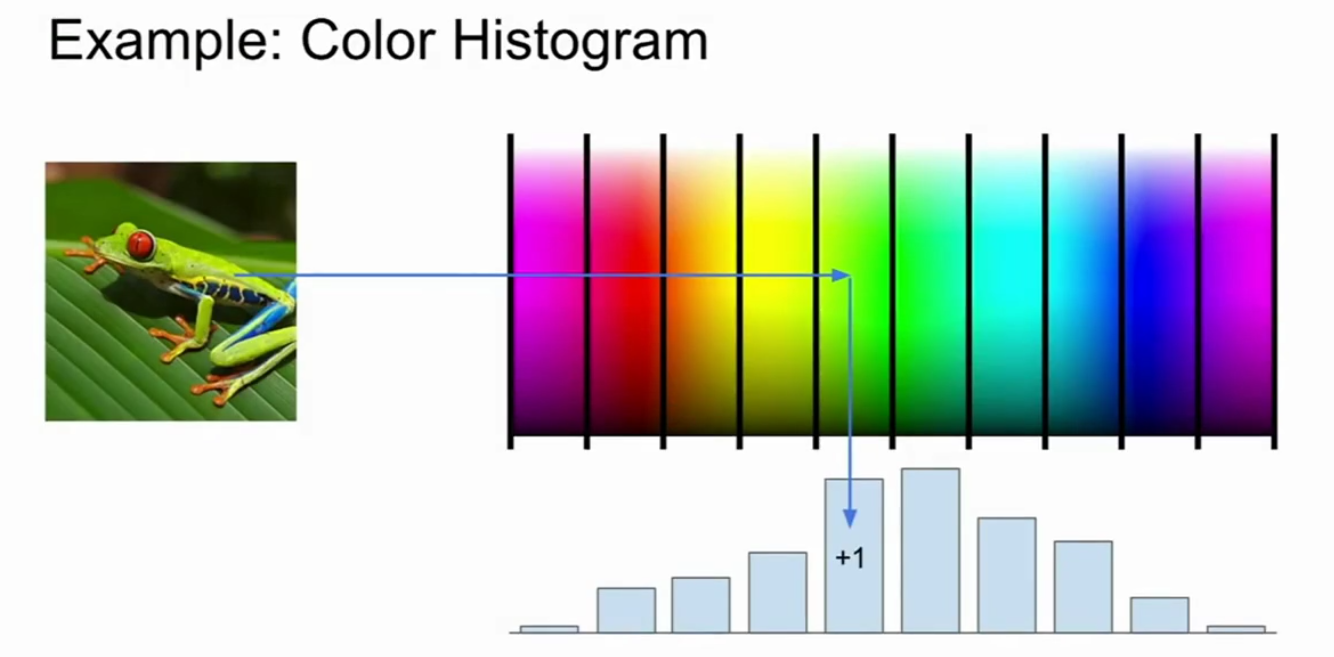 颜色直方图(来自cs231n)
颜色直方图(来自cs231n)
一个特征表示非常简单的例子就是颜色直方图。
获得每个像素值对应的光谱,把它分到柱状里,将每一个像素都映射到这些柱状里,然后计算出每一个不同柱状中像素点出现的频次,这个从全局上告诉我们图像中有哪些颜色。比如这里有一只青蛙,特征向量告诉我们这里有很多绿色分量,没有太多紫色和红色分量,可以在实践中发现这种简单的特征分量。
 HOG(来自cs231n)
HOG(来自cs231n)
在神经网络确立统治地位之前,一个常用的特征向量就是方向梯度直方图。
有研究发现,人类视觉系统中,有向边缘非常重要,而特征标识的有向梯度直方图尝试获取同样的感觉,并且测量图像中边缘的局部方向,看看它做了什么。
先获取图像,然后将图像按八个像素区分为八份,然后在八个像素区的每一个部分计算 每个像素值的主要边缘方向,把这些边缘方向量化到几个组,然后在每一个区域内,计算不同的边缘方向从而得到一个直方图。现在你的全特征向量就是这些不同组的边缘方向直方图,这个直方图是从图像的八个区域得来,这在某种程度上归因于我们之前看到的颜色直方图分类器,颜色直方图从全局上看出图像中存在哪些颜色,也可以看出图像中有哪些不同类型的边缘,即使是图像的不同部分、不同区域内存在着哪些类型的边缘都可以知道。比如左边的青蛙,可以看见它坐在叶子上,这些叶子主要存在对角线边缘,如果将这些方向梯度特征的直方图可视化,可以看见在这个区域里存在着大量的对角线边缘,这就是获取的方向梯度特征表示的直方图。这是一个非常常见的用于目标识别的特征表示,事实上并没有兴起太久。
 Bag of Words(来自cs231n)
Bag of Words(来自cs231n)
另一个特征表示的例子就是词袋,这是从自然语言处理中获得的灵感。如果你得到一段话,用一个特征向量表示这段话的一个方法是计算不同词在这段话中出现的次数。这种方法应用于图像,需要定义视觉单词字典。我们采用两阶段方法,首先获得一堆图像,从这些图像中进行小的随机块的采样,然后采用K均值等方法将它们聚合成簇,从而得到不同的簇中心。这些簇中心可能代表了图像中视觉单词的不同类型。
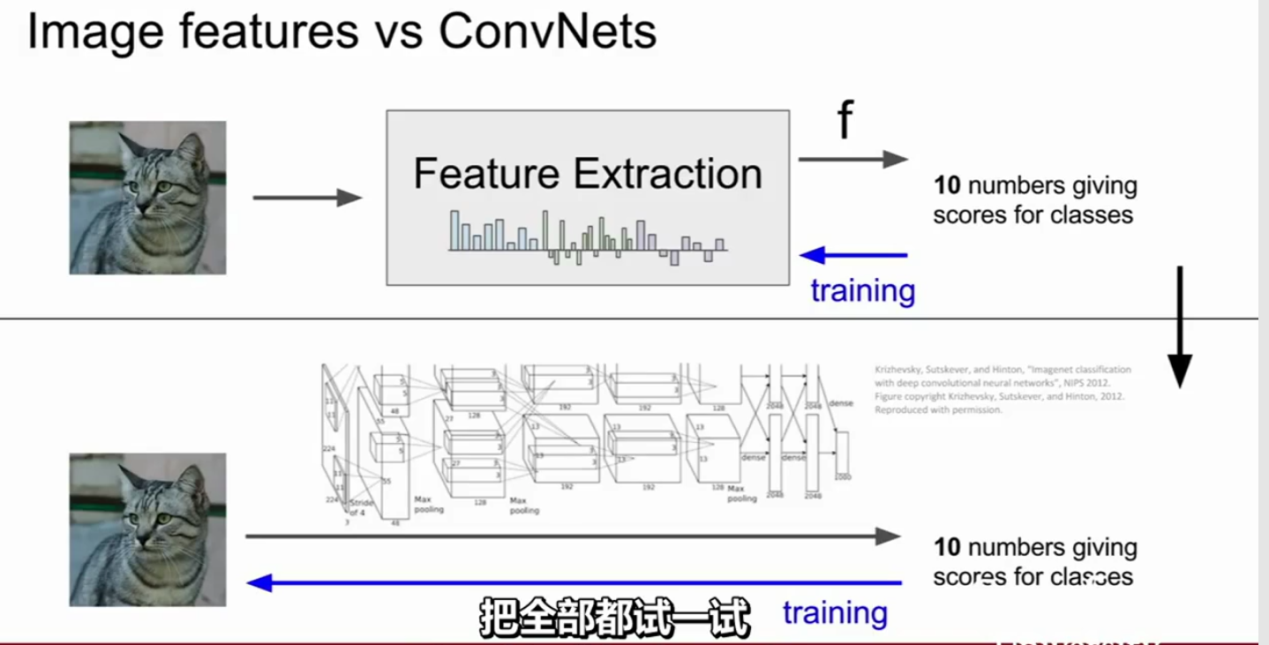 应用CNN学习图像特征(来自cs231n)
应用CNN学习图像特征(来自cs231n)
作为一个引子,把全部都试一试,5-10年以前,图像分类通道就像这样,拿出你的图像,然后计算图像不同特征表示的差异,比如词袋或者方向梯度直方图,将整个特征连接在一起,来喂养这些线性分类器的特征提取器。简单来说这种方式比那样复杂一些,但这是更常见的思路。
接下来的想法就是在提取这些特征之后固定特征提取器,使得它在训练中不会被更新,而在训练中仅仅更新线性分类器。如果它用于最重要的特征。
事实上,我一直认为一旦我们移到卷积神经网络和这些深度神经网络,看上去也没多少不同,唯一的差别就是并非提前记录特征,而是直接从数据中学习特征,所以我们将获取的像素值输入卷积神经网络,经过多层计算,最终得到一些数据驱动的特征表示的类型,然后我们在整个网络中训练所有的权重,而不是最上层线性分类器的权重。