常见CNN架构
回顾上节
上节课我们讨论了不同的深度学习架构。我们可以看到,这些深度学习框架可以快速构建大型的运算网络,例如大规模神经网络和卷积神经网络,并且我们能容易的算出这些网络中的梯度,同时能计算所有中间变量的权重,并用来训练模型。此外,还能在GPU上高效运行。
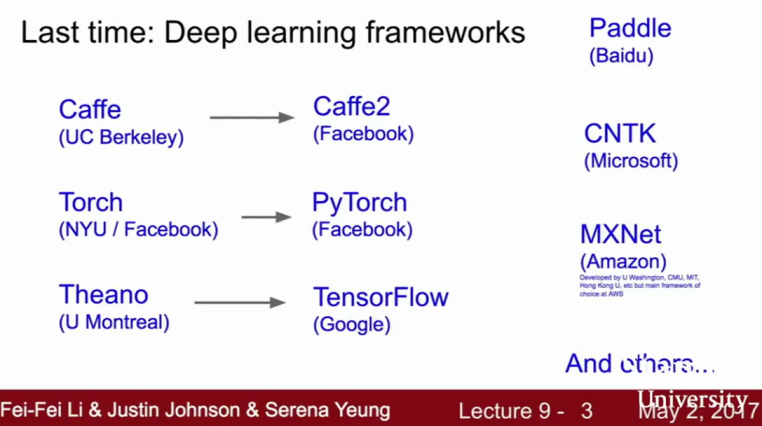 简单回顾:深度学习框架(来自cs231n)
简单回顾:深度学习框架(来自cs231n)
同时,我们能看到这些框架主要是调制神经网络中的前向层和后向层,在最后的模型架构中,我们只需要定义神经网络层的顺序。所以,使用这些工具我们能很快构建一个很复杂的神经网络架构。
 简单回顾:调制神经网络中的前向层和后向层(来自cs231n)
简单回顾:调制神经网络中的前向层和后向层(来自cs231n)
 简单回顾:定义神经网络层的顺序(来自cs231n)
简单回顾:定义神经网络层的顺序(来自cs231n)
常见的CNN架构
今天我们会讨论一些特定类型的卷积神经网络架构,它们在今天的前沿应用和研究中都有着很多应用。
 CNN架构(来自cs231n)
CNN架构(来自cs231n)
我们会深入探讨那些ImageNet比赛获胜者所用的最多的神经网络架构。按照时间顺序,它们是AlexNet、VGG、GoogleNet和ResNet,我们会深入地讨论这几个网络架构,然后会简单介绍一些其他的目前并不常用的架构。但它们从历史角度或者最近的研究领域来看都很有趣。
LeNet-5
首先我们来复习下,我们在上节课讨论了很久的LeNet,它可以看作是通信网络的第一个实例,并且在实际应用中取得成功。图上所显示的就是LeNet的结构,使用步长为1,大小为5*5的卷积核,来对第一层进行输入,并且同样的卷积层和池化层有好几层,以及在网络的最后有一些全连接层。LeNet在数字识别领域的应用方面取得了成功。
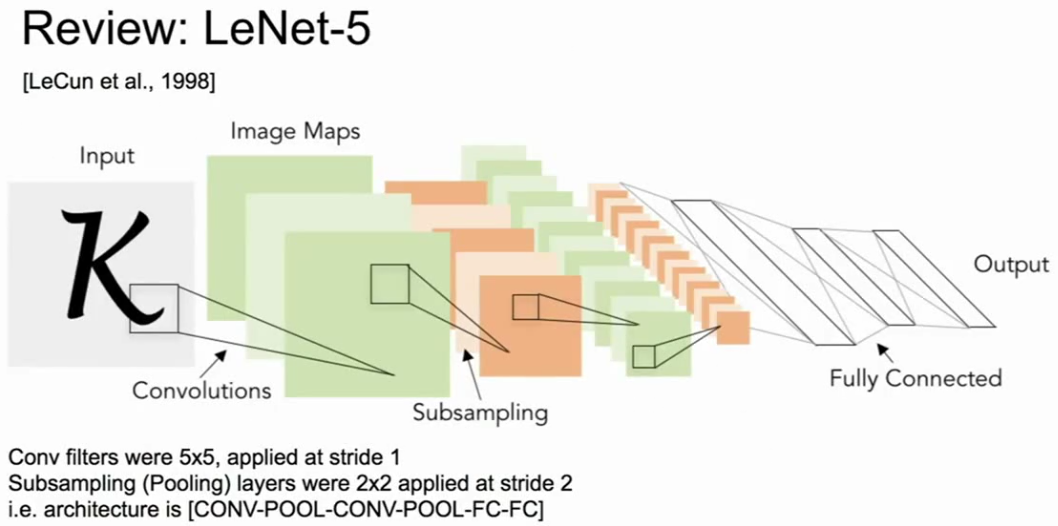 LeNet架构(来自cs231n)
LeNet架构(来自cs231n)
AlexNet
而2012年的AlexNet,可能你们在上节课已经了解到,是第一个在ImageNet的分类比赛中获得成功的大型卷积神经网络。AlexNet在2012年参加比赛,和之前的非深度学习架构相比,它大幅度地提高了识别准确率,从此卷积神经网络开始了大规模的研究和应用。
AlexNet的基础架构是卷积层,接着是池化层、归一化层,卷积-池化-归一化层,然后是一些卷积层,一个池化层,最后是一些全连接层。所以它看上去和LeNet很相似,我们刚刚也看到了区别在于总层数变多了,卷积层达到了五层,在最后的全连接层输出分类之前,又多了两层全连接层。
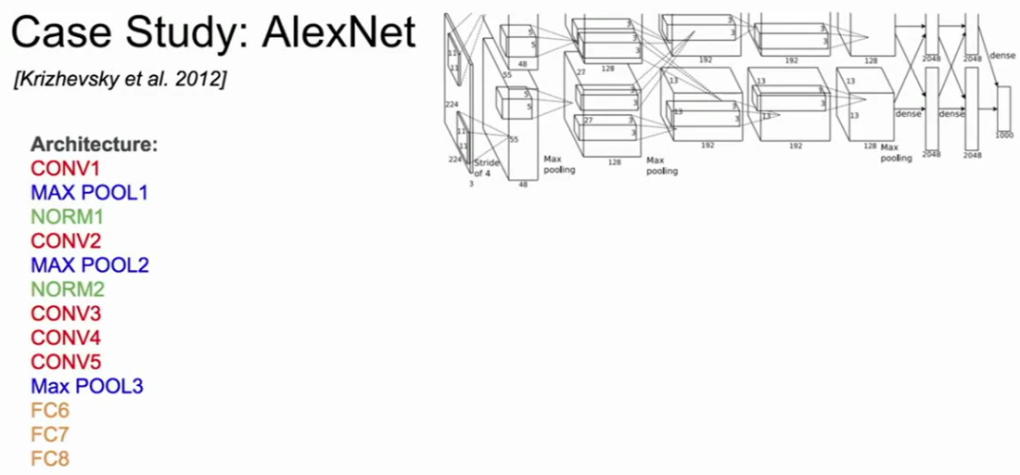 AlexNet架构(来自cs231n)
AlexNet架构(来自cs231n)
我们先感受下AlexNet的大小,如果我们观察AlexNet的输入,也就是ImageNet上的数据集227*227*3的图像矩阵,那么我们看到第一个卷积层有96个步长为4的大小为11*11的卷积核,所以我们可以思考一下第一层输出的数据体积是多少?
我们已经知道输入的大小,卷积核的大小,所以我们可以根据提示的公式得到卷积之后输出数据的维度,这个公式是图像尺寸减去卷积核尺寸除以步长并加一,所以最后的答案是55。那么有人猜出来卷积层最后输出的数据体积是多少么?55*55*96。所以我们的输出空间维度,元素每个都是55,我们有96个卷积核,所以卷积层之后的深度会是96。
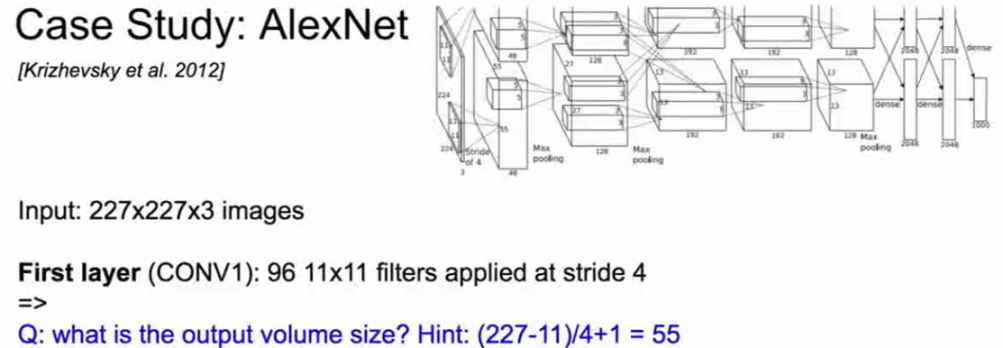 AlexNet架构conv1计算维度(来自cs231n)
AlexNet架构conv1计算维度(来自cs231n)
 AlexNet架构conv1输出维度(来自cs231n)
AlexNet架构conv1输出维度(来自cs231n)
那么这一层的所有参数数目呢?记住我们有96个11*11的卷积核,答案是(11*11*3)*96=35K。
每一个卷积核都会处理一个11*11*3的数据块,以为输入数据的深度就是3(RGB),这是每个卷积核参数的数量,还要乘以卷积核的总数96,所以第一层总共的参数有35000个。
 AlexNet架构conv1参数规模(来自cs231n)
AlexNet架构conv1参数规模(来自cs231n)
再来看第二层,也就是这个池化层,这里3*3的卷积核的步长为2,所以在池化层之后输出数据的体积是多少呢?27*27*96
 AlexNet架构pool1计算维度(来自cs231n)
AlexNet架构pool1计算维度(来自cs231n)
由于我们是按照步长为2进行池化操作,所以根据我们上次用过的统一的公式,输出数据的维度会是27*27,因为池化层会保留数据深度,所以我们输入的数据深度是96,那么输出的深度就是96。
这一层的参数总数是多少呢?池化层并没有参数。
Q:为什么池化层没有参数?
A:参数就是我们需要训练的权重,卷积层有我们需要训练的权重,但是对于池化层来说,我们只是观察池化区域,并且取最大值,所以这里并没有需要训练的参数。
可以继续重复这个操作,通过这个弄清楚每层的大小和参数。
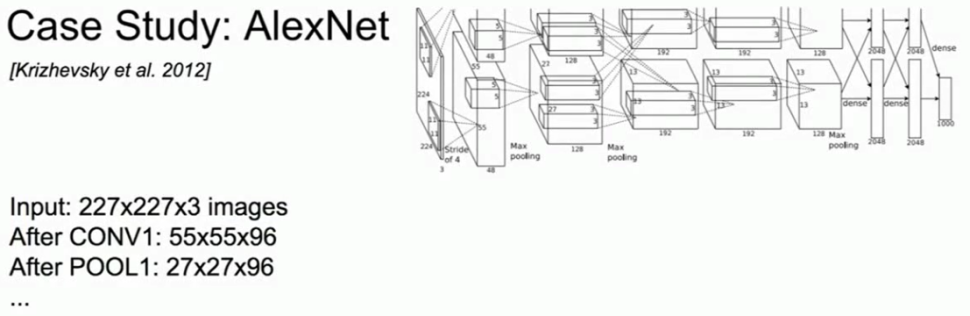 AlexNet架构每层的大小(来自cs231n)
AlexNet架构每层的大小(来自cs231n)
如果你坚持这样做的话,你可以看到这是你可以使用的最终架构,这是开始时的11*11的卷积核,然后是5*5和一些3*3的卷积核,这些都是之前接触过的非常熟悉的尺寸,接着在最后我们得到一些拥有4096个神经元的全连接层。最后的层是FC8,它连接一个softmax函数,进行1000个类别的ImageNet图像分类。
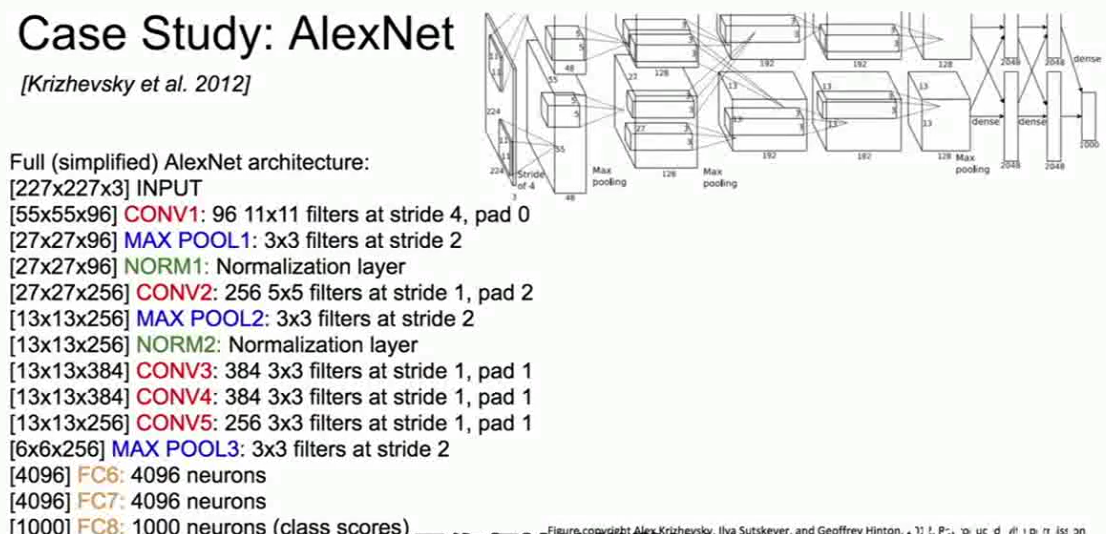 AlexNet架构全貌(来自cs231n)
AlexNet架构全貌(来自cs231n)
接下来深入一下这方面的细节,这是第一次使用ReLU非线性函数,之前提到过的最常用的非线性函数,它们使用本地响应归一化层,通过相邻通道来归一化响应,但是这些都已经被摒弃了。有研究表明它不太有效果,因为它增加了大量的数据,你可以从论文中发现更多的细节。但一些操作,如翻转、晃动、裁剪、颜色归一化都非常有用。当你开展类似例子中的工程时,这里会增加很多数据量,他们在128大小的批上使用dropout,通过带有动量的SGD来学习。这个部分在之前的课程中涉及过,一般由一个基本的学习率10的-2次方开始学习,每到高原期时,减少10倍,接着网络就能继续收敛,直到训练结束。还有一点权重衰减,为了得到好的结果,他们还使用了模型集成,训练多个模型,对他们取平均,从而获得性能上的提升。
 AlexNet超参设置(来自cs231n)
AlexNet超参设置(来自cs231n)
我想指出的另一件事情是,如果你看一下AlexNet的网络结构,它看起来有点像普通的convnet网络结构,我们可以看出相似,但有一点不同,这里分成两个不同的行或者列,向前传递。这里主要是因为历史原因,AlexNet曾经的训练平台是GTX580 GPUs,这是一种老的GPUs,只有3G的内存,它无法容纳整个神经网络,最后的解决方案是将网络拆分成两部分,在两个GPUs里运行,每个GPU只容纳半数的神经元,或者半数的特征映射图。以第一个卷积层为例,这里有55*55*96的数据输出,如果你仔细观察这个网络的图解,或者在实际的论文中放大,实际上每个GPU的深度只有48,它们直接把特征映射图拆分成两部分。
 AlexNet架构,分成两个不同的行或者列,向前传递(来自cs231n)
AlexNet架构,分成两个不同的行或者列,向前传递(来自cs231n)
大多数层都是这样,比如第1 2 4 5卷积层,你可能会想把相同GPU上的特征映射图作为输入,但是只有一半的特征映射图在相同的GPU上,所以你无法看到完整的96个特征映射图。把48个特征映射图作为第一层的输入。
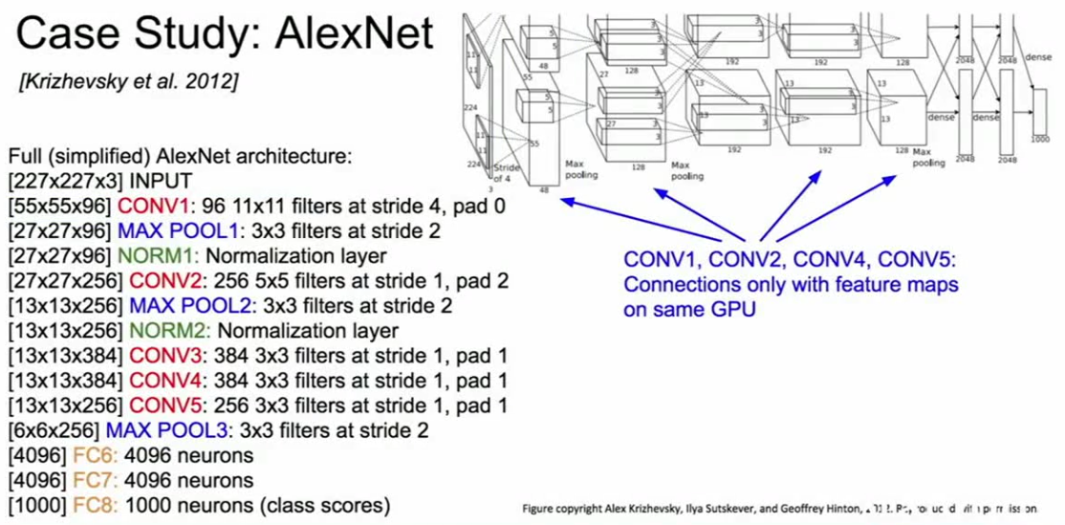 第1 2 4 5卷积层(来自cs231n)
第1 2 4 5卷积层(来自cs231n)
然后是第三个卷积层,以及第6 7 8个FC层,在这里GPUs相互通信,所以在前一层中,所有的特征映射图之间都有相互连接,并且存在跨GPUs的通信,并且每个神经元都被连接到上个神经元的深度。
 第6 7 8个FC层(来自cs231n)
第6 7 8个FC层(来自cs231n)
Q:为什么说是完整的简单的
AlexNet网络架构?
A:这样说的原因是,我只介绍了主要的脉络,并不是没有全部细节,例如这是架构中的主要框架、步长等,但如正则化层等细节,这里并没有写出来。实际上的数字是227。
Q:从直观上理解为什么
AlexNet比之前的网络要好,不同于之前的网络?
A:这是一个非常不同的结构,这是一个基于深度学习的网络架构。
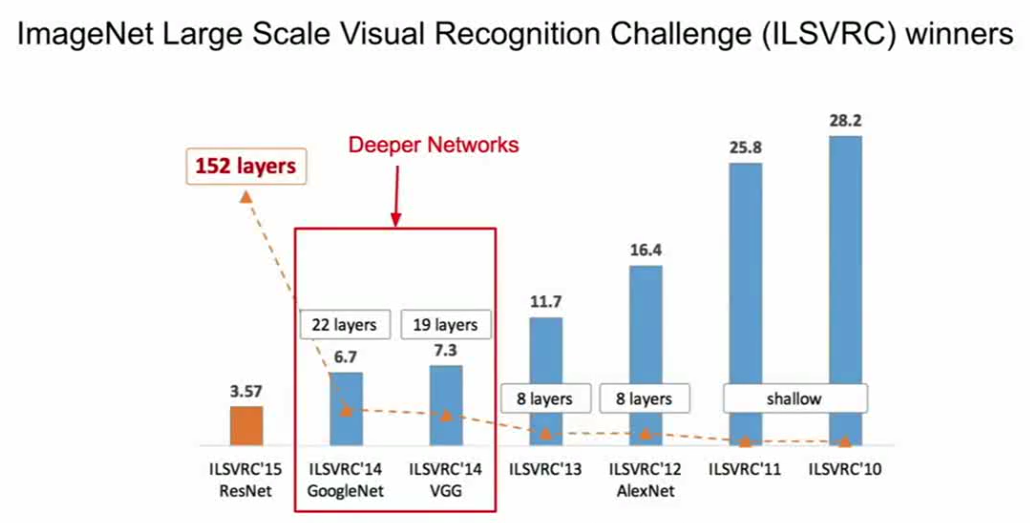 ILSVRC(来自cs231n)
ILSVRC(来自cs231n)
VGGNet
 VGGNet架构(来自cs231n)
VGGNet架构(来自cs231n)
VGG的思想是一个非常深的网络,包含非常小的卷积核。它们从AlexNet的8层扩展到VGGNet的16到19层,关键点是它们保持小的卷积核,只用3*3的卷积,基本上最小的卷积大小。网络只关注相邻的像素,网络保持这个简单的3*3的架构定期下采样,这种思想贯穿整个网络,获得了ImageNet最高的7.3的错误率。
问题是为什么最小的卷积核?
当使用小的卷积核可以得到比较小的参数量,然后可以利用堆栈更多的参数,不使用大的卷积核,只使用小的卷积核让我们可以尝试更深层的网络和更多的卷积核。最终的效果比一个7*7的卷积核有效接受范围更好些。
 VGGNet架构为什么最小的卷积核(来自cs231n)
VGGNet架构为什么最小的卷积核(来自cs231n)
又有一个问题,
3*3卷积层步长1的有效接受范围是什么?
如果用3*3的卷积层,步长为1,可接受范围是输入的全部区域,全部空间区域保证了3层网络的顶层。
 VGGNet架构3*3卷积层步长1的有效接受范围(来自cs231n)
VGGNet架构3*3卷积层步长1的有效接受范围(来自cs231n)
现在我们看看这里的整个网络,这里有很多你可以使用。进一步,如果所有的尺寸和参数数目用和AlexNet计算的例子采用同样的方式,这是一个很好的训练,我们可以发现用同样的方式得到几个卷积层,一个池化层,更多的卷积层,池化层,更多的卷积层,这样下去,我们继续看。如果数一下卷积层和全连接层的数量,对于VGG16来说就有16层。
 VGGNet架构全貌(来自cs231n)
VGGNet架构全貌(来自cs231n)
VGG19有非常相似的架构,只是这里有更多的卷积层。这个网络全部内存的使用情况通过一次前向传播计算所有的内存量,它们被写成总数的形式,像我们之前计算那样,如果每个数字是4个字节,每张图片大约就有100M,这是非常大的内存使用,这仅仅是对前向传播。当你做后向传播时还要保存更多的参数,这对内存来说压力很大,每张图片100M,如果总内存是5G,你最多也只能存50张图片。在这个网络中,我们总共的参数有1亿3千8百万个,而AlexNet有6千万个。
GoogleNet
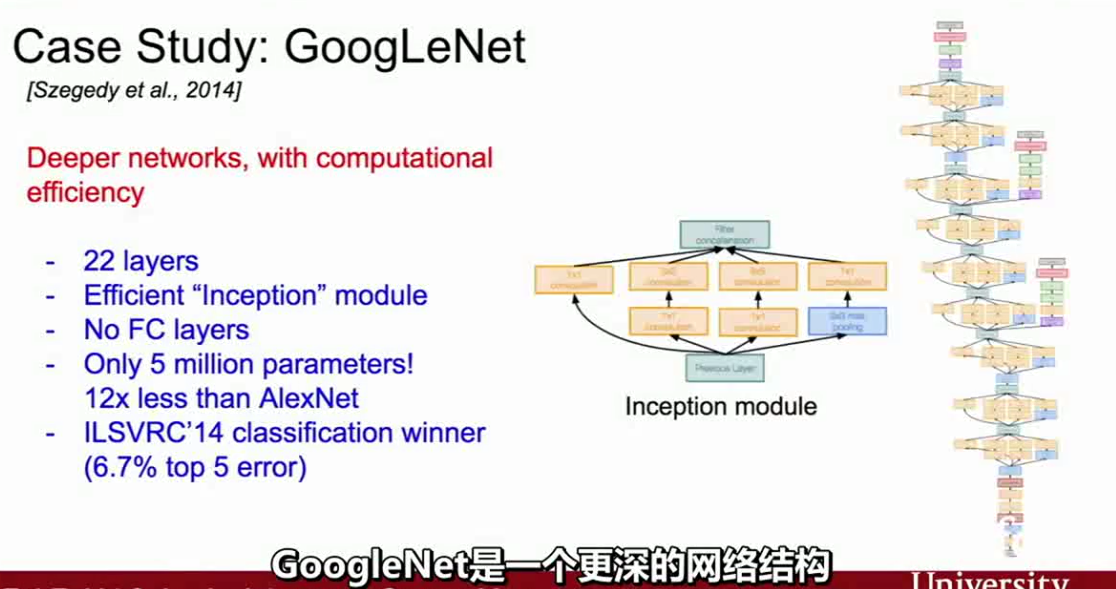 GoogleNet架构(来自cs231n)
GoogleNet架构(来自cs231n)
在GoogleNet中有一个很好的方法,通过增加一层瓶颈层并且尝试在卷积运算之前降低特征图的维度,在我们需要消耗昂贵运算里的卷积层之前。刚才的1*1的卷积运算,他读入你的输入,并且在每一个空间位置上执行了一个点积运算,他所做的是维持了空间维度的一致,但是他能减小深度通过将你的输入深度投影到一个更低的维度,它就像对你的特征图进行了一次线性组合。
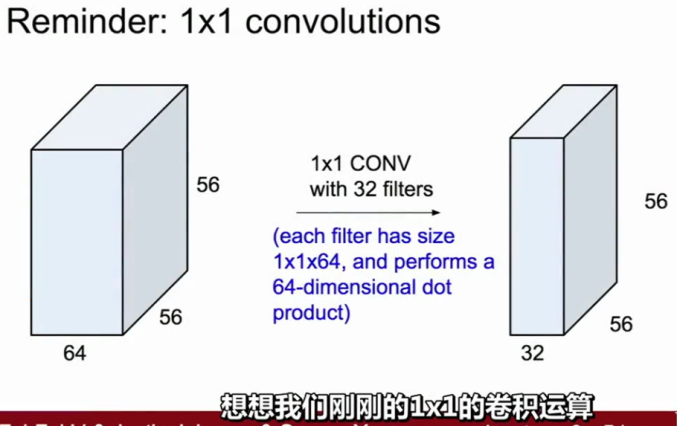 1*1卷积核(来自cs231n)
1*1卷积核(来自cs231n)
主要思想是降低你的深度,所以Inception模块先做1*1卷积,然后再把结果堆叠起来给下一个模块。为了减轻昂贵的计算力,在3*3和5*5卷积层之前,它会先通过一个1*1的卷积层,在池化层之后它也会经过一个额外的1*1的卷积层,所以这些就是添加进来的1*1的瓶颈层。这样做减少了进入卷积层的输入。
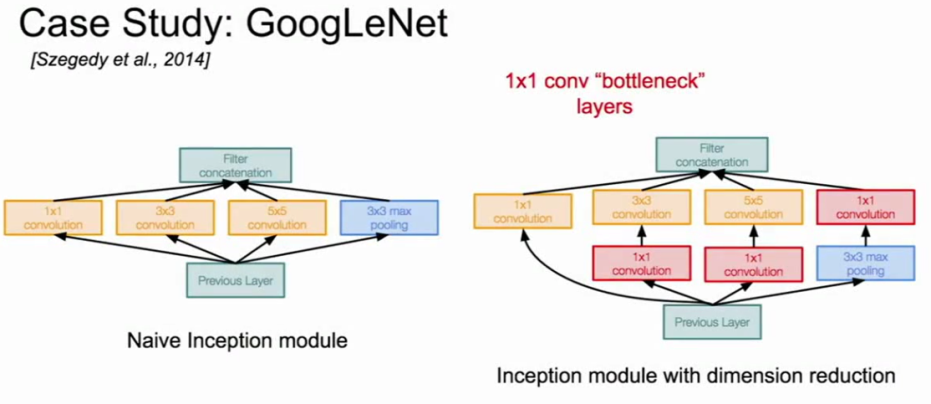 减少了进入卷积层的输入(来自cs231n)
减少了进入卷积层的输入(来自cs231n)
ResNet
这个想法是深度网络的一次革命,我们是在2014年开始增加深度,现在已经出现比这个深度大得多的模型,它有152层,即ResNet(残差)网络。
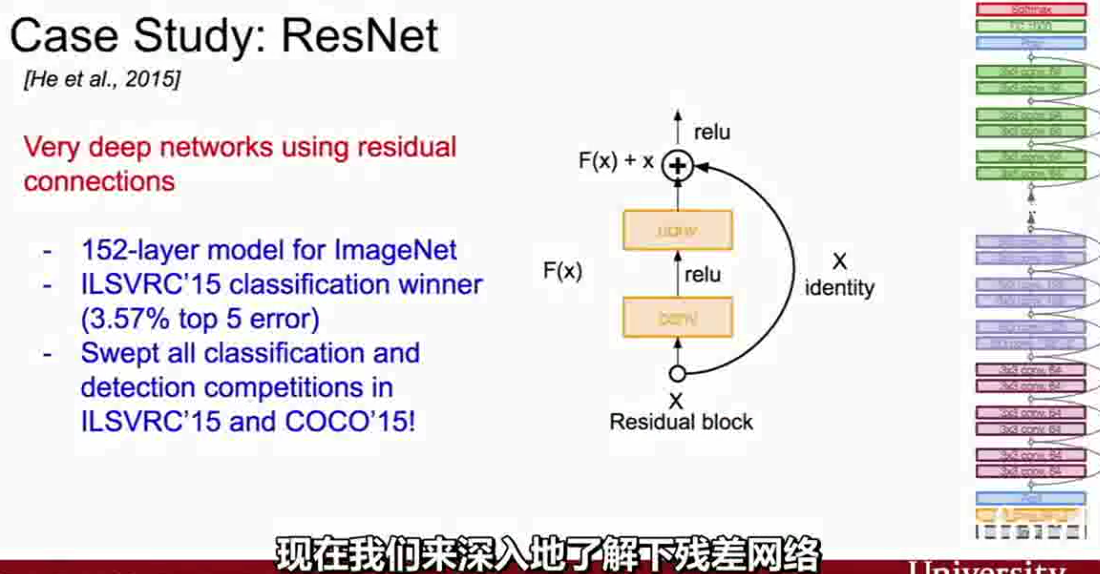 ResNet架构(来自cs231n)
ResNet架构(来自cs231n)
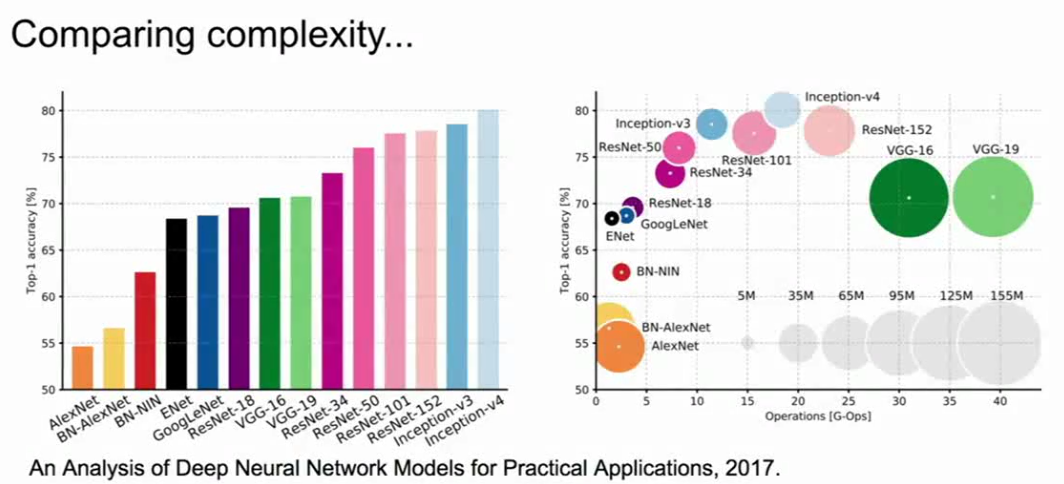 网络架构复杂性对比(来自cs231n)
网络架构复杂性对比(来自cs231n)
总结
 CNN架构总结(来自cs231n)
CNN架构总结(来自cs231n)
下面是一款游戏,称之为训练游戏,这是一个很酷的基于浏览器的游戏体验,可以进入并交互式地训练神经网络,并在训练过程中调节超参数,这应该是是一种很酷的供你去练习的交互方式,我们之前讲过的一些超参数调优技巧,可以更直观地了解这些超参数如何在实践中为不同的类型的数据集工作。
 训练游戏(来自cs231n)
训练游戏(来自cs231n)