ELK架构 (ElasticSearch、Logstash、Kibana)
引言
Elasticsearch是一款非常强大的开源存储、搜索、分析引擎,可以帮助你从海量数据中,快速找到相关的信息。
除了搜索和存储,结合Beats(采集)、Logstash(聚合处理)、Kibana(分析),Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控、信息安全等多个领域。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,甚至通过使用机器学习技术,自动识别异常状况。
随着越来越多的人学习和使用Elasticsearch,Elastic公司也推出了Elastic工程师的认证考试,这是一门含金量很高的技术认证,可以通过学习Elasticsearch参加Elastic的工程师认证。开发人员、运维工程师、架构师、数据分析师、产品经理,都有必要学习Elasticsearch,在大数据的时代,掌握近实时的搜索和分析能力,才能掌握核心竞争力,洞见未来。
Elasticsearch的诞生和发展离不开其底层基础Lucene,Lucene由Doug Cutting(Hadoop之父)主导开发,它是基于Java语言开发的搜索引擎类库,1999年创建,2005年成为Apache顶级开源项目。它具备高性能、易扩展的特点,是全文检索领域的优秀底层技术,但只能基于Java开发、接口学习曲线陡峭、原生不支持水平扩展,这些局限让它难以被广泛普及和大规模应用。
Shay Banon(Elasticsearch创始人)针对Lucene的不足,推动了Elasticsearch的诞生。
- 过渡阶段(
2004年):Shay Banon基于Lucene开发了Compass,初步尝试简化Lucene的使用,但仍有优化空间; - 正式诞生(
2010年):Shay Banon重写Compass,并命名为Elasticsearch,核心改进直击Lucene的痛点。
从Lucene到Compass,再到Elasticsearch,保留了高性能检索能力,同时提升易用性和规模化部署能力。ES支持分布式架构,实现水平扩展,满足大规模数据检索的需求;大幅降低全文检索的学习曲线,且可以被任意编程语言调用(不再局限于Java),极大提升了易用性和跨语言兼容性。我们也可以从数据库引擎排名网站上实时查看Elasticsearch在数据库引擎行业的排名。
Elasticsearch版本与升级
2010年2月发布首个版本0.4,后续核心版本迭代集中在2014-2019年,依次推出1.0(2014.1)、2.0(2015.10)、5.0(2016.10)、6.0(2017.10)、7.0(2019.4)、8.0(2022.2)、9.0(2024),版本迭代围绕底层引擎升级、功能扩展、性能优化展开。
核心版本关键特性
总体上看,底层依赖Lucene持续升级,功能上从基础检索向多场景(跨集群、SQL、容器化)拓展,架构上简化设计(废除多Type),性能上持续优化存储、查询、并发能力,同时降低使用门槛(如Security免费、简化升级)。
5.x
基于Lucene 6.x,默认打分机制从TF-IDF改为BM 25,支持Ingest节点、Painless Scripting、Completion suggested、原生的Java REST客户端等功能,Type标记为Deprecated,支持了Keyword类型。性能优化层面,内部引擎移除了避免同一文档并发更新的竞争锁(提升15%-20%性能),Instant aggregation支持分片上聚合的缓存、新增Profile API;
6.x
基于Lucene 7.x,新增跨集群复制(CCR)、索引生命周期管理、SQL支持等功能。更友好的升级及数据迁移,在主要版本之间的迁移更为简化,体验升级,全新的基于操作的数据复制框架,可加快恢复数据。性能优化层面,有效存储稀疏字段的新方法,降低了存储成本,在索引时进行排序,可加快排序的查询性能;
7.x
基于Lucene 8.0,重大变更为正式废除单个索引下多Type支持,7.1开始,Security功能免费使用,新增K8S适配(ECK,ElasticSearch Operator on Kubernetes),新增全新集群协调(New Cluster Coordination)、完整高级REST客户端(Feature-Complete High Level REST Client)、Script Score Query等功能。性能层面,默认主分片数从5改为1,避免过度分片(Over Sharding),以及更快的Top K查询速度。
8.x
基于Lucene 9.0,核心围绕安全性、可观测性、性能、云原生升级,同时强化企业级能力。
- 安全性(默认强制开启,零配置)
- 核心变更:默认启用
TLS/SSL加密(所有节点间通信、客户端连接),内置身份验证(Elasticsearch Security功能完全免费且默认开启); - 新增:
RBAC细粒度权限控制、API密钥管理、SAML/OAuth2单点登录适配,企业级安全门槛大幅降低。
- 核心变更:默认启用
- 性能与底层引擎升级
- 基于
Lucene 9.x:查询性能提升20%-30%,倒排索引压缩率优化,Top-K查询、聚合计算速度进一步提升; - 向量搜索(
Vector Search):原生支持稠密向量/稀疏向量检索,为AI语义搜索、Embedding检索铺路; - 索引优化:异步写入、段合并策略升级,写入吞吐量提升,磁盘
IO开销降低。
- 基于
- 云原生与运维效率
ECK(Elastic Cloud on Kubernetes)GA:原生适配K8S,支持一键部署、扩缩容、版本升级,运维自动化程度大幅提升;- 数据生命周期管理(
ILM)增强:支持冷热温冷分层存储、自动数据归档/删除,适配海量时序数据(日志/监控)场景; - 可观测性集成:与
Elastic APM、Logs、Metrics深度融合,一站式监控集群性能、业务检索链路。
- 功能增强
- 全文检索:新增近似字符串匹配(
Fuzzy查询优化)、多语言分词器升级(支持更多小众语言); SQL/PPL能力:SQL查询引擎兼容更多标准语法,支持跨索引联合查询、复杂聚合;- 数据导入:原生支持
CDC(变更数据捕获),可实时同步数据库(MySQL、PostgreSQL)数据到ES。
- 全文检索:新增近似字符串匹配(
9.x
基于Lucene 10.x,面向AI时代的核心迭代,核心目标是让ES成为AI检索的核心底座,同时简化架构、提升极致性能。
AI原生能力(核心突破)- 向量数据库特性强化:支持向量索引(
HNSW/PQ算法)、混合检索(文本+向量),毫秒级响应亿级向量检索; - 原生集成
AI生态:对接OpenAI、阿里云通义等大模型API,支持文本→Embedding→向量检索→结果生成全流程,无需额外中间件; - 提示词模板:内置检索增强生成(
RAG)模板,降低AI应用开发门槛。
- 向量数据库特性强化:支持向量索引(
- 性能与架构重构
Lucene 10.x底层升级:向量检索性能提升5-10倍,磁盘存储成本降低40%;- 无状态节点架构:部分节点(协调节点)支持无状态部署,适配云原生弹性扩缩容,集群弹性提升;
- 分片管理自动化:自动分片均衡、分片大小自适应,无需人工干预分片规划(解决
7.x、8.x分片配置复杂问题)。
- 简化使用与运维
- 移除过时
API:彻底淘汰7.x标记废弃的旧API(如Transport Client),统一基于RESTful API交互; - 一键升级工具:支持
8.x→9.x无缝升级,自动处理数据格式、索引模板兼容问题; - 智能监控:
AI辅助的异常检测,自动识别慢查询、分片故障、资源瓶颈并给出优化建议。
- 移除过时
- 企业级能力强化
- 多租户隔离:支持物理级、逻辑级多租户,资源(
CPU、内存、存储)隔离更严格,适配SaaS场景; - 跨集群检索优化:跨集群查询延迟降低
50%,支持全球分布式集群的实时检索; - 合规性:新增
GDPR/CCPA数据合规功能,支持数据脱敏、访问审计日志溯源。
- 多租户隔离:支持物理级、逻辑级多租户,资源(
Elastic Stack家族成员及其应用场景
 Elastic Stack生态圈
Elastic Stack生态圈
BEATS:轻量的数据采集器
 Beats系列
Beats系列
Logstash:数据处理管道
开源的服务器端数据处理管道,支持从不同来源采集数据,转换数据,并将数据发送到不同的存储库中。
Logstash诞生于2009年,创始人Jordan Sisel,最初用来做日志的采集与处理。2013年被Elasticsearch收购。
Logstash特性
- 实时解析和转换数据
- 从
IP地址破译出地理坐标; - 将
PII(个人可识别信息)数据匿名化,完全排除敏感字段;
- 从
- 可扩展:
200多个插件(日志、数据库、Arcsigh、Netflow); - 可靠性 & 安全性
Logstash会通过持久化队列来保证至少将运行中的事件送达一次;- 数据传输加密;
- 监控
Kibana:可视化分析利器
Kibana名字的含义(Kiwifruit + Banana);- 数据可视化工具,帮助用户解开对数据的任何疑问;
- 基于
Logstash的工具,2013年加入Elastic公司。
X-Pack商业化套件
6.3之前的版本,X-Pack以插件方式安装X-Pack开源之后,Elasticsearch & Kibana支持OSS版和Basic两种版本- 部分
X-Pack功能支持免费使用,6.8和7.1开始,Security功能免费 - 产品分级:
OSS,Basic,黄金级,白金级
Elastic的发展
Elastic通过收购补能力、开源扩生态的路径,从聚焦Elasticsearch检索能力,逐步拓展至云服务、可观测性(APM)、机器学习、SaaS 搜索等领域,构建完整的Elastic Stack生态体系。
2015年3月收购Elastic Cloud(云服务),提供Cloud服务2015年3月收购PacketBeat;2016年9月收购PreAlert(补齐机器学习异常检测能力);2017年6月收购Opbeat(进军APM领域),11月收购SaaS厂商Swiftype(提供网站、APP搜索),从单一检索引擎向全栈数据平台延伸;2018年X-Pack开源。
常见应用场景
Elasticsearch和数据库集成
有些业务场景选择单独使用Elasticsearch存储,但多数场景下,ES不适合单独做主存储,有系统对接、事务要求、高频更新三种场景时,采用MySQL做主库,ES做检索库的双库架构。
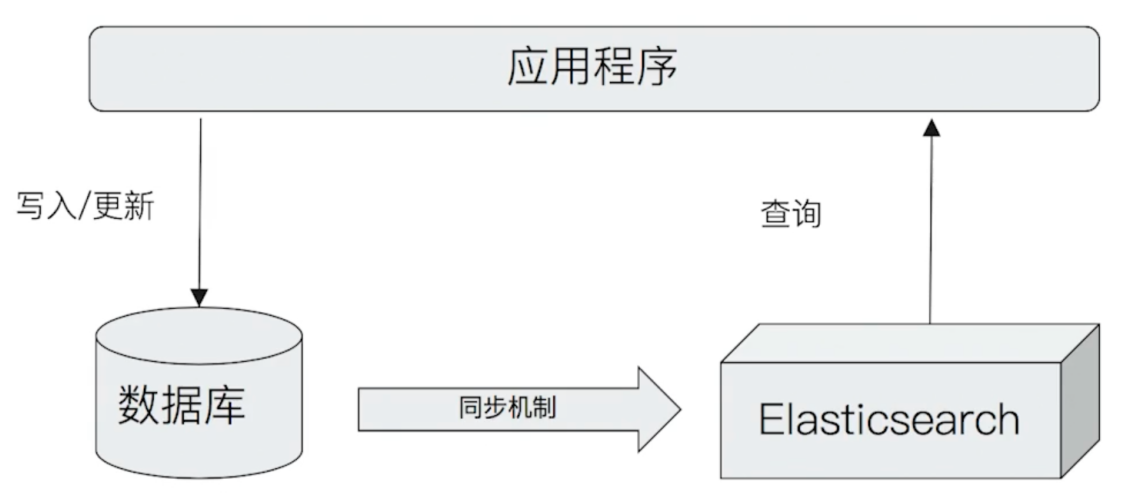 和数据库集成
和数据库集成
以下情况可考虑和数据库集成
- 与现有系统的集成
- 需考虑事务性
- 数据更新频繁
日志管理
 devops
devops
日志很重要
- 运维:医生给病人看病,日志就是病人对自己的陈述
- 恶意攻击,恶意注册,刷单,恶意密码猜测
挑战
- 关注点很多,任何一个点都有可能引起问题
- 日志分散在很多机器,出了问题时,才发现日志被删了
- 很多运维人员是消防员,哪里有问题去哪里
日志核心作用:故障排查 + 安全风控,日志/监控/告警(日志搜集–格式化分析–全文检索–风险告警)。
现存痛点:日志分散难归集、易丢失、运维被动救火,也是ELK日志系统落地的缘由。
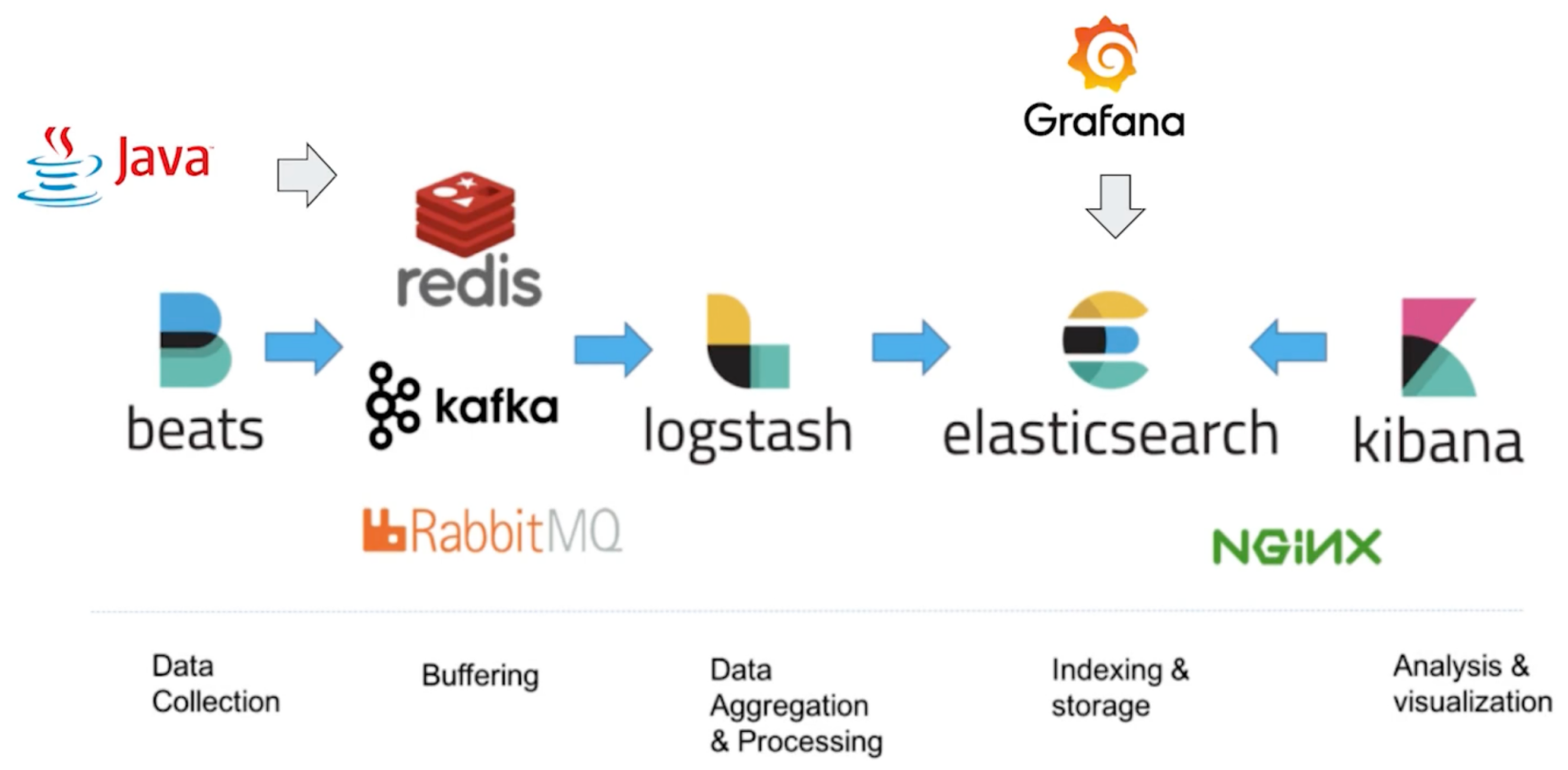 指标分析 / 日志分析
指标分析 / 日志分析
支持多种方式接入ES
- 多语言适配:提供
Java、Go、.NET、Python、Ruby、PHP、Groovy、Perl等多种编程语言的官方类库,能适配不同技术栈的开发场景,降低跨语言集成门槛; API接入灵活且有推荐方案:支持RESTful API(9200端口)和Transport API(9300端口)两种接入方式,官方建议优先使用更通用、易对接的RESTful API;- 兼容传统数据接入标准:支持
JDBC和ODBC协议,可无缝对接依赖这类标准的传统数据库工具、BI工具等,拓展了数据交互和集成的场景。
ELK分布式架构集群部署:高可用、高并发、高性能
Elasticsearch支持集群模式,是一个分布式系统,ES集群由多个ES Node实例组成。 其好处主要有两个,
- 方便扩展,增加节点数,来增大系统容量,如内存、磁盘,使得
ES集群可以支持PB级的数据,高并发优势; - 提高系统可用性,即使部分节点停止服务,整个集群依然可以正常服务,高可用优势。
 ES架构简图
ES架构简图
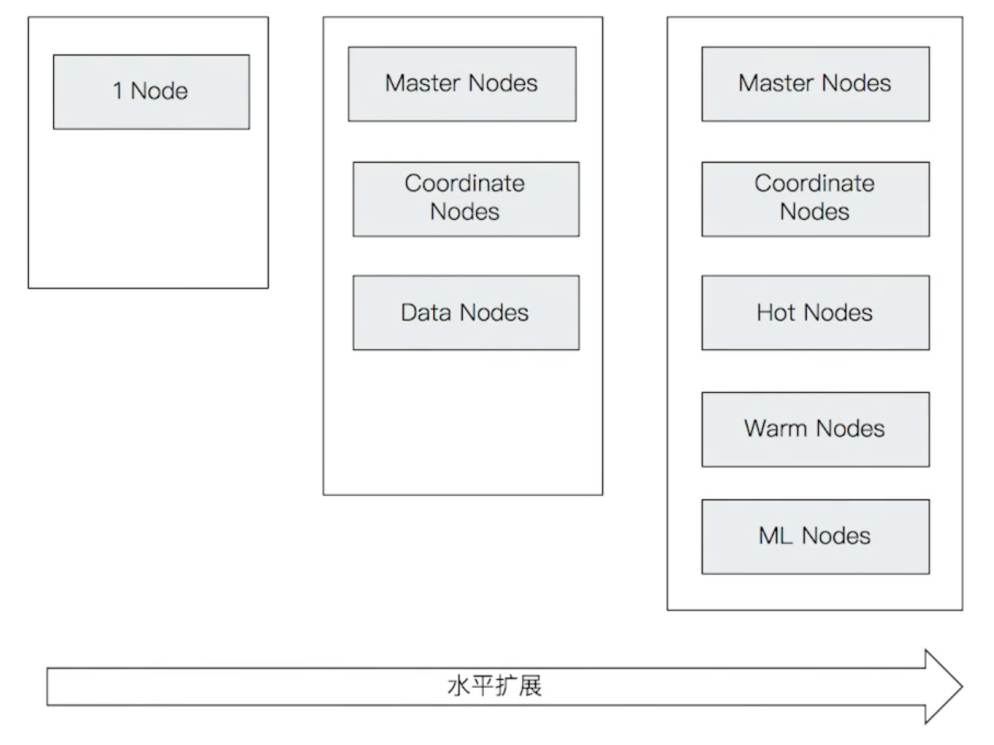
- 超强扩展能力:集群规模可从单个节点灵活扩展至数百个节点,支持平滑的水平扩展,能适配从小规模到超大规模的业务场景;
- 高可用特性:从服务(节点故障不影响整体集群运行)和数据(数据多副本存储)两个维度保障高可用,同时结合水平扩展进一步提升系统稳定性;
- 精细化节点管理:支持多种节点类型(
Master Nodes、Coordinate Nodes、Data Nodes等),还适配Hot & Warm架构(热节点存储高频访问数据、温节点存储低频访问数据),可根据业务场景对节点做针对性规划,优化资源利用和检索性能。
我们暂不考虑跨地域(跨IDC机房,物理距离很远)的问题,先解决在一个小的局域网内,ES集群高可用的问题。集群搭建会从这些维度考虑,
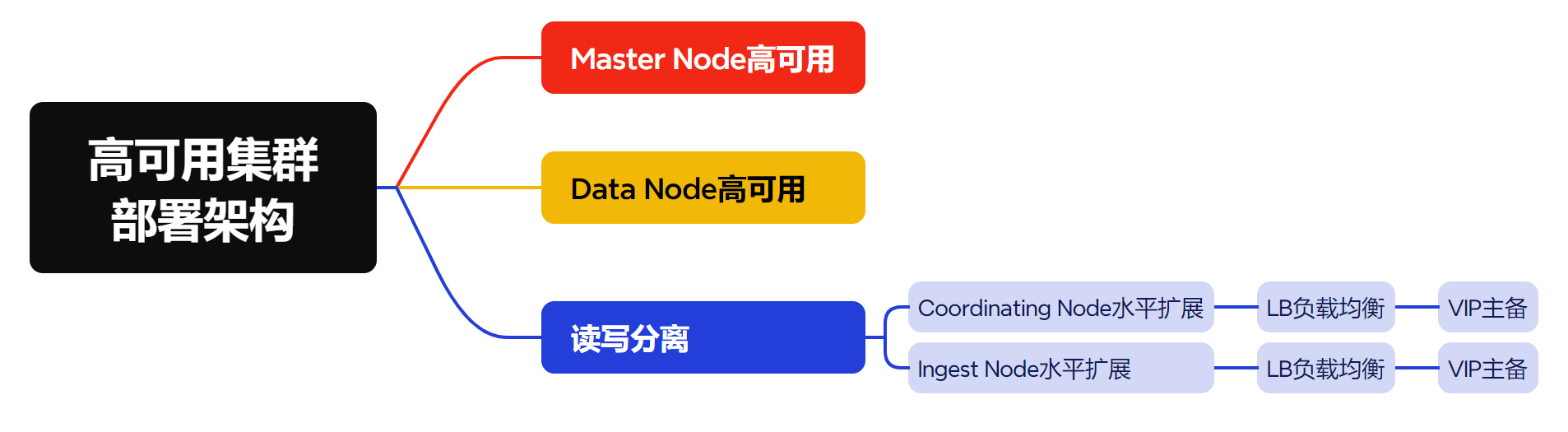 高可用集群部署架构,需要考虑的点
高可用集群部署架构,需要考虑的点
Master Node管理节点怎么做到高可用?Data Node数据节点怎么做到高可用?- 要做到高可用,一定会做负载均衡,读怎么负载均衡?写怎么负载均衡?
- 有了负载均衡后,负载均衡本身有会有一些瓶颈,怎么解决单点故障的瓶颈问题?比如用
vip的主备机制。
Tips
- 了解整个高可用集群涉及哪些节点角色?为什么要做高可用架构?做这些高可用架构有哪些依据?应该做什么样的规划?
- 实际工程中的部署实操,区分开发、测试或者线上环境,开发环境是小型
Elasticsearch集群部署,测试环境或者线上环境才是真正的Elasticsearch集群部署。- 部署完成后,简单介绍下集群的管理和使用,比如集群的健康状况,以及索引,使用集群的方法姿势等等。
ES核心概念
以一个30个节点的集群为例,介绍一下ES的核心概念。
ES印象
04年诞生,分布式文档存储,多节点,多分片。Elasticsearch不会将信息存储为类似列数据库的行(row),而是存储为已序列化为JSON文档的复杂数据结构。
它是一个近实时的系统,存储文档后,将在1秒钟内(默认刷新频率为1s)几乎实时地对其进行索引和完全搜索。
Kibana是一个针对 Elasticsearch 的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用 Kibana,可以通过各种图表进行高级数据分析及展示。
把ES和MySQL做个直观比对
从宏观概念上做下对比,
- 首先,
MySQL里面的数据库实例,对应到ES里边,是一个索引。 MySQL数据库实例有很多表,ES里一个索引有很多Type,一个Type就代表一个表,只不过ES里把一个索引固定为只有一个Type,即一个表。- 在
MySQL中,每张表都有一个表结构,ES里边也一样,只不过改了个名字,叫映射(mapping)。 MySQL中一个表里边有很多行数据,ES中每一行数据对应的一个文档(Documents),文档格式默认为json,是以文档为单位建立索引的。MySQL里,每个表有很多列,同样ES一个文档有很多字段,相当于有很多列,只不过底层存储结构不一样。
分片
文档(doc)和索引(index)之间,还有一个分片(shard)的概念。
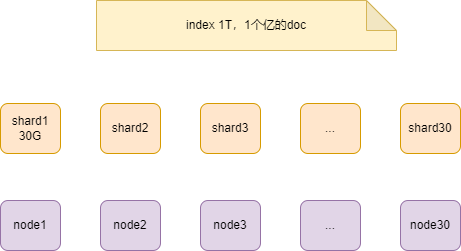
举个例子,说明下shard分片出现的原因。
 分片
分片
1T的索引,对应到MySQL里,就是1T的表。因为ES里一个索引只有一个Type,对应到MySQL中,一个索引就是一张表。
1T数据,在一个机器上也不是放不下,硬盘肯定够,但内存肯定不够。1T索引大概包括了一个亿的文档,这些数据放在一个节点上是不现实的。
节点数30,索引在每一个节点上,就是一个分片,那么平均下来,一个分片存储约30G的数据。大的索引以小的单位维护起来。
注:官方推荐,每个分片的数据量大小不超过
50G。
副本
孤本一定不是高可用的,所以就有了副本的概念。
主本和副本同在一个节点上面,是达不到高可用和故障转移的效果。反过来说,一个节点挂了,主副本都没有了,这样就没有容错。
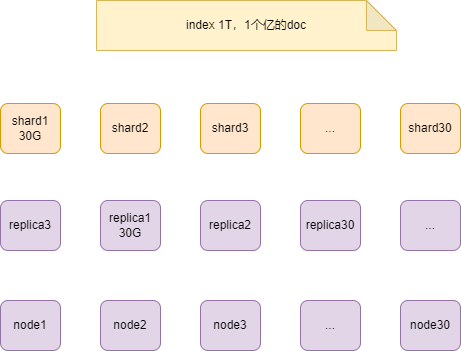 分片,有了一个副本
分片,有了一个副本
如果同时两个节点挂了,也做不到高可用,可以增加副本的数量。
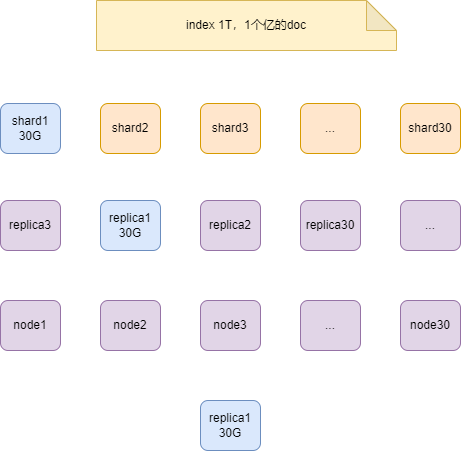 分片,有2个副本
分片,有2个副本
副本之所以重要,有两个主要原因,
- 在分片/节点失败的情况下,副本提供了高可用性。复制分片不与主分片置于同一节点上是非常重要的。
- 提升搜索的吞吐量。因为搜索可以在所有的副本上并行运行,副本可以扩展你的搜索量/吞吐量。
读写是不一样的流程
- 写主本,由节点完成文档的同步;
- 读,则在主副本上进行负载均衡,并发量不够,可以增加副本来提升。
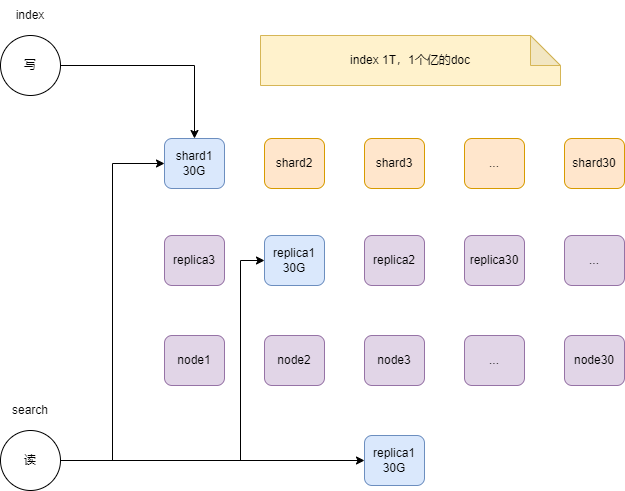 读写是不一样的流程
读写是不一样的流程
副本,可以一个也不用,一个索引也可以被复制0次(即没有复制) 或多次。一旦复制了,每个索引就有了主分片(作为复制源的分片)和副本分片(主分片的拷贝)。
ES在6.x及更早版本,默认5:1,5个主分片,每个分片,1个副本分片。7.0.0及更高版本,默认主分片数调整为1。
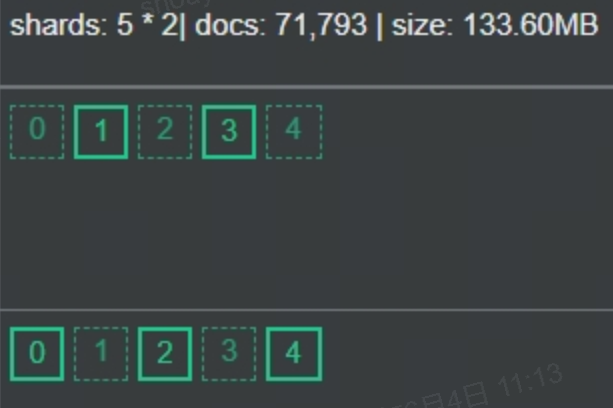 早期版本上,默认的主副本分片
早期版本上,默认的主副本分片
默认情况下,假设Elasticsearch中的每个索引分配5个主分片和1个复制。这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样每个索引总共就有10个分片。
注意:在索引创建之后,你可以在任何时候动态地改变副本的数量,但是你不能再改变正本分片的数量。这里说的,是正本的数量。
在Elasticsearch中,索引创建后的分片调整规则如下,
- 副本分片(
Replica Shards),可以动态修改- 随时调整:你可以在索引处于活跃状态时,随时增加或减少副本数量。
- 操作方式通过
Update Settings API即可立即生效,无需重建索引。 - 作用:增加副本可以提高搜索吞吐量和数据高可用性;减少副本可以节省磁盘空间。
1 2 3 4 5 6
PUT /my_index/_settings { "index": { "number_of_replicas": 2 } } - 主分片(
Primary Shards),创建后不可直接修改- 固定不变:主分片的数量在索引创建那一刻就永久确定了,无法通过简单的设置命令进行更改。
- 原因:
Elasticsearch使用hash(id) % number_of_primary_shards算法来决定文档存储在哪个主分片上。如果主分片数量改变,所有文档的路由位置都会失效,导致数据无法被正确检索。
如果必须改变主分片数量怎么办?
虽然不能直接修改,但可以通过以下两种间接方式实现(本质都是新建索引并迁移数据)。
Reindex API(重新索引):
- 创建一个具有新主分片数量的新索引。
- 使用
_reindex将旧索引的数据复制到新索引中。- 删除旧索引,并将别名指向新索引。
- 适用场景:任意改变分片数量,同时还可以修改
Mapping或数据结构。Split/Shrink API(拆分/收缩):
Split:将主分片数量倍增(如1→2,2→4)。要求原索引只读,且新分片数必须是原分片数的倍数。Shrink:将主分片数量减少(如4→2,2→1)。要求原索引只读,且新分片数必须是原分片数的因数。- 适用场景:仅调整分片数量,不改变数据结构,速度通常比
Reindex快。
ES集群角色
思考几个问题,
ES节点,默认有哪些角色?没有默认有哪些角色?- 怎么样用不同的配置参数,来组合出不同的角色?
- 从集群规划的角度,要分为哪些环境?不同的环境要有哪些不一样的规划?
以一个30个节点的集群(中型)为例,介绍一下ES的集群角色,每一个框代表的是一个节点。
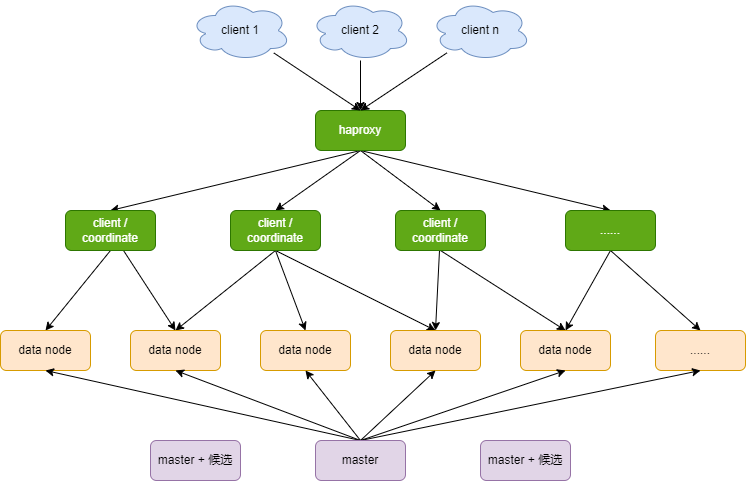 先以ES中型集群为例
先以ES中型集群为例
- 元数据,是由
master node来管理的,有两个备用的master节点,来做master高可用。 - 大量的节点,是
data node,做文档的索引和检索,占了绝大多数节点的数量。 - 协调节点,可以根据系统吞吐量确定数量,比如
2、4、6… - 为了协调节点的高可用,增加
haproxy,或者nginx组件,放在前面,供客户端使用。 - 怎么没有
Ingest Node?这个角色可以单独用节点来做,也可以让协调节点来接任。
Master Node
主节点(Master Node),主要职责是控制整个集群的元数据。就像一窝蜜蜂里面的蜂王,控制整个集群,只有一个master node,不是多点的,就是单点的,有master node做集中的管理。
不同类型的集群不一样,Kafka中叫controller,RocketMQ中叫nameserver。
从资源占用的角度来说,master节点不占用磁盘IO和CPU,内存使用量一般,没有data节点高。
简单看下,元数据(metadata),包括比如索引的分片信息、主副本信息、分片的节点分配信息(路由分配)、index、type、Mapping、Setting全局配置等等。
Master eligible Node
候选主节点(合格节点)
思考:Master有一个节点,不就可以了吗?为什么搞那么多?
系统的任何一个环节,只要它是单点的,它就不是高可用,就意味着单点瓶颈。候选主节点,根本的目的就是高可用。
为什么有一个候选人不够,需要有两个或者更多候选,这个是选举的问题,在这里不过多展开。
候选节点,在没转正前,不会去管理集群的元数据,只是和主节点保持一个心跳来保活。Master一旦发生故障,它就会参与新一轮的Master选举。
从资源占用的角度来说,eligible节点比Master节点更节省资源,因为它还未成为Master节点,只是有资格成为Master节点。
Master Node配置,都是候选节点,至于最后谁是主节点,由系统自己选举产生。
Data Node
数据节点,管理所有的分片,不只是主分片,还有副本分片。
类似于Kafka里边的broker,不管是控制节点,还是非控制节点,都承担了数据节点的角色,都是管理topic下面的partition。RocketMQ里边,主分片和副本分片的管理,broker是分开的,管理主分片的broker就叫master broker,管理副本分片的broker就叫slaver broker。
ES集群里边,一个Node既能管理主分片,也能管理副本分片。
Data Node职责
- 写入,该节点用于建立文档索引,接收应用创建连接、接收索引请求;
- 查询,接收用户的搜索请求。
Coordinating Node
协调节点(路由节点/Client节点),这个角色,其他集群中就没有了。
如果要检索我是中国人,那么在30个分片里,假设每个分片都有包含我是中国人的文档,那这些文档都应该被检索出来。30个分片里,所有结果分为30个部分,由谁来做汇总合并?答案是,协调节点。
编排、打分、排序,排完后会有一个统一的合并结果,之后再挑选前面的条数给到用户。
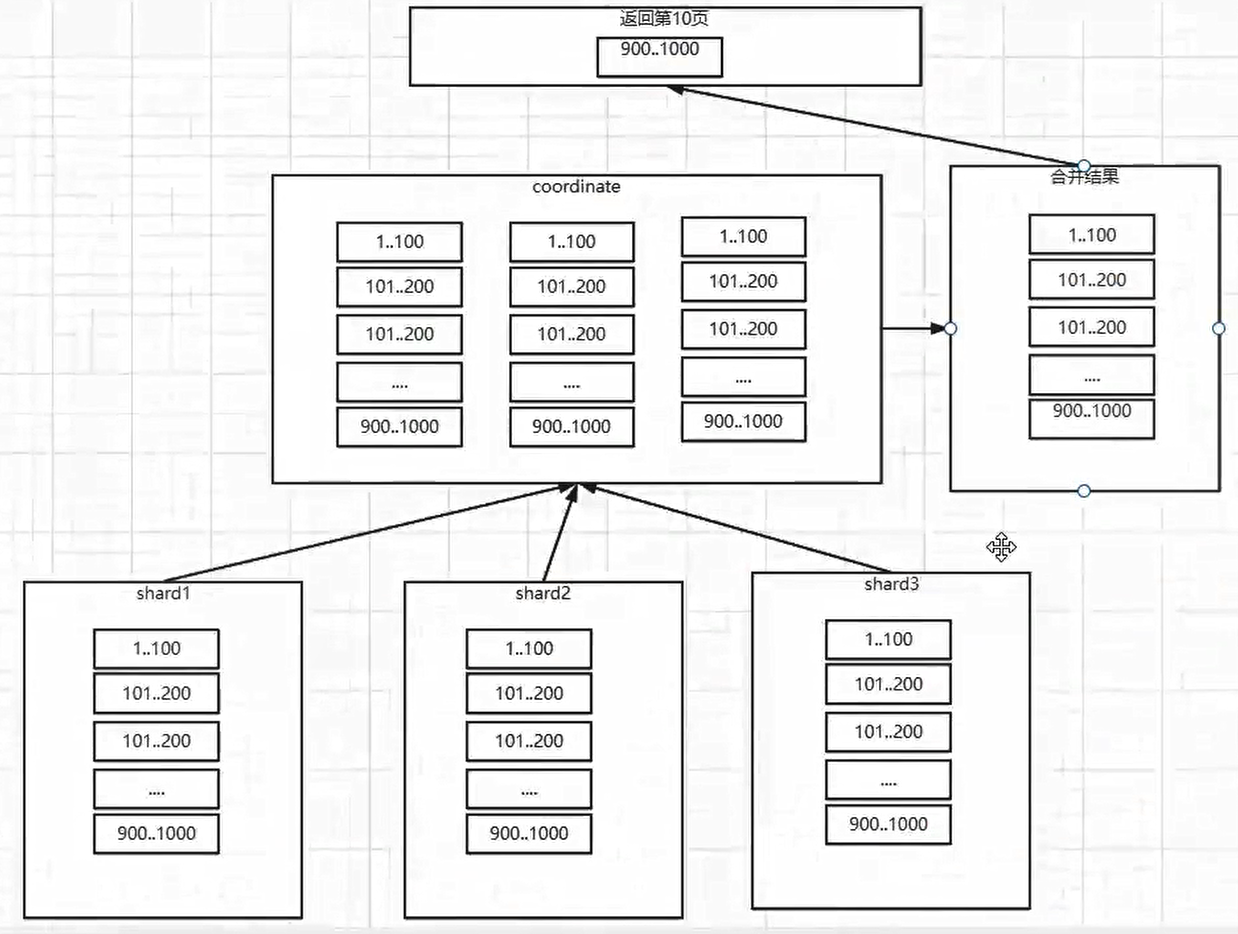 举个例子,直观说明协调节点的作用
举个例子,直观说明协调节点的作用
协调节点,本身不负责存储数据,即没有任何分片。主要是接收查询的请求,然后再做各个分片结果的合并。一次搜索分为两个阶段,有去有回,
query阶段,把请求分发到各个节点(分片);fetch阶段,把各个分片的数据做个结果的汇总,形成一个总体结果。
从资源占用的角度来说,协调节点,可当负责均衡节点,该节点不占用IO、CPU和内存。
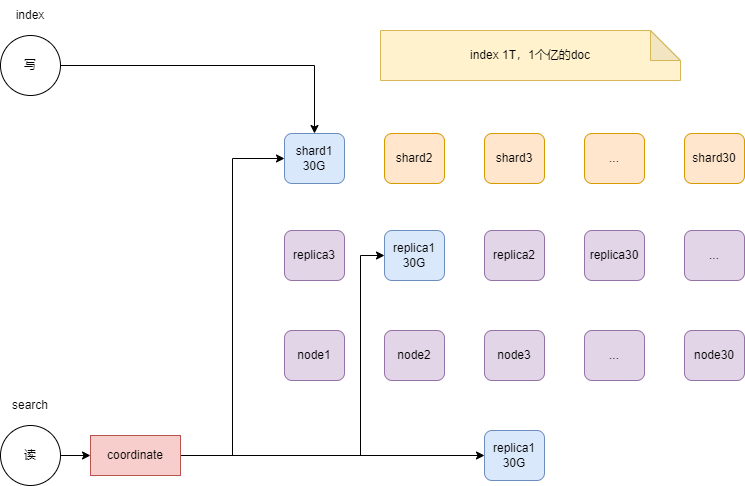 协调节点主要出现在搜索链路上发挥作用
协调节点主要出现在搜索链路上发挥作用
Ingest Node
转换节点,在写入的时候,对数据做预处理,比如数据过滤,数据类型转换等。
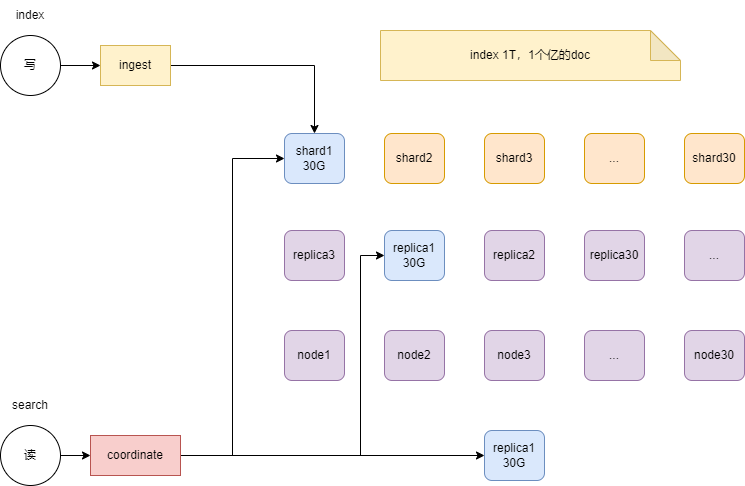 转换节点主要出现在写入链路上发挥作用
转换节点主要出现在写入链路上发挥作用
Tribe Node
部落节点,上面这些角色是ES节点通用的角色,任何一个ES节点可以承担上面角色里边的一个或者多个,通过简单的配置就可以实现。但这个角色,和上面的不一样。它不是在ES里边配置的,有专门的程序,另外一个包。超大集群,才会涉及到这个角色。
- 可以在查询过程中链接两个集群的数据,查询的数据将会汇总到
tribe节点,由tribe节点对数据进行整合再发送给client; tribe还可以写数据,但是这里有一个限制,就是写的索引只能是一个集群所有;- 如果写入两个集群同名索引,那么只能成功写入一个,至于写入哪一个可以通过配置偏好实现。
- 可以通过配置指明
tribe只能读,不能写。
配置ES节点角色
以一个30个节点的集群为例,介绍一下ES的节点角色如何配置。
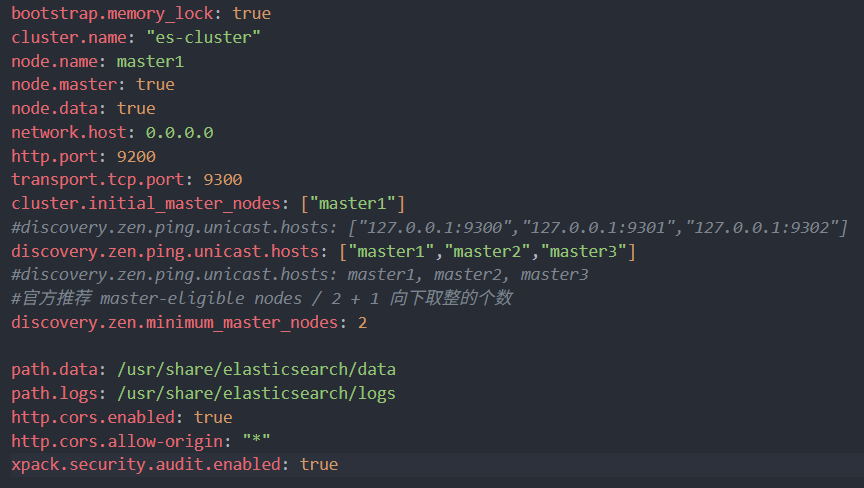 一个主节点的配置示例
一个主节点的配置示例
参数的四种组合
Master和Data两个角色,这些功能是由三个属性控制的。
node.masternode.datanode.ingest
这三个属性有四种组合,
node.master:这个属性表示,节点是否具有成为主节点的资格。- 注意:此属性的值为
true,并不意味着这个节点就是主节点。因为真正的主节点,是由多个具有主节点资格的节点进行选举产生的。所以,这个属性只是代表这个节点是不是具有主节点选举资格。
- 注意:此属性的值为
node.data:这个属性表示,节点是否存储数据。- 协调节点,没有专门的配置属性,配置如下,既不是候选主节点,又不是数据节点,就是协调节点。
1 2
node.master:false node.data:false
- 这里不配置为
false,节点也具有协调能力,如果全配置成false,则为专用协调节点。
- 这里不配置为
实际上,一个节点在默认情况下会同时扮演Master Node,Data Node和Ingest Node。
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| Master Eligible | node.master | true |
| Data | node.data | true |
| Coordinating only | - | 设置上面2个参数全为false,节点为专用协调节点 |
| Ingest | node.ingest | true |
节点的角色建议
不同环境,节点配置方式不同,
- 在开发环境、测试环境,一个节点可以承担多种角色;
- 生产环境中,需要根据数据量,写入和查询的吞吐量,选择合适的部署方式,建议设置单一角色的节点(
Dedicated node);
Elasticsearch的Christian_Dahlqvist官方解读,如下,
一个节点的缺省配置是候选主节点+数据节点两属性为一身。
对于3-5个节点的小集群来讲,通常让所有节点存储数据和具有获得主节点的资格。你可以将任何请求发送给任何节点,并且由于所有节点都具有集群状态的副本,它们知道如何路由请求。
通常只有较大的集群才能开始分离专用主节点、数据节点。对于许多用户场景,路由节点根本不一定是必需的。
专用协调节点(也称为client节点或路由节点)从数据节点中消除了聚合/查询的请求解析和最终阶段,并允许他们专注于处理数据。
这对集群在多大程度上有好处将因情况而异。通常我会说,在查询大量使用情况下路由节点更常见。
ES集群的部署架构
根据吞吐量和数据量,做一个集群的规划。
 集群的规划有很多的准则,先动手,再讲理论
集群的规划有很多的准则,先动手,再讲理论
按照小型ES集群、中型ES集群、大型ES集群、超大型ES集群的顺序,分别看下对应的部署架构是什么样的。
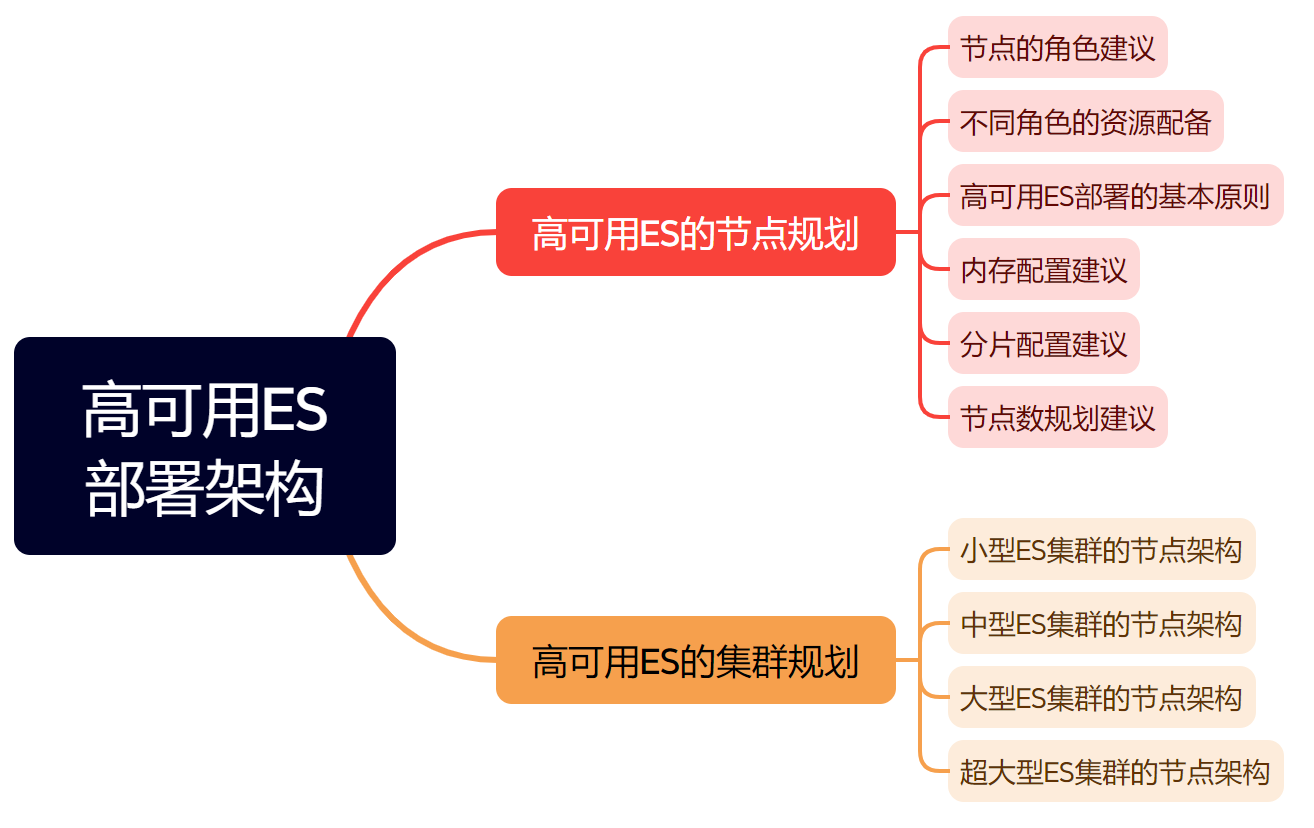
小型的ES集群(<10)的节点架构
就是3/5/7这种少于10个节点的集群。从角色和数据量的维度划分,对于3个节点、5个节点,甚至更多节点角色的配置,3个主节点+数据节点, 2个协调节点即可。
 小型集群架构图
小型集群架构图
- 负载均衡器有探活的功能,如果一个协调节点挂了,可以把挂了的节点直接摘掉。客户端直接通过负载均衡的
ip访问ES集群。读写都经过协调节点。 3个master node,实现了高可用。后面看3个data node怎么实现索引的高可用。- 这样一个小型的
ES集群,具备了基本的高可用、高并发的能力。
小型的ES集群的节点角色规划,
- 对于
Ingest转换节点,如果我们没有格式转换、类型转换等需求,直接设置为false。 3-5个节点属于轻量级集群,要保证主节点个数满足((节点数/2)+1)。- 轻量级集群,节点的多重属性如
Master & Data设置为同一个节点可以理解的。 - 如果进一步优化,
5节点可以将Master和Data再分离。
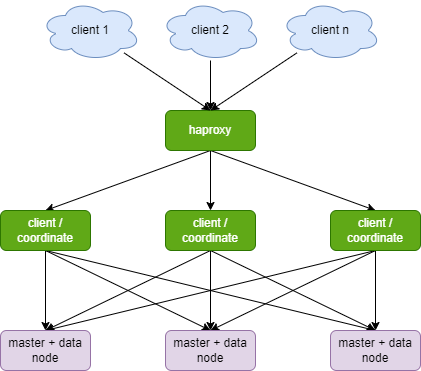
中型的ES集群(10-50)的节点架构
中型ES集群在架构上会做哪些调整?
中型集群架构图
首先,独立出来专用的master节点,资源不足的时候,也可以部分不独立,其中某一个master和data node合二为一,资源足够的时候就分开。
另外,coordinate node也可以独立,可以分3个或5个专门做协调节点,也不能太多,因为核心是data node用来放数据的。如果吞吐量比较大,就可以扩展协调节点的数量,做横向扩展。
ES数据库最好的高可用集群部署架构为,
- 三台服务器做
master节点 (可选) N(比如20)台服务器作为data节点(存储资源要大)N(比如5)台做coordinate/ingest节点(用于搜索结果合并,可以提高ES查询效率)
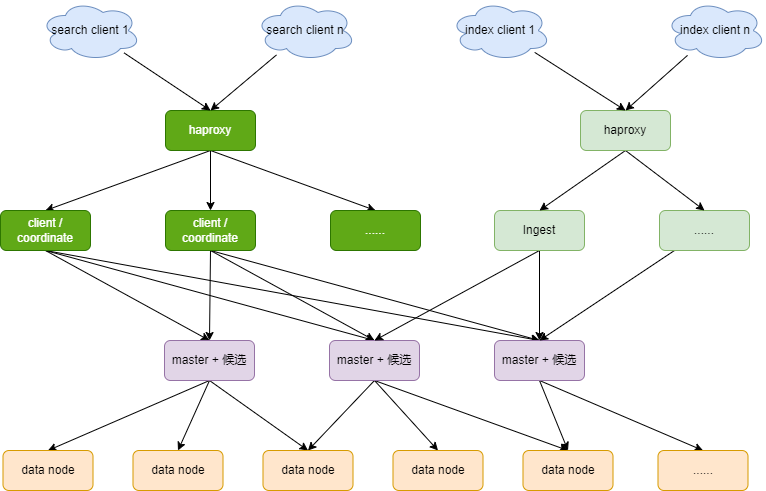
大型的ES集群的节点架构(50-150个节点)
 大型集群架构图
大型集群架构图
- 当流量规模和数据规模还在增大的时候,比如由
1TB增加至10TB,数据节点肯定要增加,数据节点一个分片官方推荐50GB(到顶了)。 - 大型集群,
master node一定要独立,但是也不用多,3个足够了。 - 另外,协调节点也做分离了。做索引的时候,有专用的
Ingest节点。 - 大型
ES集群,做到了完全的角色专用化。
ES数据库最好的高可用集群部署架构为,
- 三台服务器做
master节点 N(比如100)台服务器作为data节点(存储资源要大)N(比如5)台做coordinate节点(用于搜索结果合并,可以提高ES查询效率)N(比如2)台做ingest节点(用于数据转换,可以提高ES索引效率)
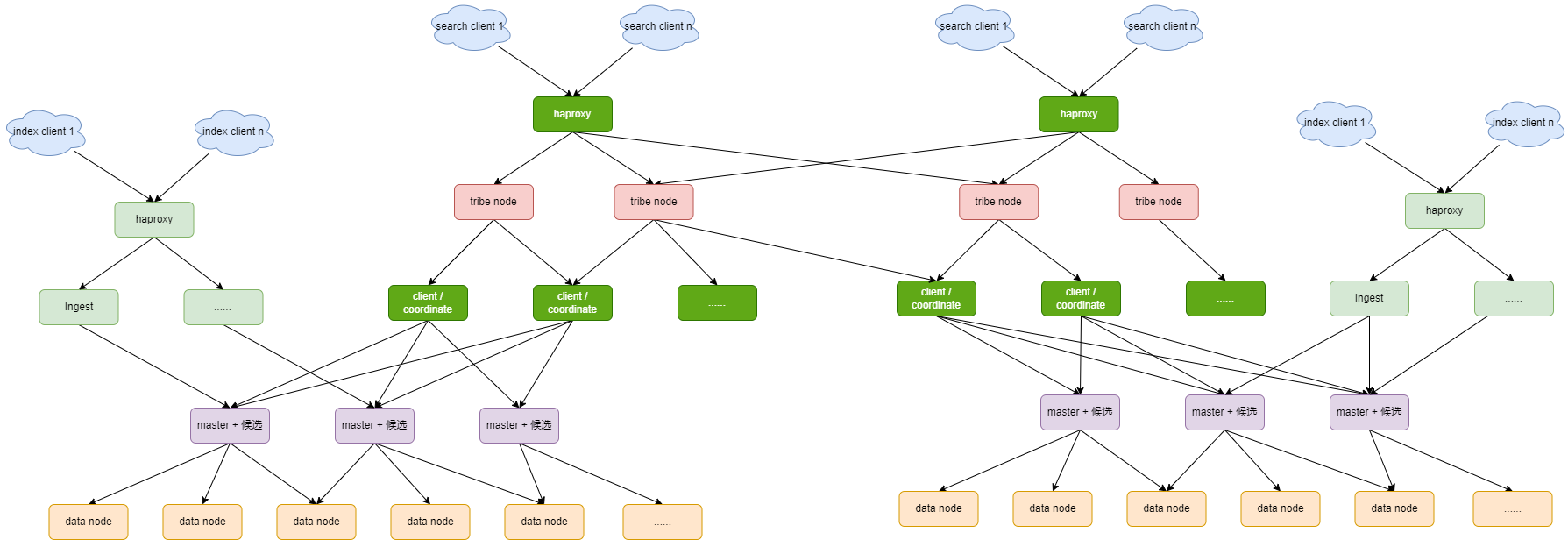
超大型的ES集群的节点架构(150个节点+)
 超大型集群架构图
超大型集群架构图
不能用一个集群搞定所有事情,要做集群的分裂。超大型ES集群不是一个ES集群,而是多个集群,多个大型集群合在一起,就是一个超大型集群。
为什么要做集群的分裂?master node的能力是有上限的,比如通信、线程池等方面,不能管太多的节点。ES集群的master node是集中式的管理,不是分布式的。
不同的集群之间,可以做统一的查询。结果的合并,不能通过协调节点了,有一个新的角色,就是部落节点(tribe node)。部落节点可以跨集群合并结果。
可以按照100个节点为单位,分成多个集群,通过tribe node连接,
- 单个
ES数据库最好的高可用集群部署架构为: - 每个集群,三台服务器做
master节点 N(比如50)台服务器作为data节点(存储资源要大)N(比如5)台做coordinate节点(用于搜索结果合并,可以提高ES查询效率)N(比如2)台做ingest节点(用于数据转换,可以提高ES索引效率)
以上集群规模,本质上一样,只是数量规模不同。
部署小型高可用ES集群
节点角色规划
看看这个case里面都包含哪些实例?
- 搜索查询的请求一般是经过
Client node来向Data node获取数据。索引请求首先请求Client/Coordinate节点,然后Client/Coordinate将请求分配到多个Data node节点完成一次索引查询。 - 后面可以设计专门的
Ingest node(预处理),前期可以通过Client node转发。 - 为了避免
Client/Coordinate的单节点故障,加上一个haproxy做负载均衡。
最终实例配置如下,
3个master+datanode2个coordinate1个haproxy1个kibana1个cerebro1个logstash
实际工程中,开发环境和测试环境、生产环境的部署区别
- 开发环境,全部部署在一个虚拟机,使用
docker compose编排; - 测试环境,部署在
3个虚拟机,使用docker compose编排,并基于docker swarm的overlay网络; - 生产环境,部署在
n个虚拟机,使用k8s编排,并基于k8s的overlay网络。
实操——开始部署
安装docker、docker-compose
 docker版本
docker版本
确认docker已经起来了
 docker状态
docker状态
在dockerhub选择合适的镜像,包括haproxy、elasticsearch-ik、kibana、cerebro、logstash
 dockerhub
dockerhub
拉取镜像到本地
 docker镜像
docker镜像
在编排启动前,创建文件目录结构
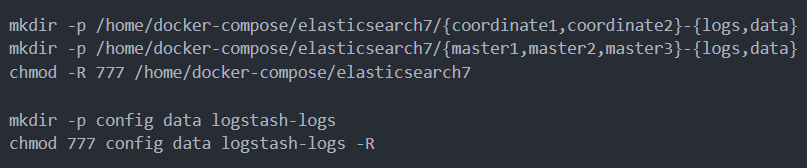 提前创建目录,包括配置、日志、数据
提前创建目录,包括配置、日志、数据
准备ES集群配置文件和docker-compose yaml配置
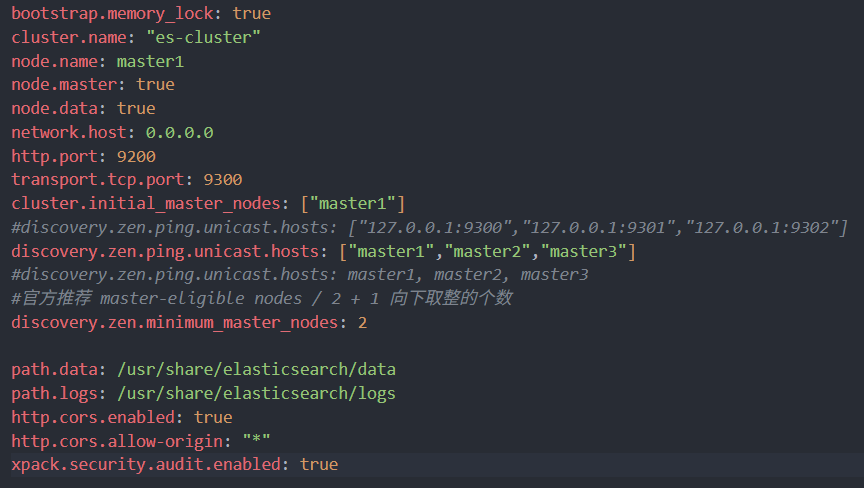 以Master Node + Data Node配置为例
以Master Node + Data Node配置为例
 logstash导入数据配置
logstash导入数据配置
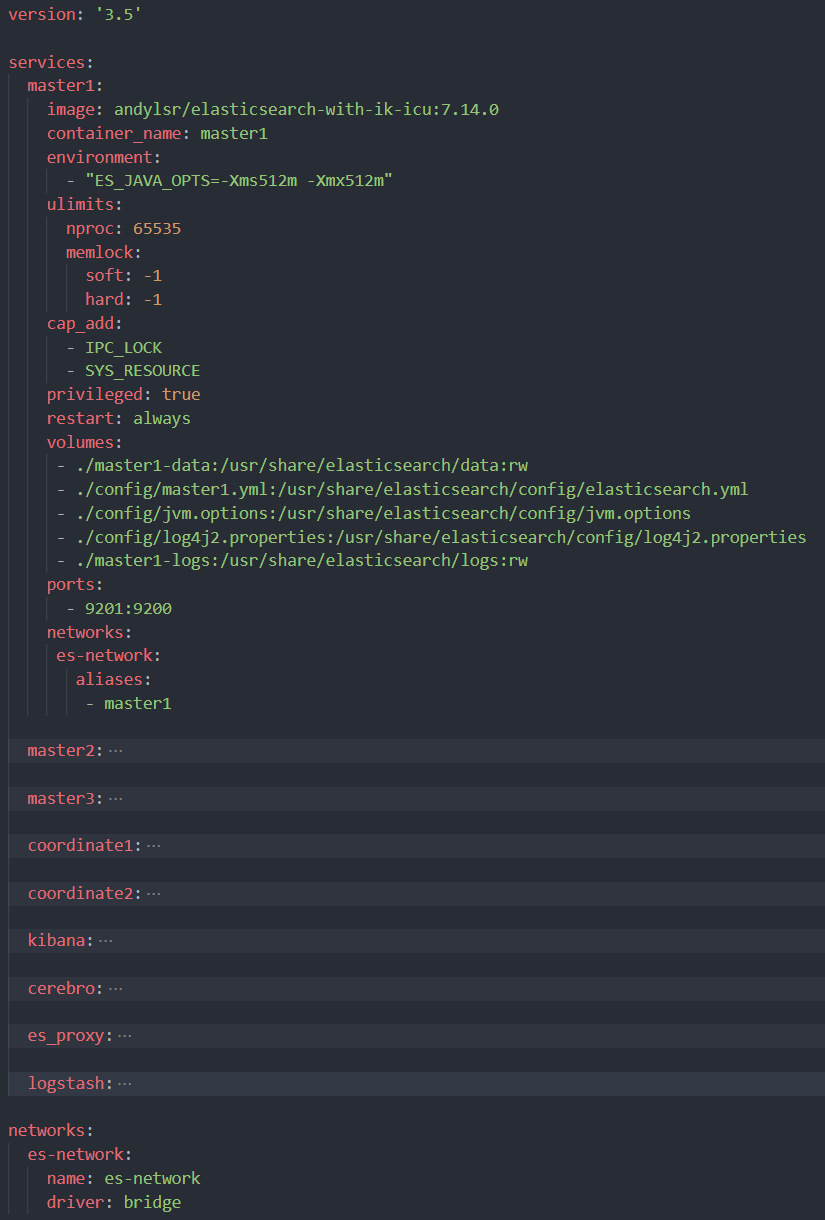 docker compose 编排配置,因测试机资源有限,内存配置暂为512M
docker compose 编排配置,因测试机资源有限,内存配置暂为512M
启动ES集群
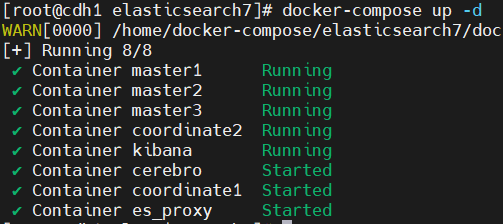 启动集群
启动集群
启动过程中可以观察日志
1
2
$ docker-compose log -f
$ docker logs -f logstash
验证服务是否起来了,没回复就表示成功起来了。
1
2
3
$ docker exec -it kibana curl -f http://127.0.0.1:5601
$ docker exec -it master1 curl -f http://master1:9200/
$ docker exec -it coordinate2 curl -f http://coordinate2:9200/
查看容器运行状态
 集群运行状态
集群运行状态
在控制台界面,没用负载均衡,所以没用haproxy。负载均衡是在程序里边访问ES的协调节点时使用的。
浏览器访问Kibana,如下,
 kibana
kibana
补充:部署过程中,会遇到
docker虚拟内存不够用,产生的报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]。docker虚拟内存不够用
原因是,docker默认分配的虚拟内存不足。
解决方法:调整用户mmap计数,否则启动时可能会出现内存不足的情况。
1
2
$ vi /etc/sysctl.conf
$ /sbin/sysctl -p # 立即生效
 修改docker虚拟内存
修改docker虚拟内存
Logstash导入数据
数据格式如下,
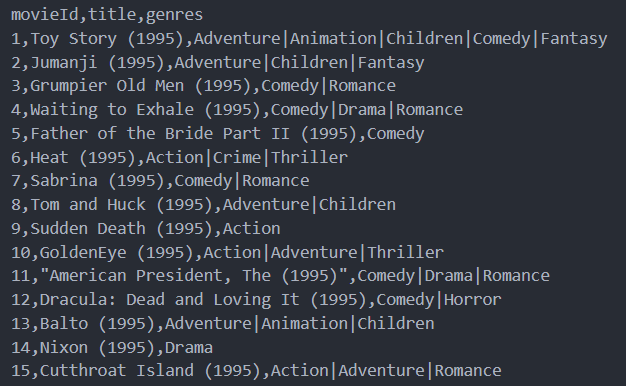 数据集格式
数据集格式
根据数据集格式,配置logstash.conf
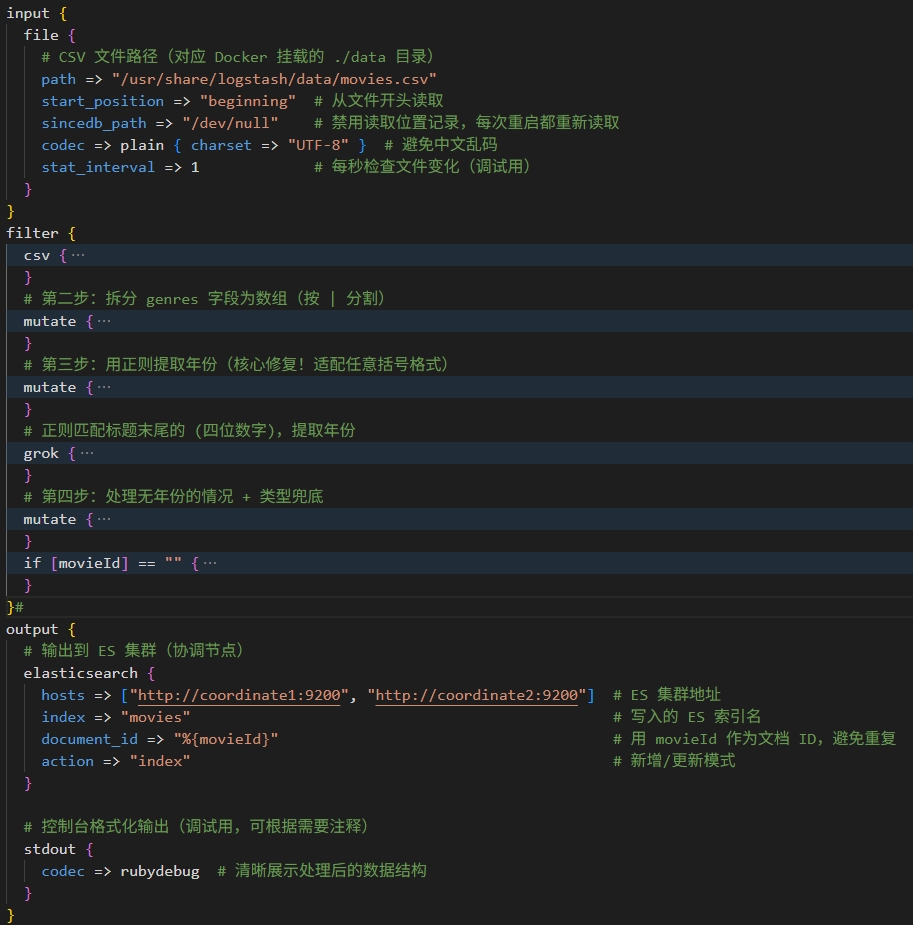 logstash解析数据集的配置
logstash解析数据集的配置
同步数据到ES
1
$ logstash -f logstash.conf
完成后,在Kibana查看結果
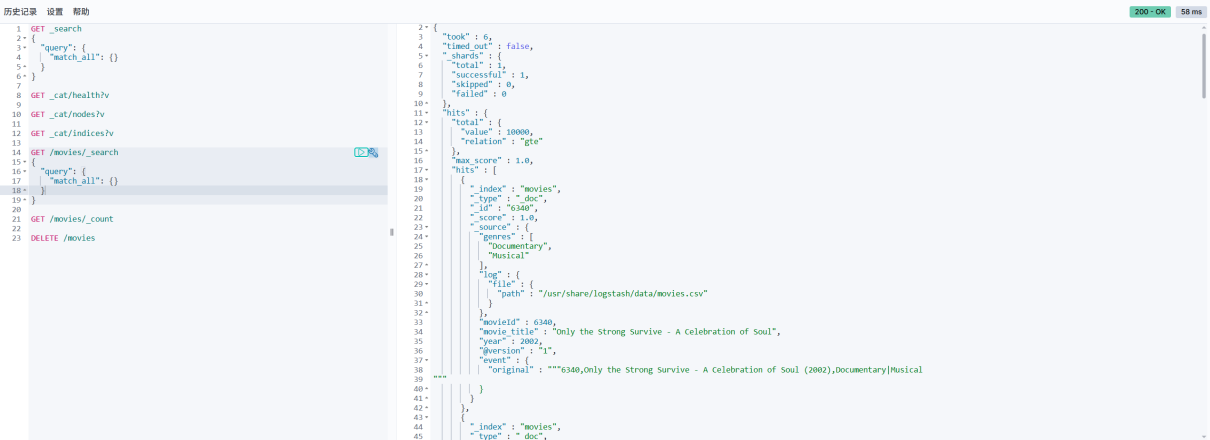 在kibana查看被同步的数据集
在kibana查看被同步的数据集
通过kibana检查集群节点node、集群索引index的健康状况、内存状况、CPU负载状况
管理ES集群有很多工具,常用的有kibana、cerebro(前身是head),cerebro可视化比较好,比如根据id来查文档,kibana可视化没有cerebro做的好,更多使用开发工具执行DSL。这里以kibana为例,来看一个ES集群怎么来看健康状况,以及节点的情况等等。
ES提供了一套_cat API , 可以查看ES中的各类数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
_cat/allocation #查看单节点的shard分配整体情况
_cat/shards #查看各shard的详细情况
_cat/shards/{index} #查看指定分片的详细情况
_cat/master #查看master节点信息
_cat/nodes #查看所有节点信息
_cat/indices #查看集群中所有index的详细信息
_cat/indices/{index} #查看集群中指定index的详细信息
_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
_cat/segments/{index} #查看指定index的segment详细信息
_cat/count #查看当前集群的doc数量
_cat/count/{index} #查看指定索引的doc数量
_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
_cat/recovery/{index} #查看指定索引shard的recovery过程
_cat/health #查看集群当前状态:红、黄、绿
_cat/pending_tasks #查看当前集群的pending task
_cat/aliases #查看集群中所有alias信息,路由配置等
_cat/aliases/{alias} #查看指定索引的alias信息
_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
_cat/plugins #查看集群各个节点上的plugin信息
_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
_cat/nodeattrs #查看单节点的自定义属性
_cat/repositories #输出集群中注册快照存储库
_cat/templates #输出当前正在存在的模板信息
检查集群的健康状况
1
GET _cat/health?v
 集群的健康状况
集群的健康状况
如何快速了解集群的健康状况? 通过查看status选项的值,
green: 所有primary shard和replica shard都已成功分配, 集群是100%可用的;yellow: 所有primary shard都已成功分配, 但至少有一个replica shard缺失。此时集群所有功能都正常使用, 数据不会丢失, 搜索结果依然完整, 但集群的可用性减弱,需要及时处理的警告。red: 至少有一个primary shard(以及它的全部副本分片)缺失。部分数据不能使用, 搜索只能返回部分数据, 而分配到这个分片上的写入请求会返回一个异常。此时虽然可以运行部分功能,但为了索引数据的完整性,需要尽快修复集群。
集群状态为什么是yellow?
- 当前只有一个
Elasticsearch节点,而且此时ES中只有一个Kibana内建的索引数据。 ES为每个index默认分配5个primary shard和5个replica shard,为了保证高可用,它还要求primary shard和replica shard不能在同一个node上。- 当前服务中,
Kibana内建的index是1个primary shard和1个replica shard,由于只有1个node,所以只有primary shard被分配和启动了,而replica shard没有被成功分配(没有其他node可用)。
查看集群中的节点个数
1
GET _cat/nodes?v
 集群的节点
集群的节点
也可以从操作系统的角度看下内存使用率,做下对比。可以看到,内存不够了,要不加内存,要不加节点。
 系统内存使用
系统内存使用
查看集群中的索引
1
GET _cat/indices?v
 集群的索引
集群的索引
通过cerebro可视化监控管理集群健康度、节点数、索引、分片、副本
 cerebro登录页
cerebro登录页
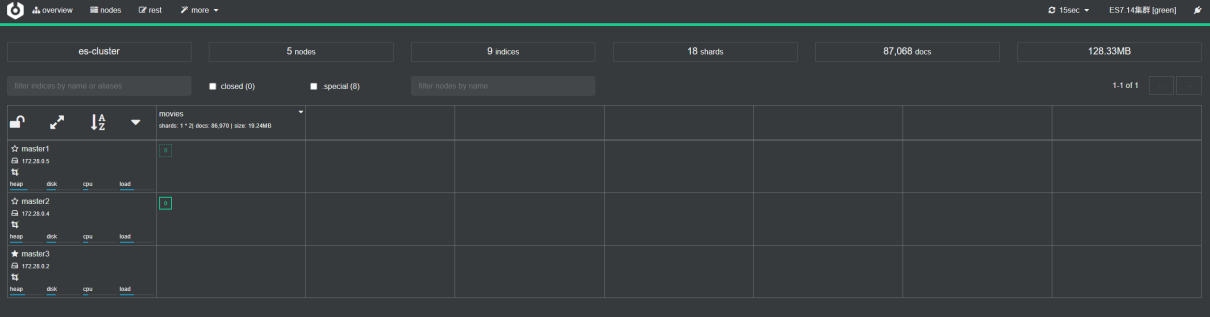 集群概况
集群概况
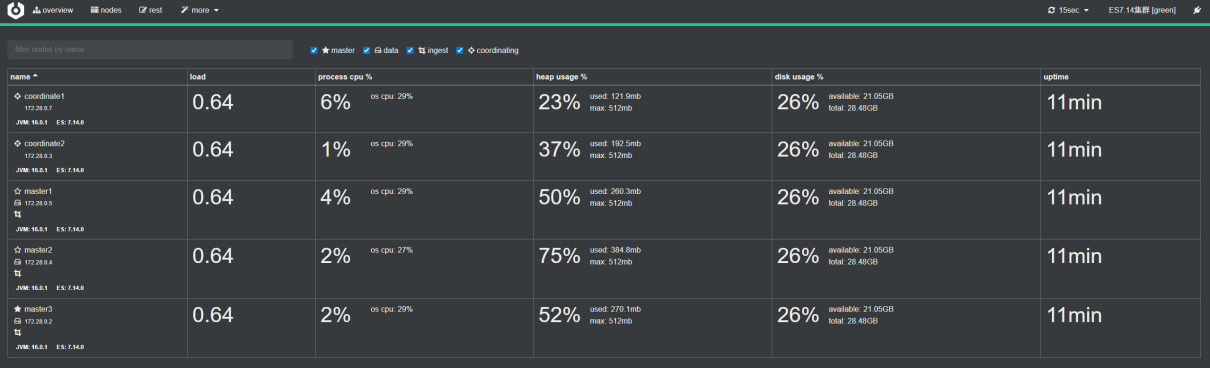 在cerebro查看集群的节点
在cerebro查看集群的节点