The Illustrated Transformer(翻译版)
Overview
Attention is All You Need论文原文中介绍,Transformer模型,完全摒弃了RNN和CNN的先验假设,它是一个只使用了Attention机制的Seq2Seq模型,通过Attention机制连接两部分——Encoder和Decoder完成Seq2Seq任务。
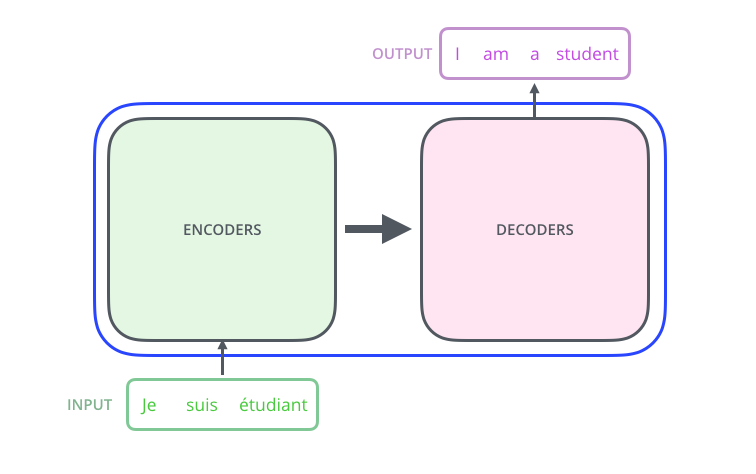 Transformer seq2seq简图
Transformer seq2seq简图
Transformer的特点
- 无先验假设,相比于
CNN和RNN,优点是能更快地学到无论长时还是短时的关联性。CNN的先验假设,是局部关联,Transformer对相对位置不敏感,可以并行计算;RNN的先验假设,是有序建模,Transformer需要位置编码来反映位置变化对于特征的影响,对绝对位置不敏感;- 先验假设越多,人为注入经验,模型更容易学,需要的数据量就越低;
- 数据量的要求与先验假设的程度成反比。
- 核心计算在自注意力机制,序列越长,计算复杂度是平方增长的。
RNN中,有序建模,递归地去算,每次计算计算量是固定的;- 有很多工作,是去降低复杂度,要降低就得注入先验假设,比如算注意力不是每个位置都算,局部关联或者单调性;
- 要用好
Transformer模型,需要根据不同的任务,去注入一些任务相关的先验假设,比如在注意力机制、loss、模型结构上,根据这些先验假设,做些优化。
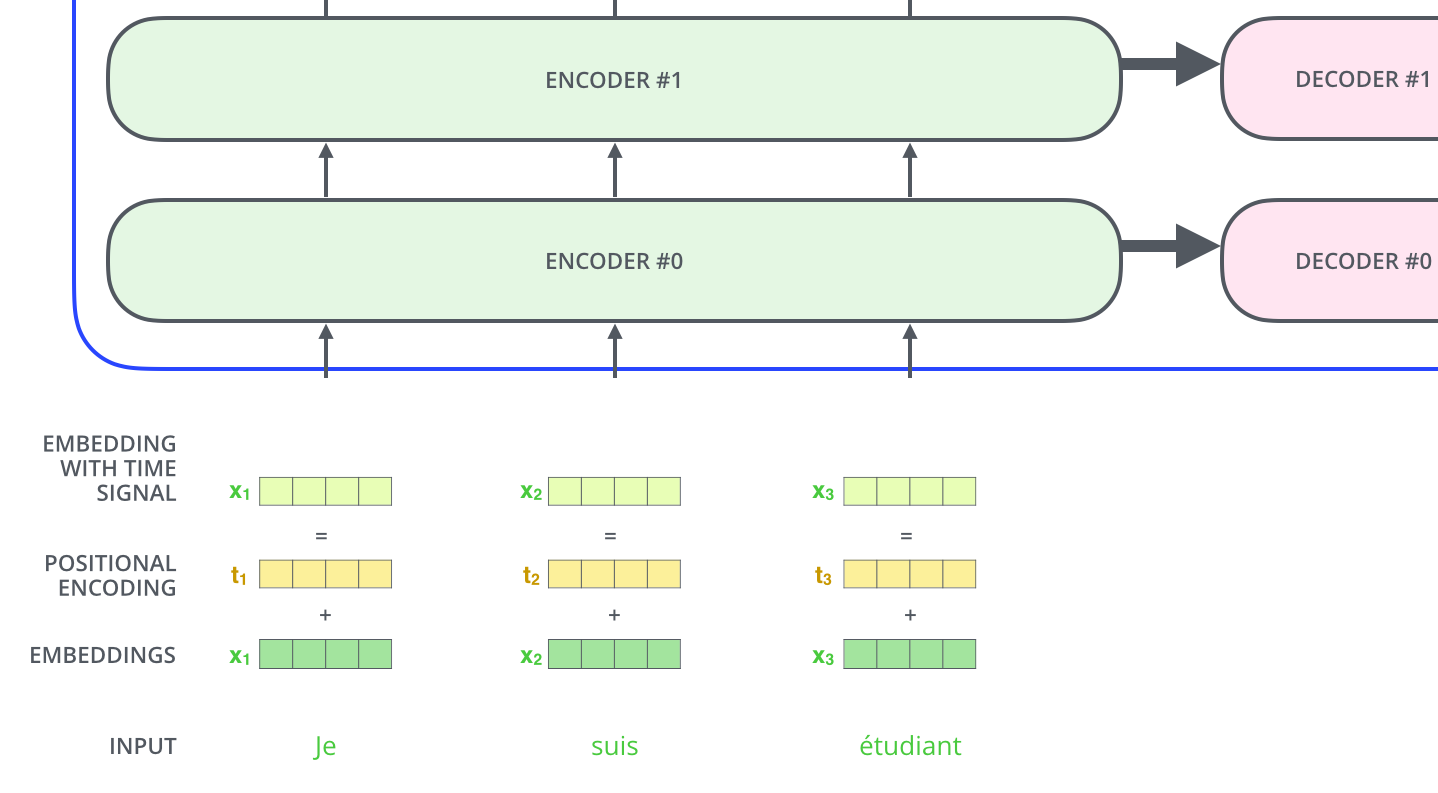
细分下上图,论文原文中Encoder部分由6个编码器堆叠组成,Decoder也是,这里的数字6并没啥特殊的含义,也可以尝试用别的数字,比如2。
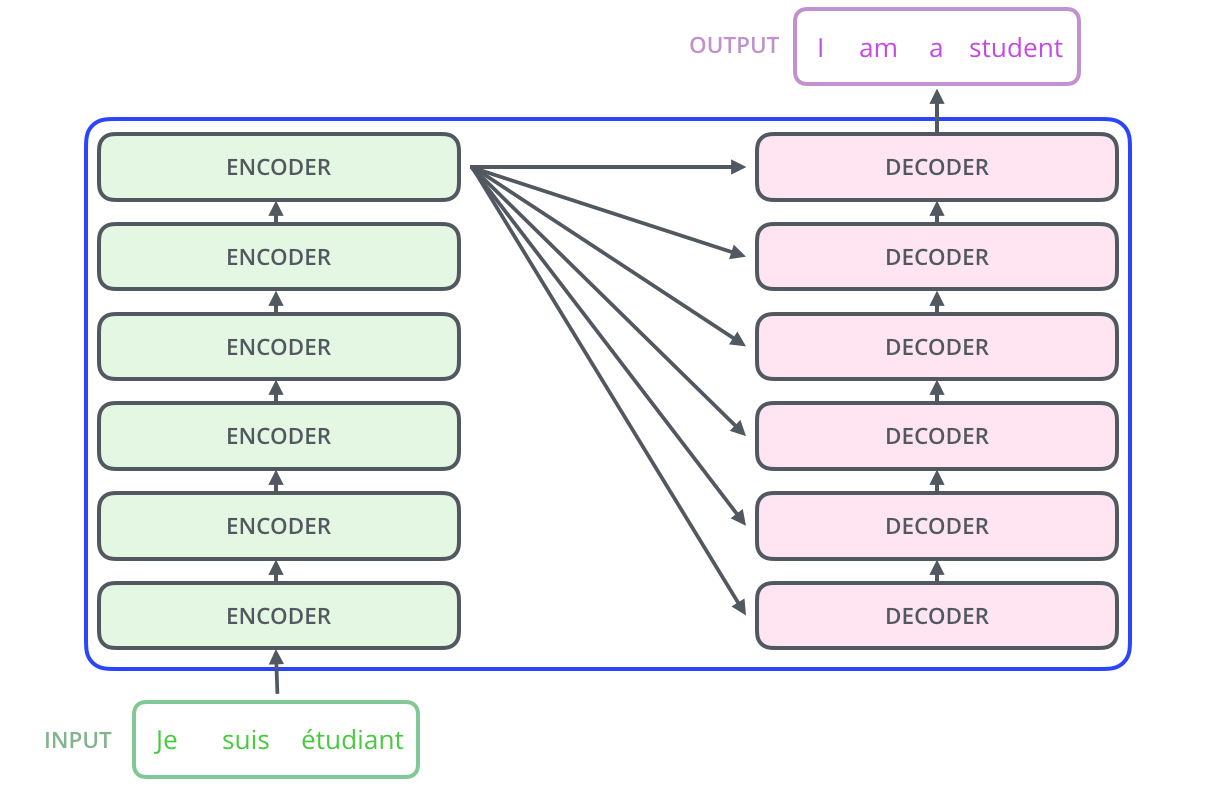 原论文中Transformer包含6个Encoder、6个Decoder
原论文中Transformer包含6个Encoder、6个Decoder
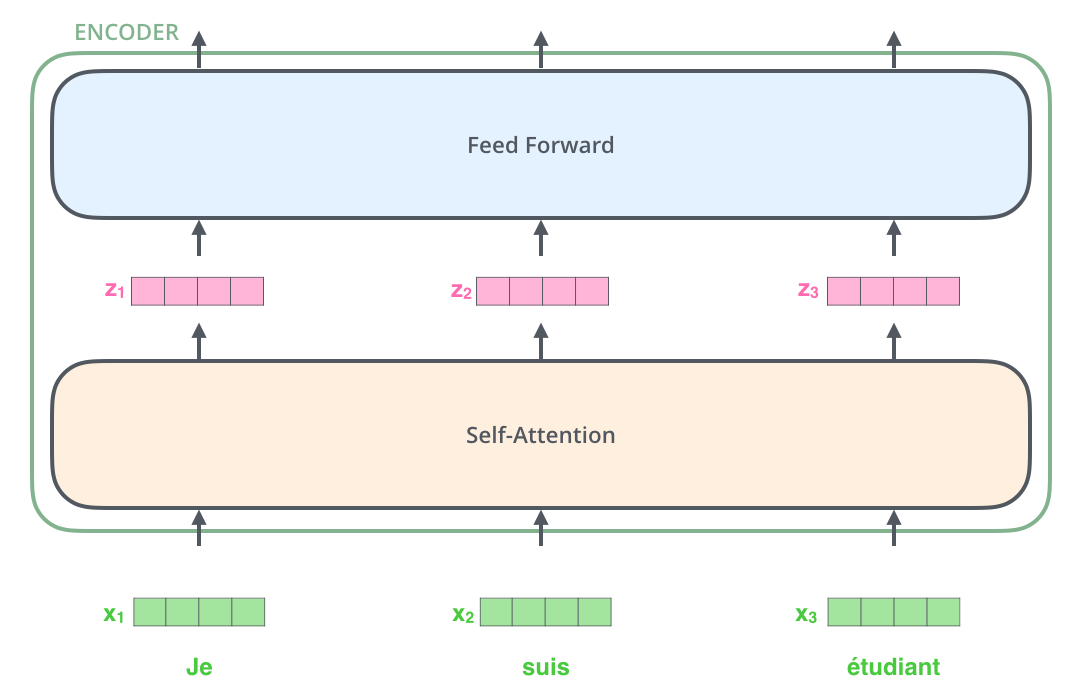
简单看下Encoder和Decoder的组成,
- 编码器的输入,先经过一个自注意力层,这一层能帮助编码器在编码特定单词时查看输入句子中的其他单词。自注意力层的输出被喂给
FFN,完全相同的FFN可以被独立地应用于每个位置。 - 解码器也包含这些层,只不过相比编码器,中间多一个注意力层,这一层帮助解码器专注于输入句子的相关部分。
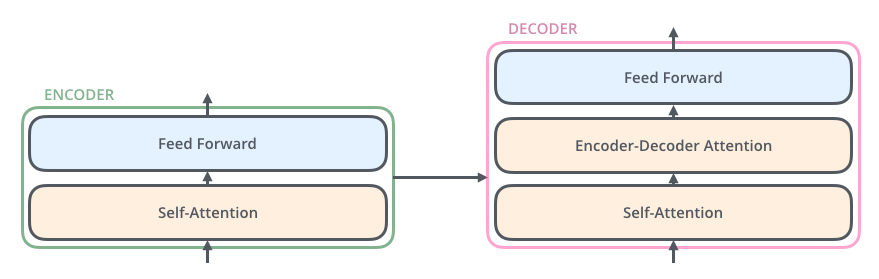 Transformer Encoder和Decoder组成简图
Transformer Encoder和Decoder组成简图
假设把前面的超参数字6改成2,就是一个由2个堆叠的编码器和解码器组成的Transformer,如下,
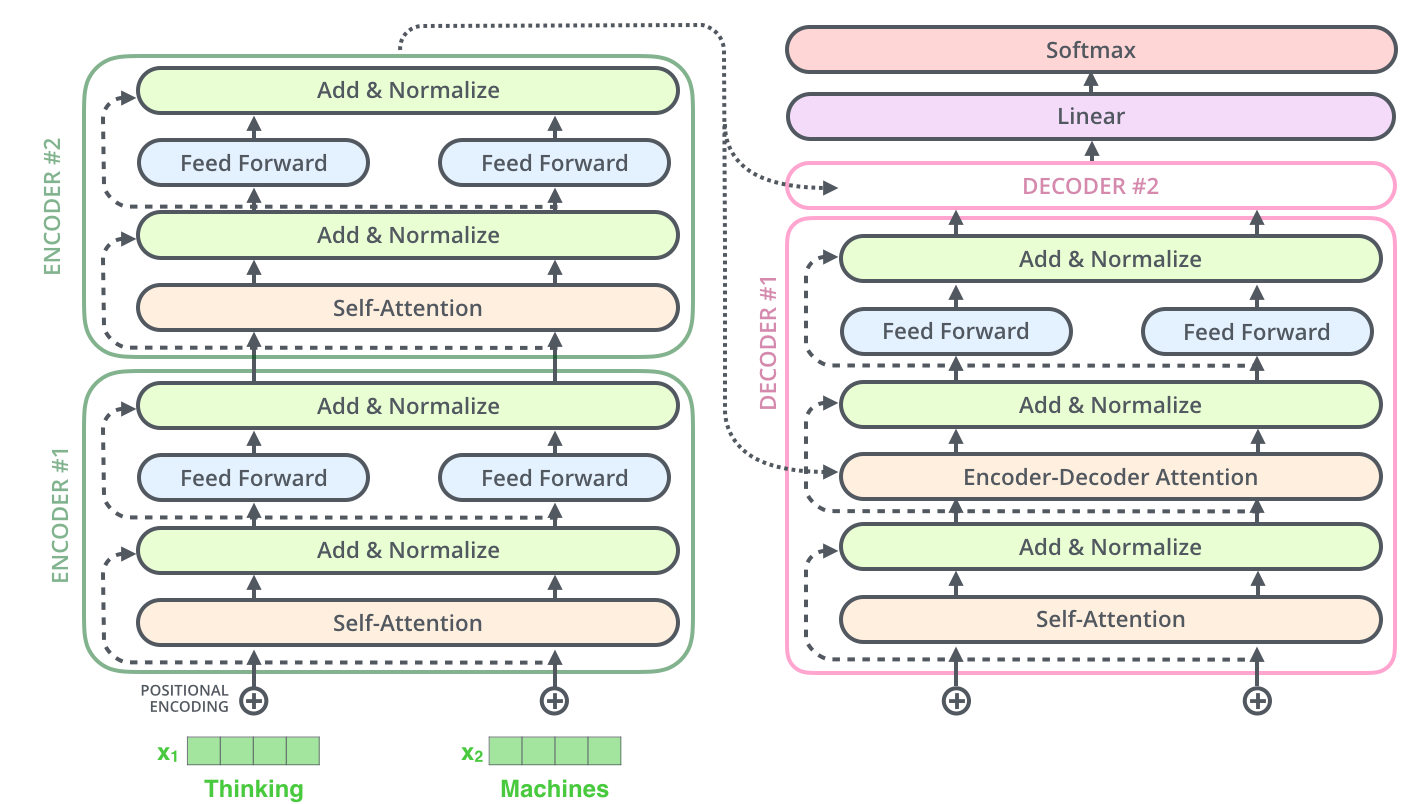 Transformer 2层Encoder+Decoder架构简图
Transformer 2层Encoder+Decoder架构简图
再参照论文里边的Transformer模型架构图,如下,
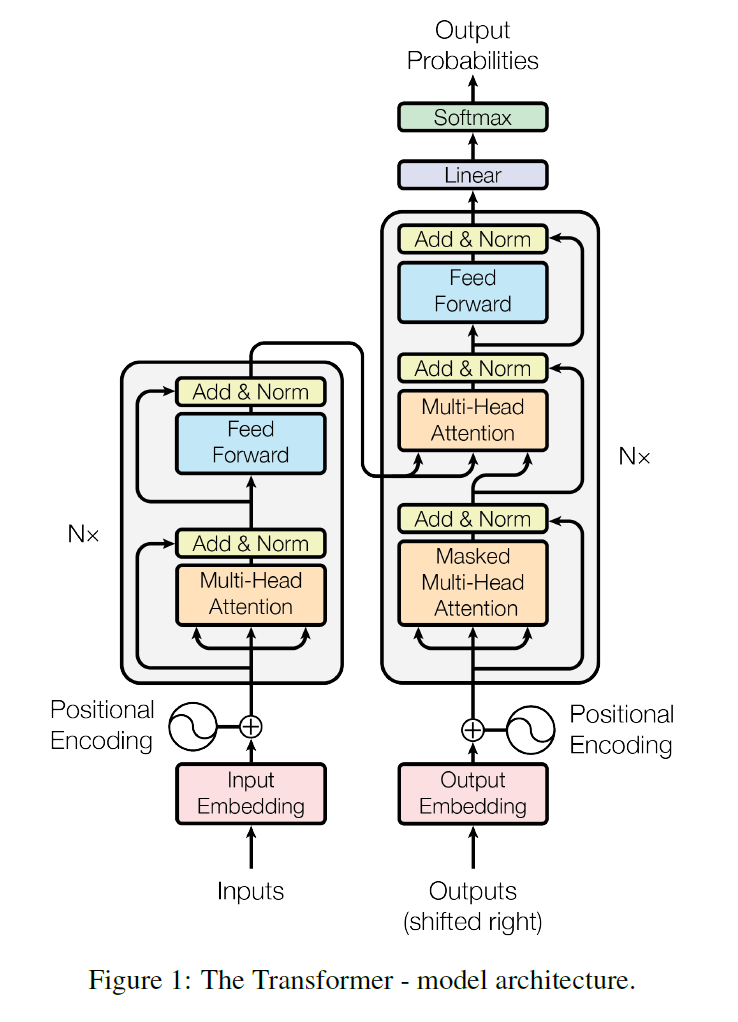 Transformer 论文原架构图
Transformer 论文原架构图
Encoder
现在我们已经看到了模型的主要组成部分,让我们开始看看各种张量是如何在这些组成部分之间流动的,从而将训练模型的输入转换为输出的。
Input Embedding
与一般的NLP流程一样,先用Embedding算法把每个输入的单词转换为向量。
 Transformer Input Embedding
Transformer Input Embedding
论文里的embedding维度,每个单词都embedding到大小为512的向量,暂且用这些简单的方框来表示这些向量。
注:embedding仅发生在最底部的Encoder中。所有编码器的共同抽象是,它们接收一个大小为512的向量列表——在底部编码器中是单词的embedding,但在其他编码器中的输入,是直接位于下方的编码器的输出。这个列表的大小是可以设置的超参数——一般是我们训练数据集中最长句子的长度。
Position Embedding
这是一个描述input序列中单词顺序的方法。
Transformer在每个输入embedding中加一个位置向量,帮助它确定每个单词的位置,或序列中不同单词之间的距离。
直观上看,一旦嵌入向量被投影到Q/K/V向量中,并在点积注意力期间,将这些值添加到embedding向量中,可以在embedding向量之间提供有意义的距离。
 Transformer Position Embedding
Transformer Position Embedding
在我们的输入序列中embedding单词和位置后,每个单词都会流过编码器的两层,分别是Self-Attention、FFN。
 Transformer embedding流过encoder的两层
Transformer embedding流过encoder的两层
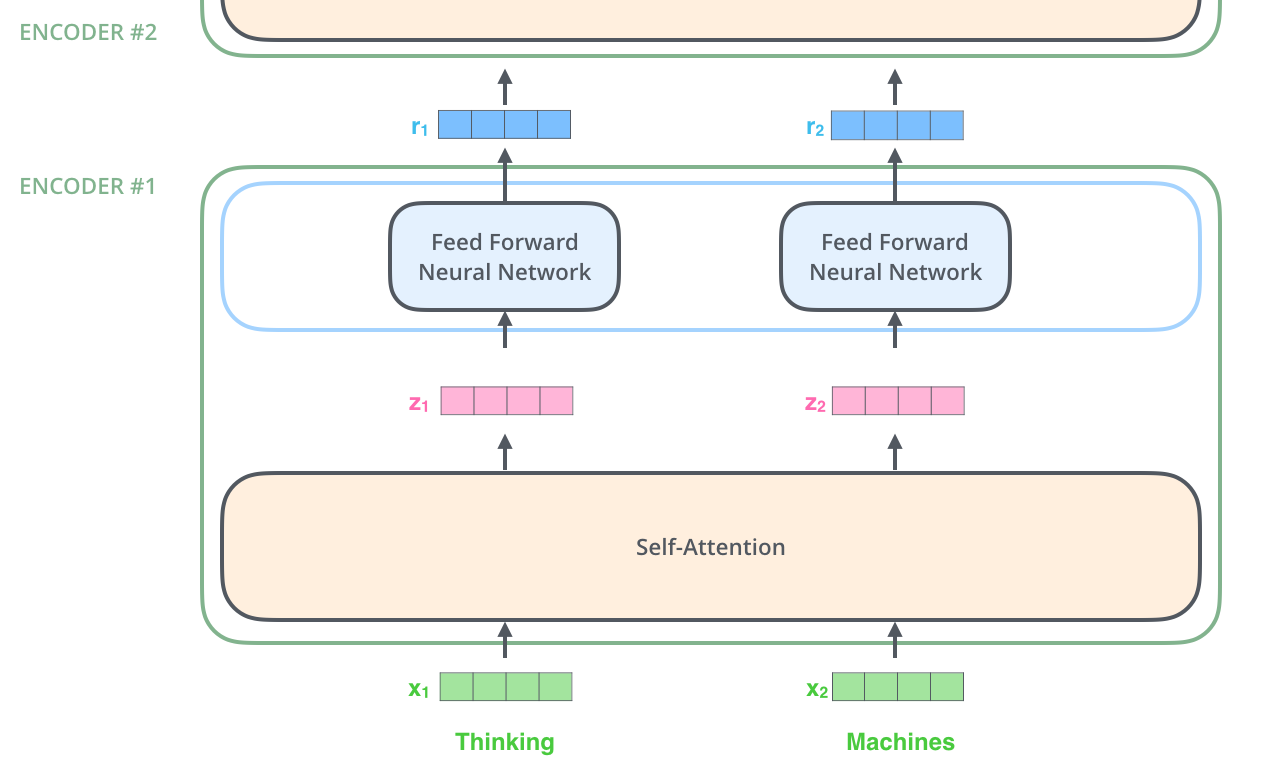
在这里,有一个Transformer的一个关键属性——每个位置的单词在编码器中都沿着自己的路径流动。在自注意力层中,这些路径之间存在依赖关系。但FFN层不具有这些依赖性,因此各种路径可以在流经FFN层时并行执行。
Now We’re Encoding
正如我们已经提到的,编码器接收向量列表作为input,它将这些向量传递到自注意力层,然后传递到FFN来处理这个列表,然后将输出向上发送到下一个编码器。
 Transformer Encoding
Transformer Encoding
Self-Attention
Self-Attention怎么理解?
假设以下是我们要翻译的句子,
The animal didn't cross the street because it was too tired
这个句子中的it指的是什么?它指的是街道还是动物?这对人来说是一个简单的问题,但对算法来说却不那么简单。
当模型处理单词it时,自注意力使其能够将it与“动物”联系起来。
当模型处理每个单词(输入序列中的每个位置)时,自注意力允许它查看输入序列中其他位置的线索,以帮助更好地编码这个单词。
如果熟悉RNN,想想维护隐藏状态是如何让RNN将它处理过的先前单词/向量的表示,与它正在处理的当前单词/向量结合起来的。自注意力层是Transformer用来将其他相关单词的“理解”加工到我们当前正在处理的单词编码的方法。
 Self-Attention 直观理解
Self-Attention 直观理解
当我们在编码器5(Encoders堆栈中的顶部编码器)中对单词it进行编码时,部分注意力机制集中在the Animal上,并将其表示的一部分加工成it的编码。
第一步,从编码器的每个input向量(每个单词的embedding)中创建三个向量,即对每个单词都创建一个查询向量q、一个关键字向量k和一个值向量v。这些向量是通过将embedding乘以在训练过程中训练的三个参数矩阵得到的。
注意,这些新向量的维度小于embedding向量,论文中它们的维度是64,而embedding和编码器输入/输出向量的维度为512。它们不必更小,这是一种架构选择,可以使多头注意力的计算(大多)保持不变。
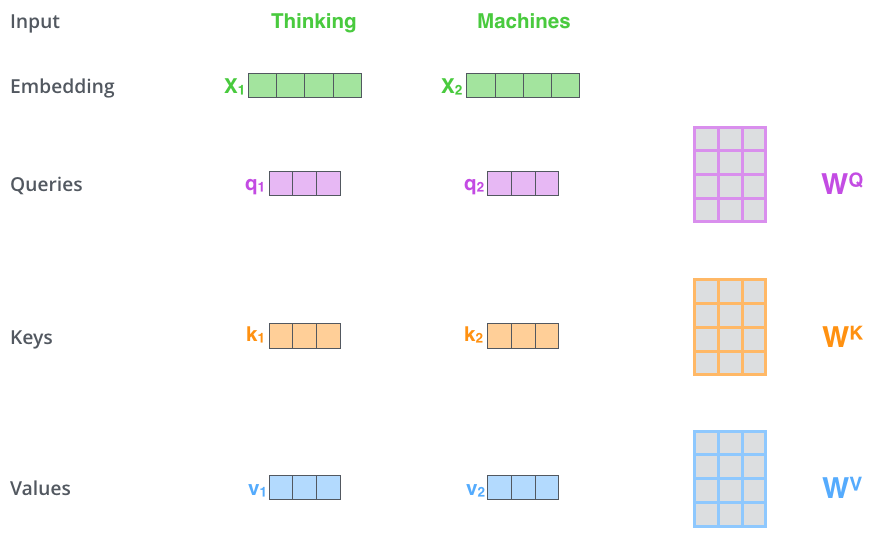 Self-Attention 向量计算第一步,得到q、k、v
Self-Attention 向量计算第一步,得到q、k、v
乘以WQ权重矩阵得到q1,即与该单词相关的查询向量。我们最终为input句子中的每个单词分别创建了一个query、一个key和一个value投影。
它们是用于计算和思考注意力的抽象概念。继续往下看注意力的计算方法,就可以知道所有你要知道的。
第二步,计算分数Score。假设我们正在计算这个例子中第一个单词think的自注意力。需要根据这个单词对input中的每个单词进行评分。分数决定了当我们在某个位置对单词进行编码时,对input其他部分的关注程度。
分数是通过Q向量与我们正在评分的相应单词的K向量的点积来计算的。因此,如果我们正在处理位置1中单词的自注意力,第一个分数将是q1和k1的点积。第二个分数是q1和k2的点积。
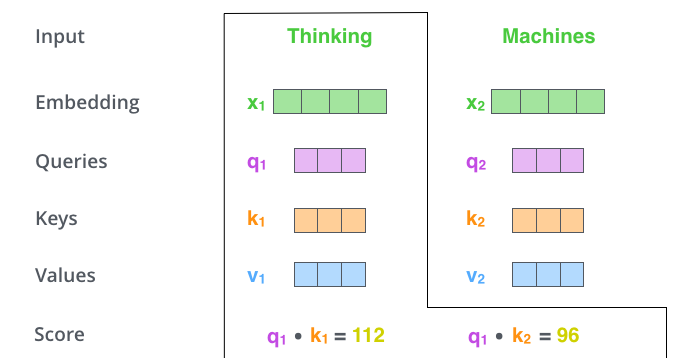 Self-Attention 向量计算第二步,计算分数score
Self-Attention 向量计算第二步,计算分数score
第三步和第四步,将分数除以8(这样做是为了更稳定的梯度,论文中使用的是K向量维数64的平方根,这里也能用其他可能的值,但这里用的是默认值8),然后通过softmax函数处理最终结果(Softmax对分数进行归一化处理,使其全部为正,加起来为1)。
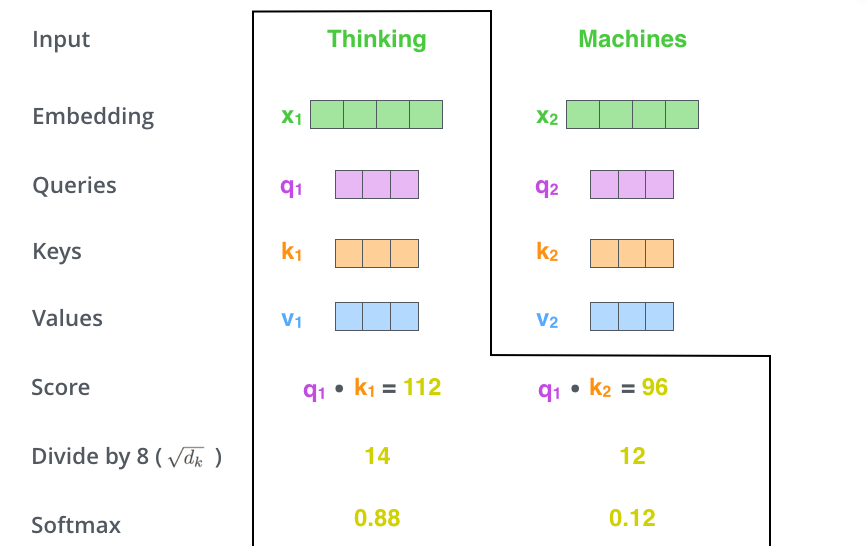 Self-Attention 向量计算第三、四步,softmax
Self-Attention 向量计算第三、四步,softmax
这个softmax分数决定了每个单词在这个位置的表达量,这个位置的单词拥有最高的softmax分数,但关注与当前单词相关的另一个单词才是有用的。
第五步,将每个V向量乘以softmax分数(准备将它们相加)。直观上看,是想保持我们想要关注的单词的值不变,并遮掩不相关的单词(例如,通过将它们乘以0.001这样的小数字)。
第六步,对加权的V向量求和,在这个位置(第一个单词)产生自注意力层的输出。
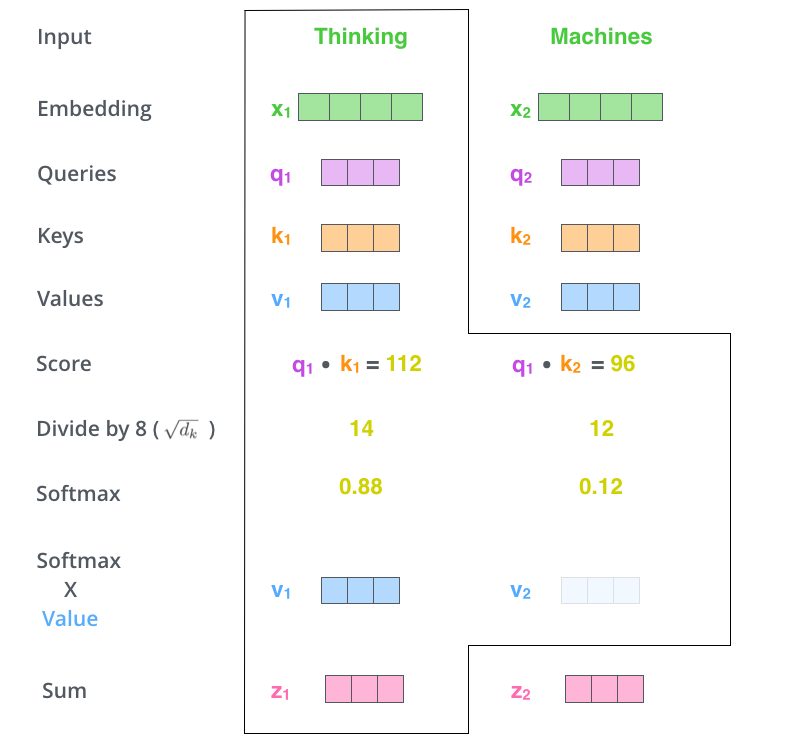 Self-Attention 向量计算第五、六步,产生自注意力层的输出
Self-Attention 向量计算第五、六步,产生自注意力层的输出
自注意力层的计算,到此结束,得到的向量发送到FFN。在实际实现中,为了更快的处理,这种计算是以矩阵形式完成的。
继续看看矩阵计算如何实际实现?
第一步,计算Q、K和V矩阵,将每个单词的embedding组合打包到矩阵X中,并将其乘以我们训练的权重矩阵(WQ、WK、WV)。
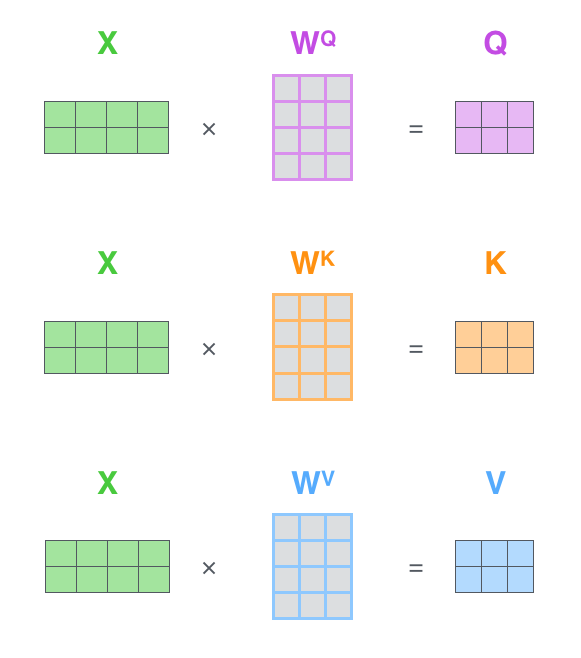 Self-Attention 向量计算实际实现,第一步
Self-Attention 向量计算实际实现,第一步
X矩阵中的每一行对应于输入句子中的一个单词,上图用小框区别了Embedding向量(512,或图中的4个框)和q/k/v向量(图中的64,或3个框)的大小差异
因为我们处理的是矩阵,我们可以将第二步到第六步压缩到一个公式中,以计算自注意里层的输出。
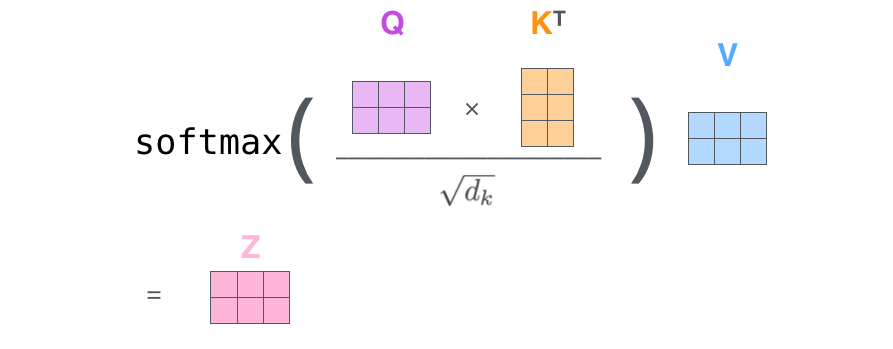 Self-Attention 向量计算实际实现,第二步到第六步
Self-Attention 向量计算实际实现,第二步到第六步
Multi-head Self-attention
论文里,通过添加多头注意力机制,进一步细化自注意力层。从两个方面提高了注意力层的性能,
- 它扩展了模型专注于不同位置的能力。在上面的例子中,
z1包含了其他编码的一小部分,但它可能被实际的单词本身所主导。如果我们翻译一个句子,比如The animal didn’t cross the street because it was too tired,知道it指的是哪个词会很有用。 - 它为注意力层提供了多个“表示子空间”。使用多头注意力,我们不仅有一组,而是有多组
Q/K/V权重矩阵(Transformer使用八个注意力头,因此每个编码器/解码器最终都有八组)。这些集合中的每一个权重矩阵都是随机初始化的。然后,在训练之后,使用每个集合将输入Embedding(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
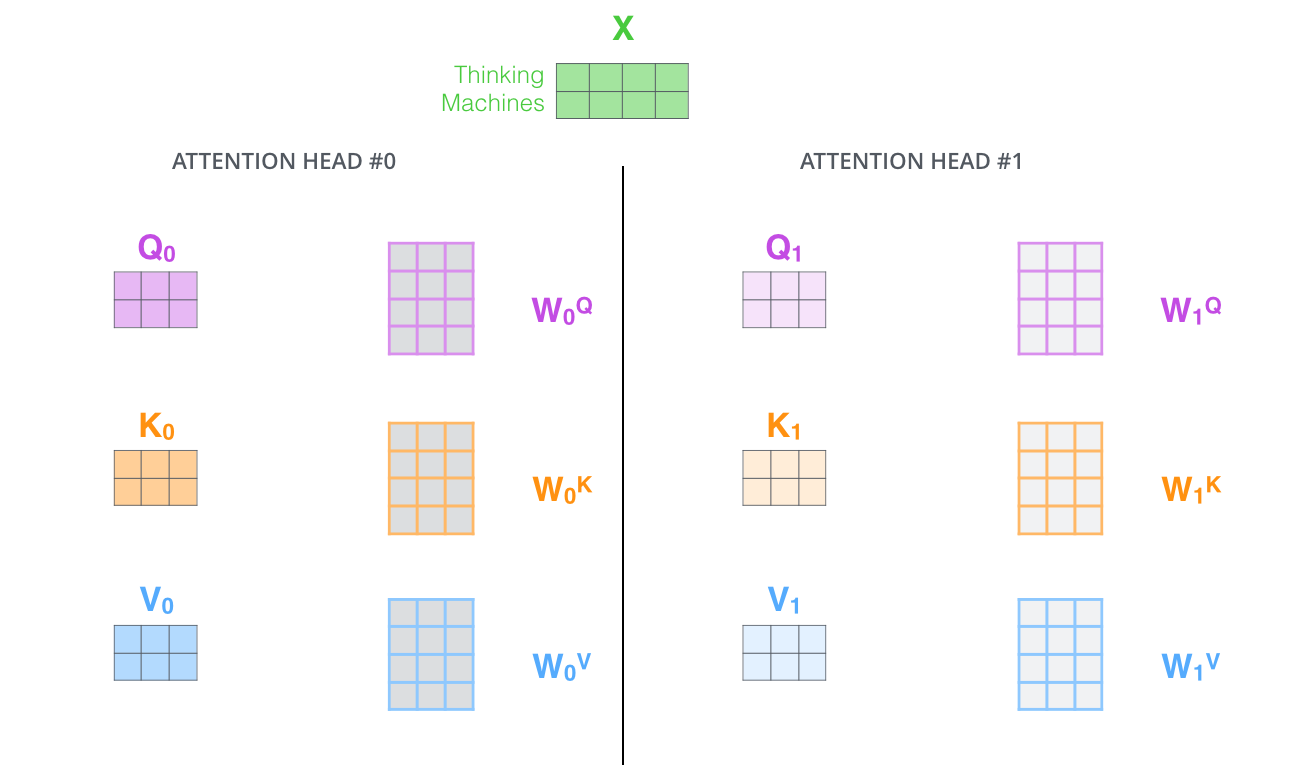 Self-Attention 向量计算实际实现,多头自注意力
Self-Attention 向量计算实际实现,多头自注意力
通过多头注意力,我们为每个头维护单独的Q/K/V权重矩阵,从而得到不同的Q/K/V矩阵。与之前一样,我们将X乘以WQ/WK/WV矩阵,得到Q/K/V矩阵。
如果我们进行上面说的相同的自注意力计算,只需使用不同的权重矩阵进行八次不同的计算,我们最终会得到八个不同的Z矩阵。
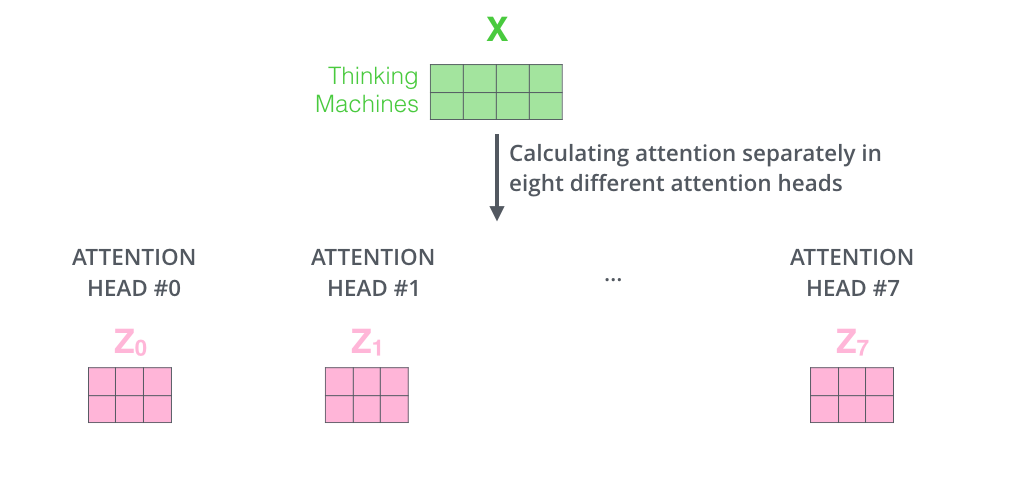 Self-Attention 向量计算实际实现,多头自注意力结果得到Z矩阵
Self-Attention 向量计算实际实现,多头自注意力结果得到Z矩阵
但FFN层不需要八个矩阵,它只需要一个矩阵(每个单词一个向量),所以我们需要一种方法将这八个压缩成一个矩阵。
我们concat这些矩阵,然后将它们乘以一个额外的权重矩阵WO。
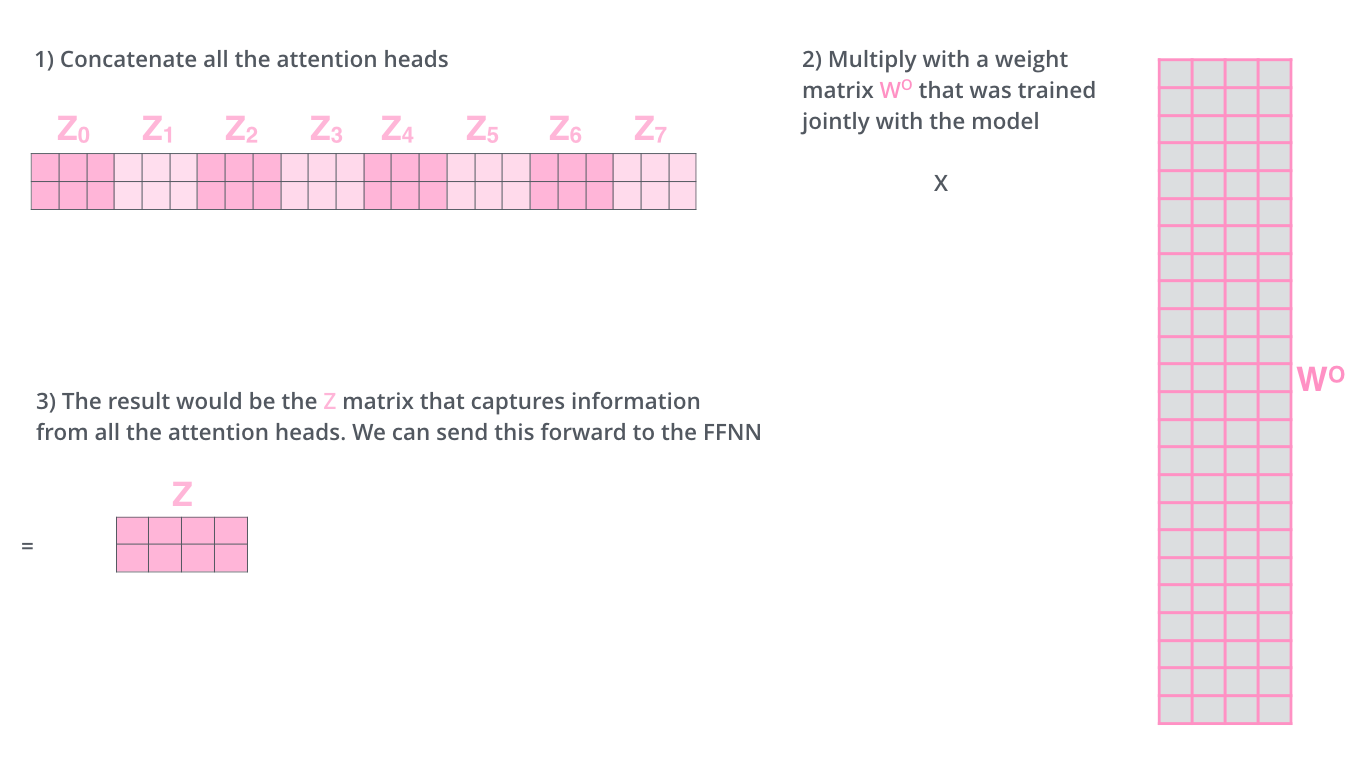 Self-Attention 向量计算实际实现,Z矩阵经过WO,输出结果
Self-Attention 向量计算实际实现,Z矩阵经过WO,输出结果
所有步骤,合在一起,放在一张图里边,如下,
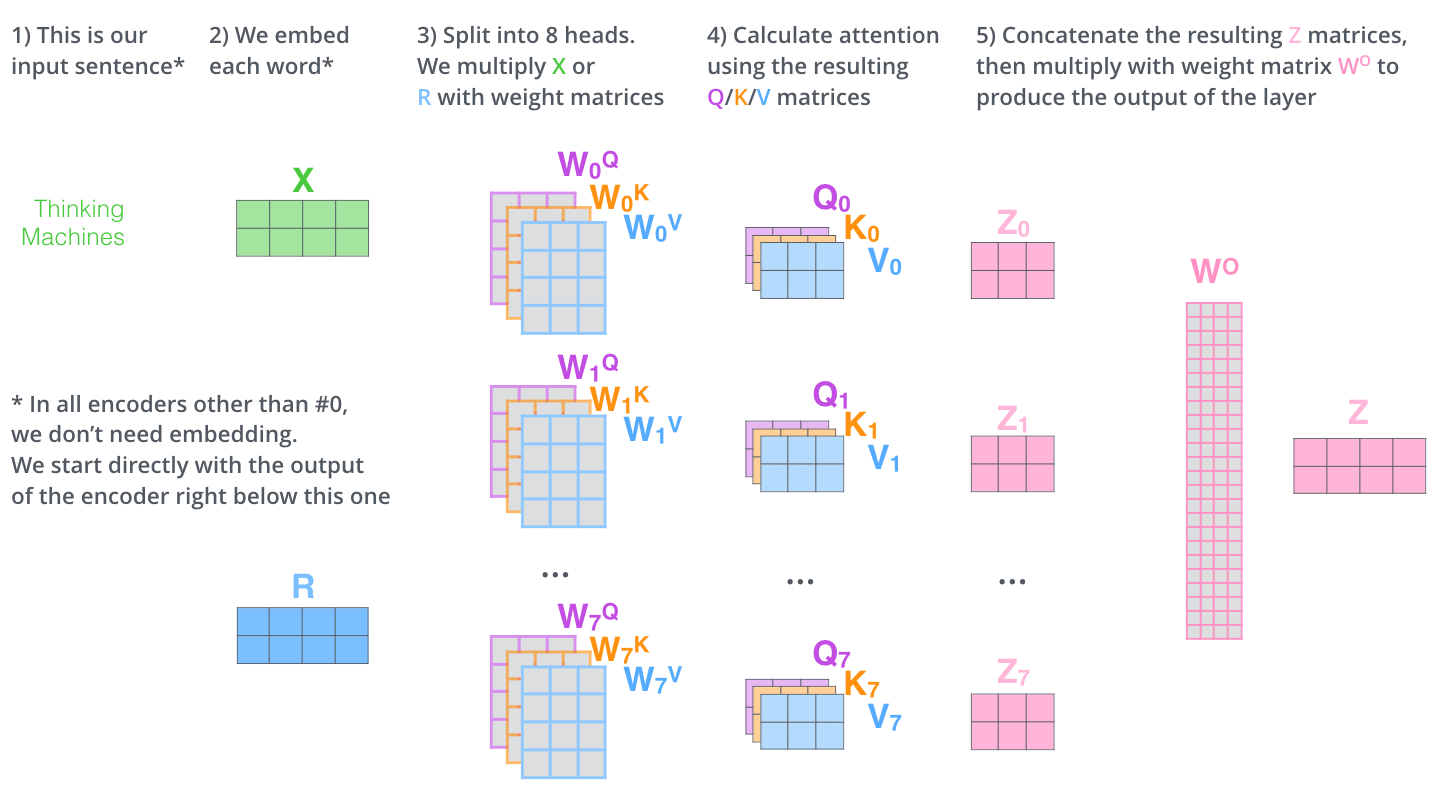 Self-Attention 向量计算实际实现,汇总
Self-Attention 向量计算实际实现,汇总
现在我们已经谈到了注意力头,让我们重新审视之前的例子,看看在我们的例句中编码单词it时,不同的注意力头都集中在哪里:
 Self-Attention 理解
Self-Attention 理解
当我们对单词it进行编码时,一个注意力主要集中在the animal上,而另一个注意力则集中在tired上——从某种意义上说,模型对单词it的表示在animal和tired的一些表示中起到了推波助澜的作用。
如果我们把所有的注意力都放在图片上,事情可能会更难解释,
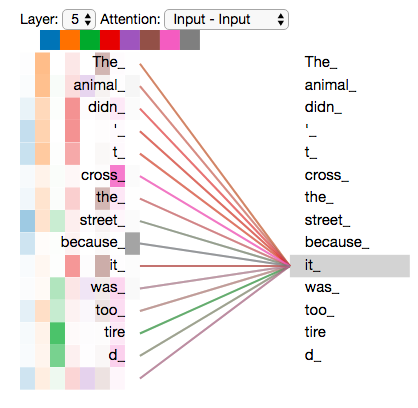 Self-Attention 理解
Self-Attention 理解
LayerNorm & Residual
每个编码器中的每个子层(Self-Attention,FFN)都有一个围绕它的残差连接,然后是层归一化步骤。
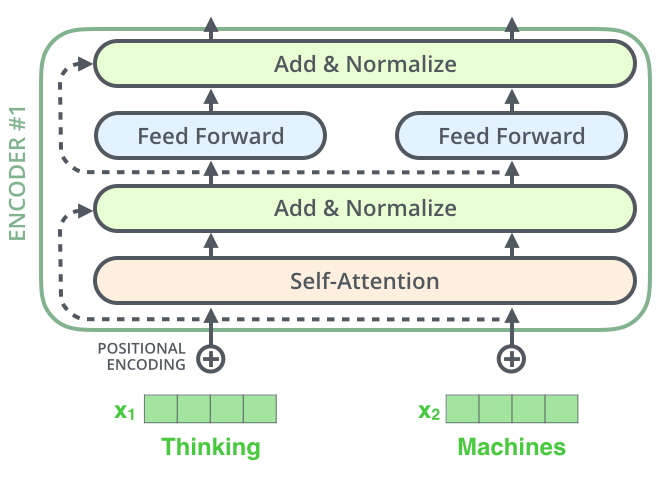 Self-Attention 层归一化 & 残差
Self-Attention 层归一化 & 残差
可视化向量和与自注意力相关的layer-norm操作,如下,
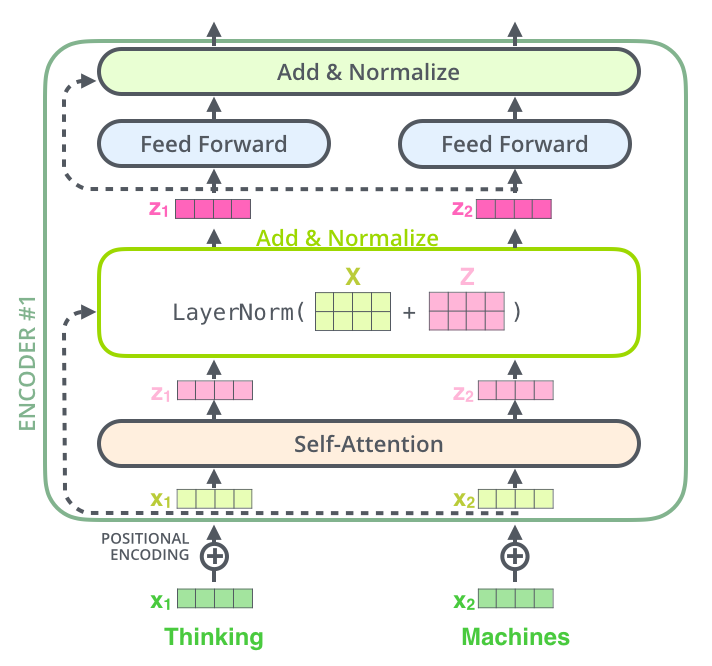 向量可视化
向量可视化
Feed-forward Neural Network
FFN层的作用是,通过放大再缩小的方式,在注意力层输出的特征里边寻找有用的特征,多样化,提升特征表征能力,论文里边的维度是512(input)-2048(中间)-512(output)。
Decoder
编码器和解码器是如何协同工作的?编码器首先处理input序列,顶部编码器的输出被转换为一组注意力向量K和V。这些向量将由每个解码器在其Encoder-Decoder Attention层中使用,帮助解码器专注于输入序列中的适当位置。
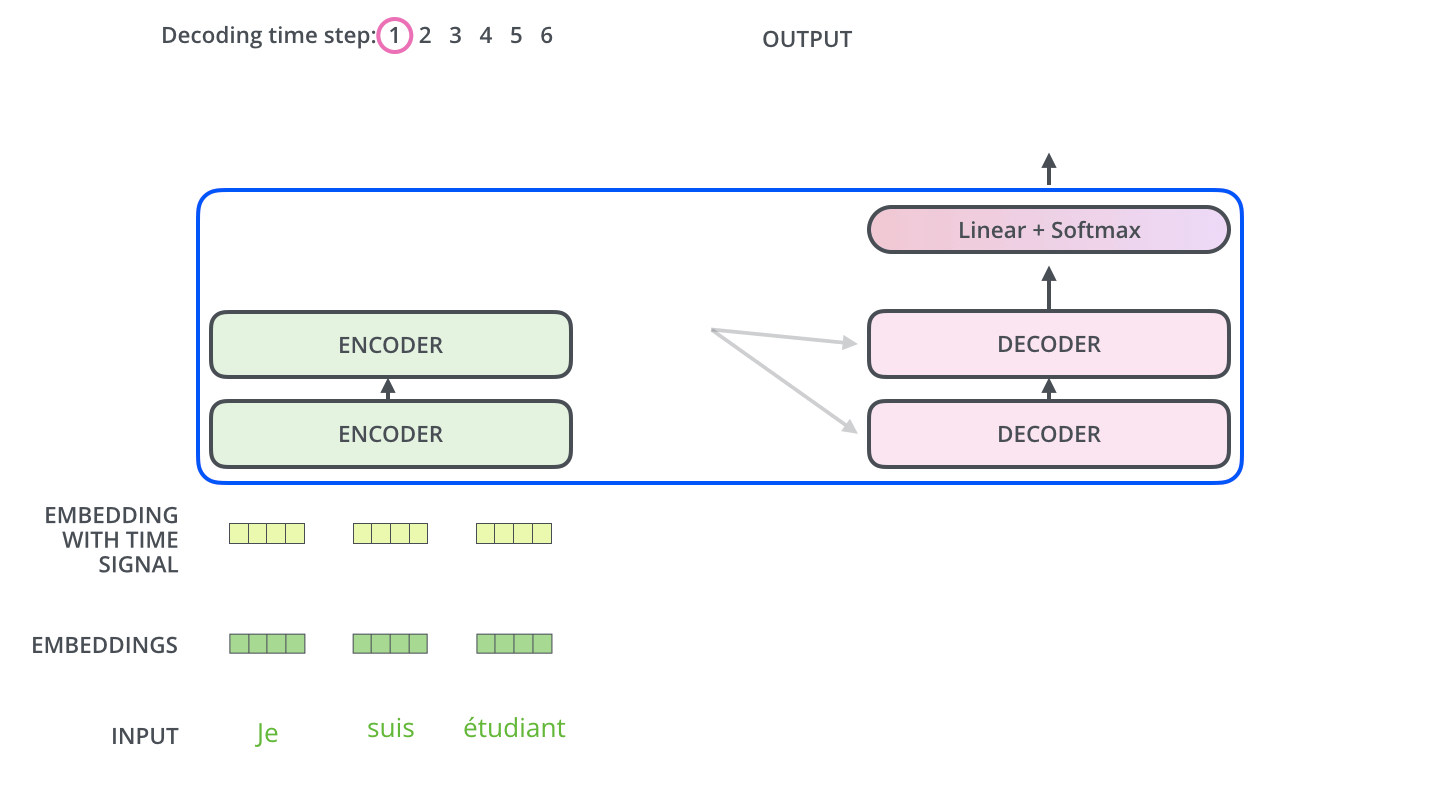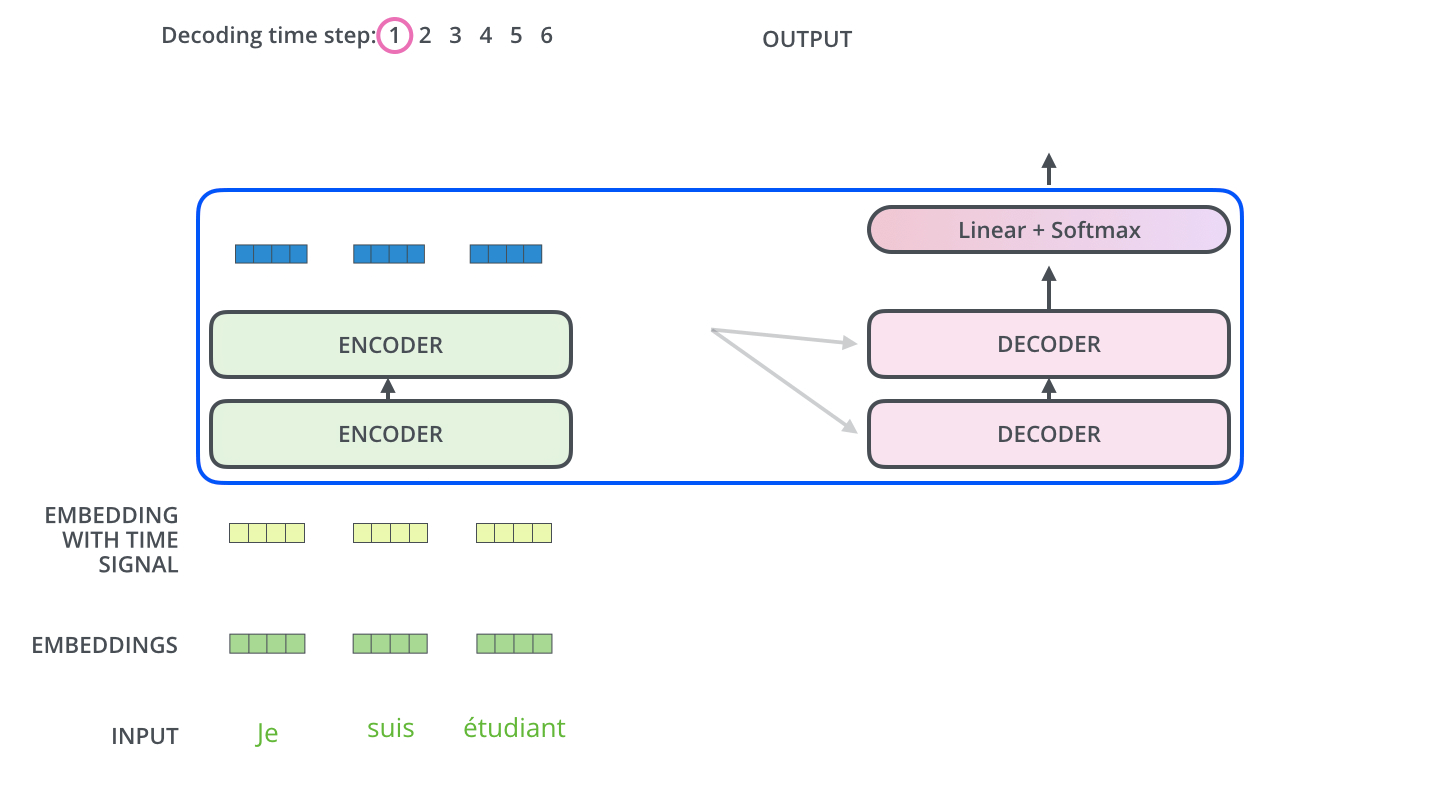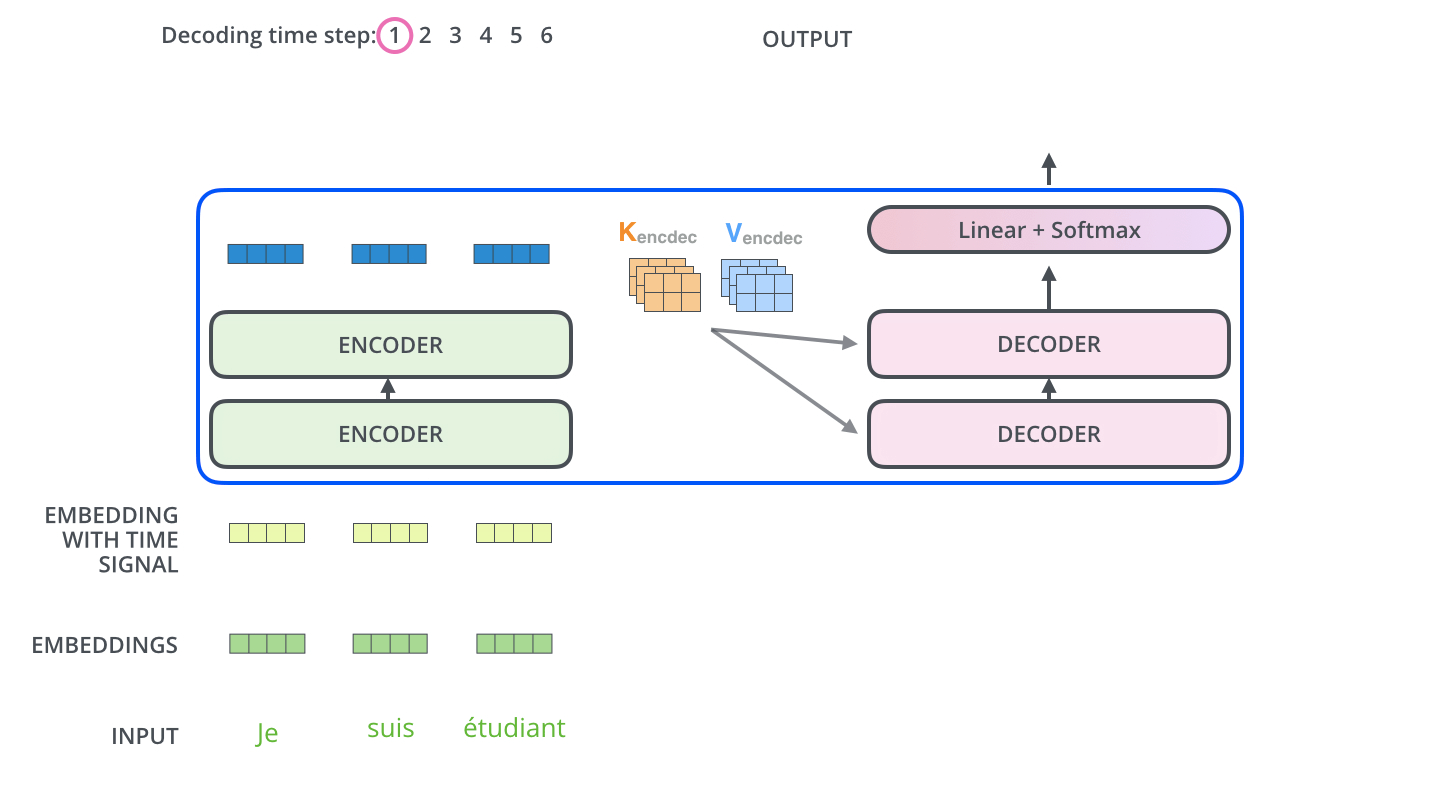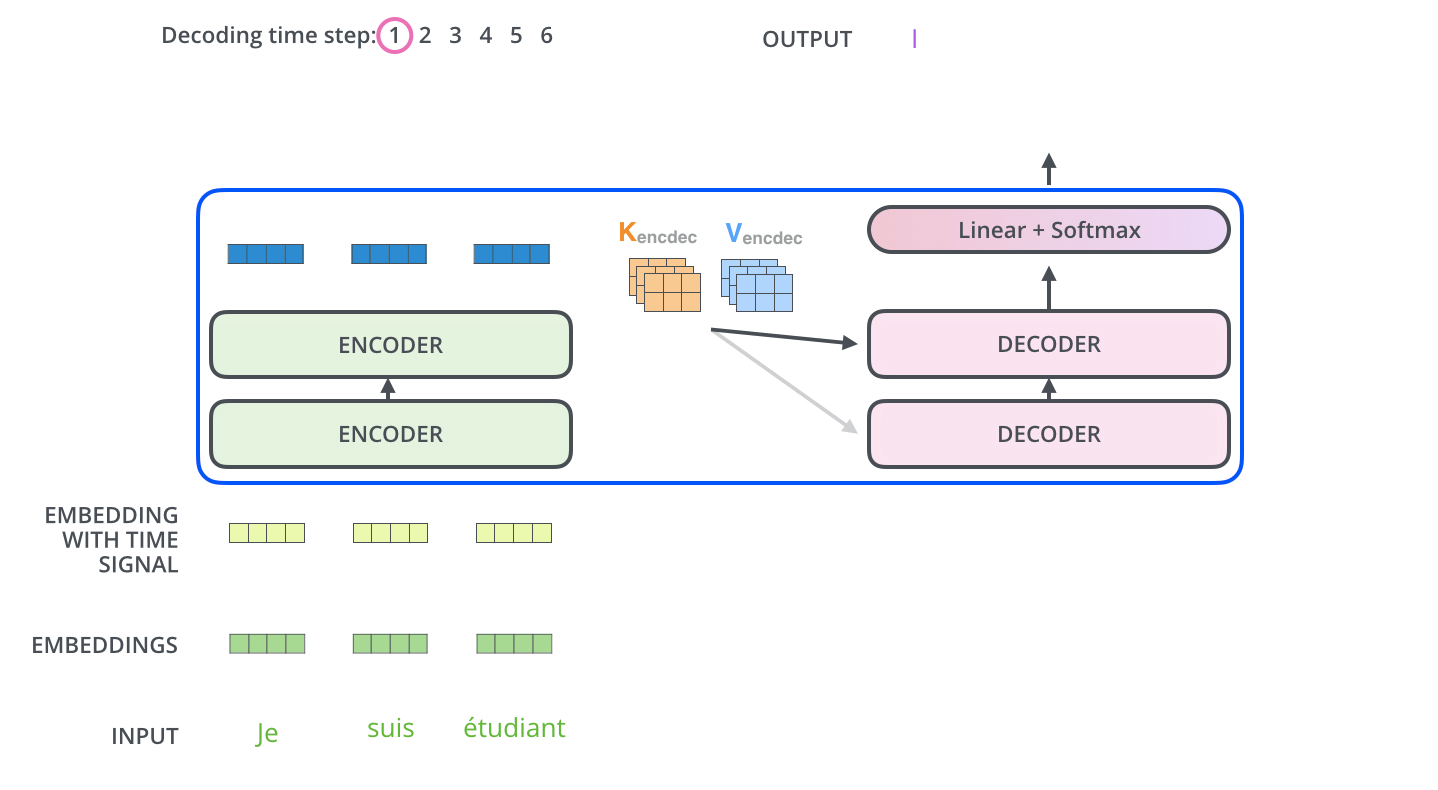 Decoder 一组处理过程-动态图
Decoder 一组处理过程-动态图
完成编码阶段后,开始解码阶段。解码阶段的每一步都从输出序列中输出一个元素。
重复这个过程,直到达到一个特殊符号,表示Transformer解码器已完成其输出。每一步的输出在下一刻被喂给底部解码器,解码器像编码器一样放大解码结果,就像我们对编码器输入所做的那样,将位置编码Embedding,并添加到这些解码器输入中,以指示每个单词的位置。
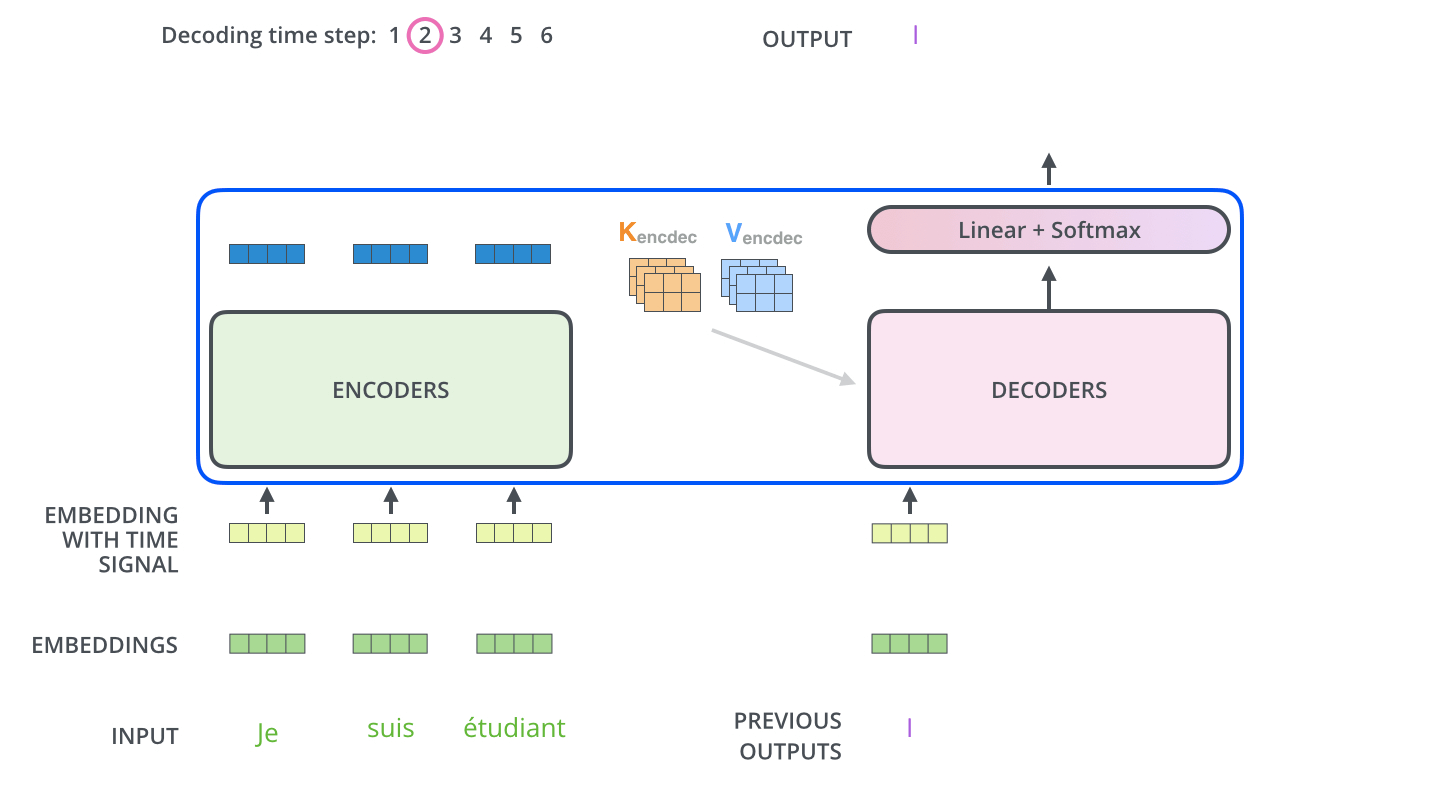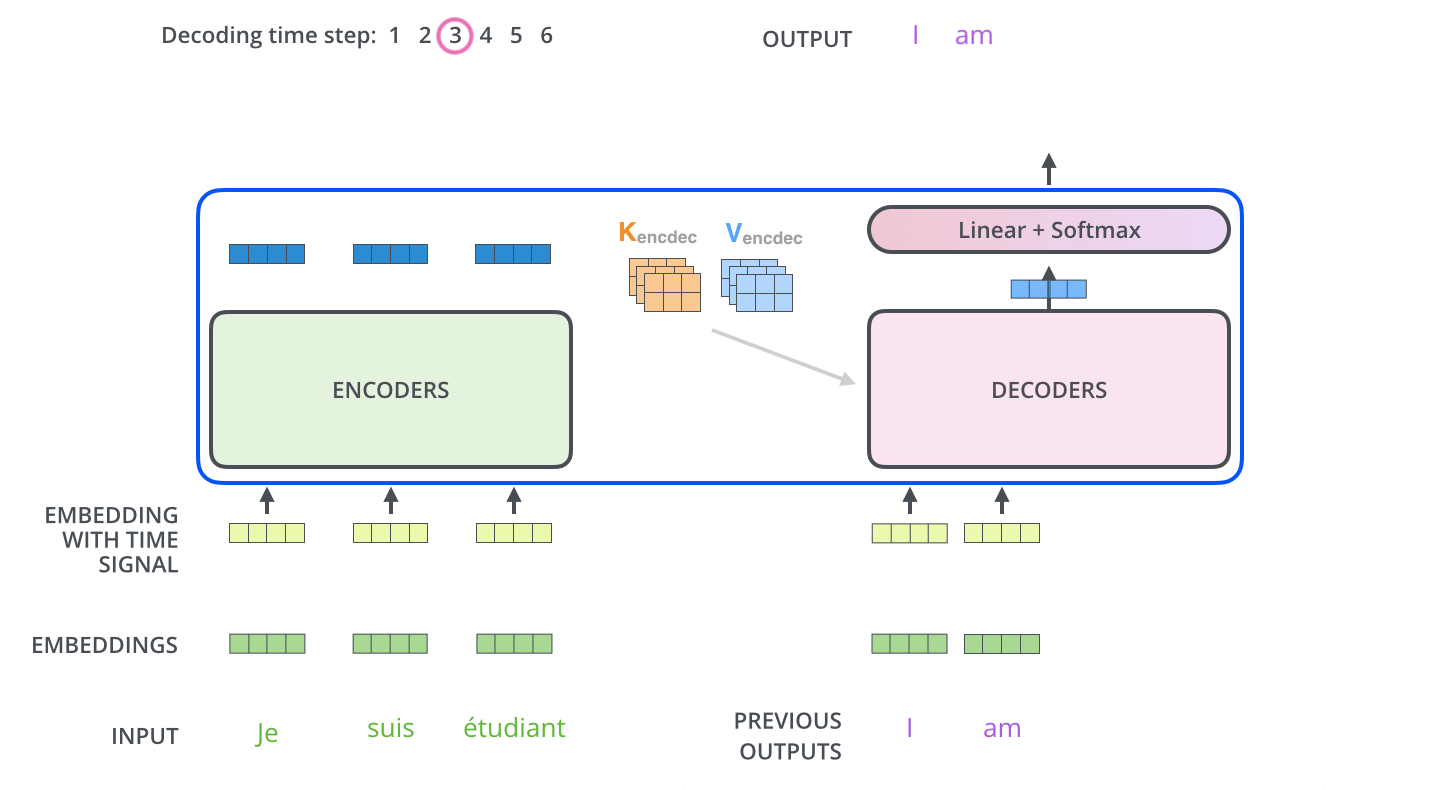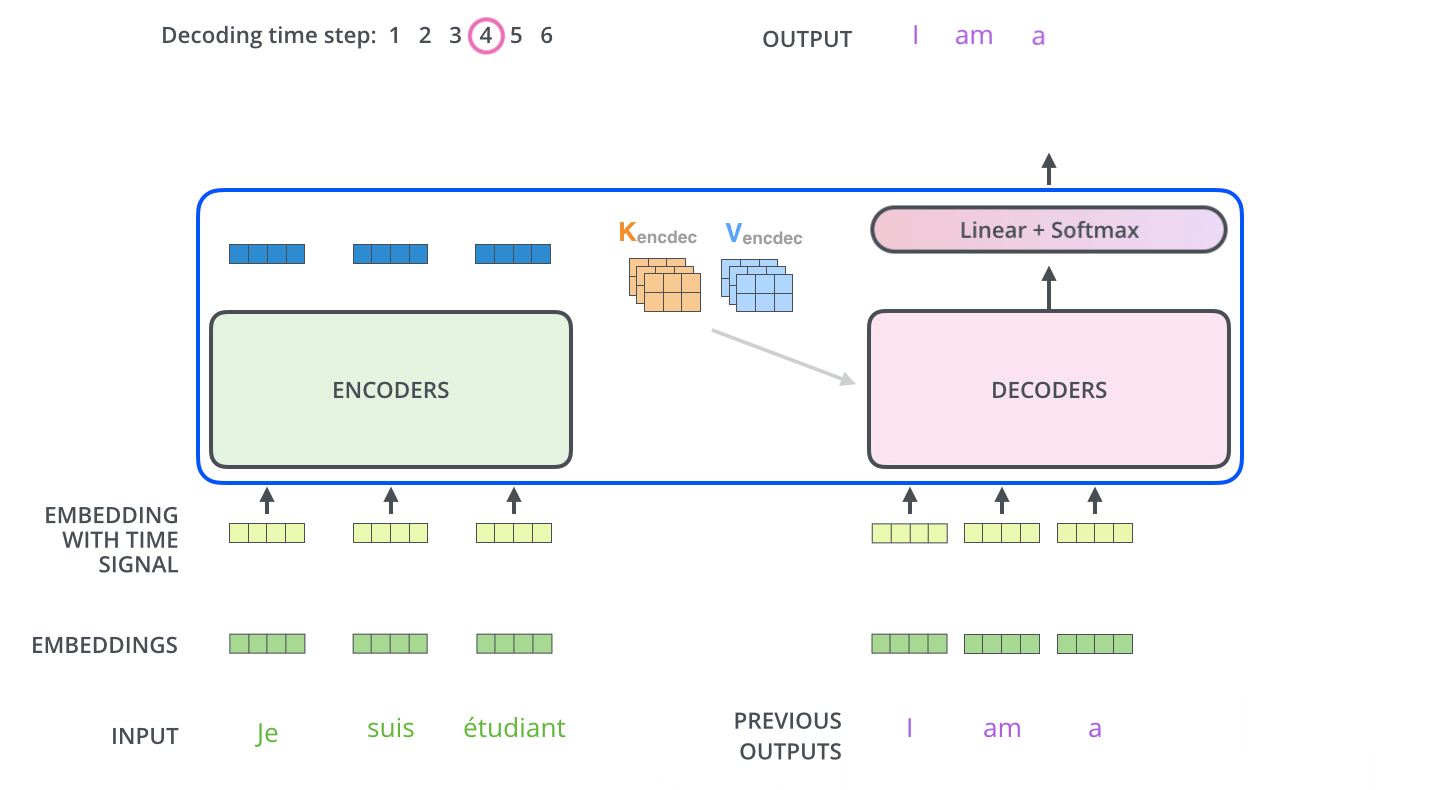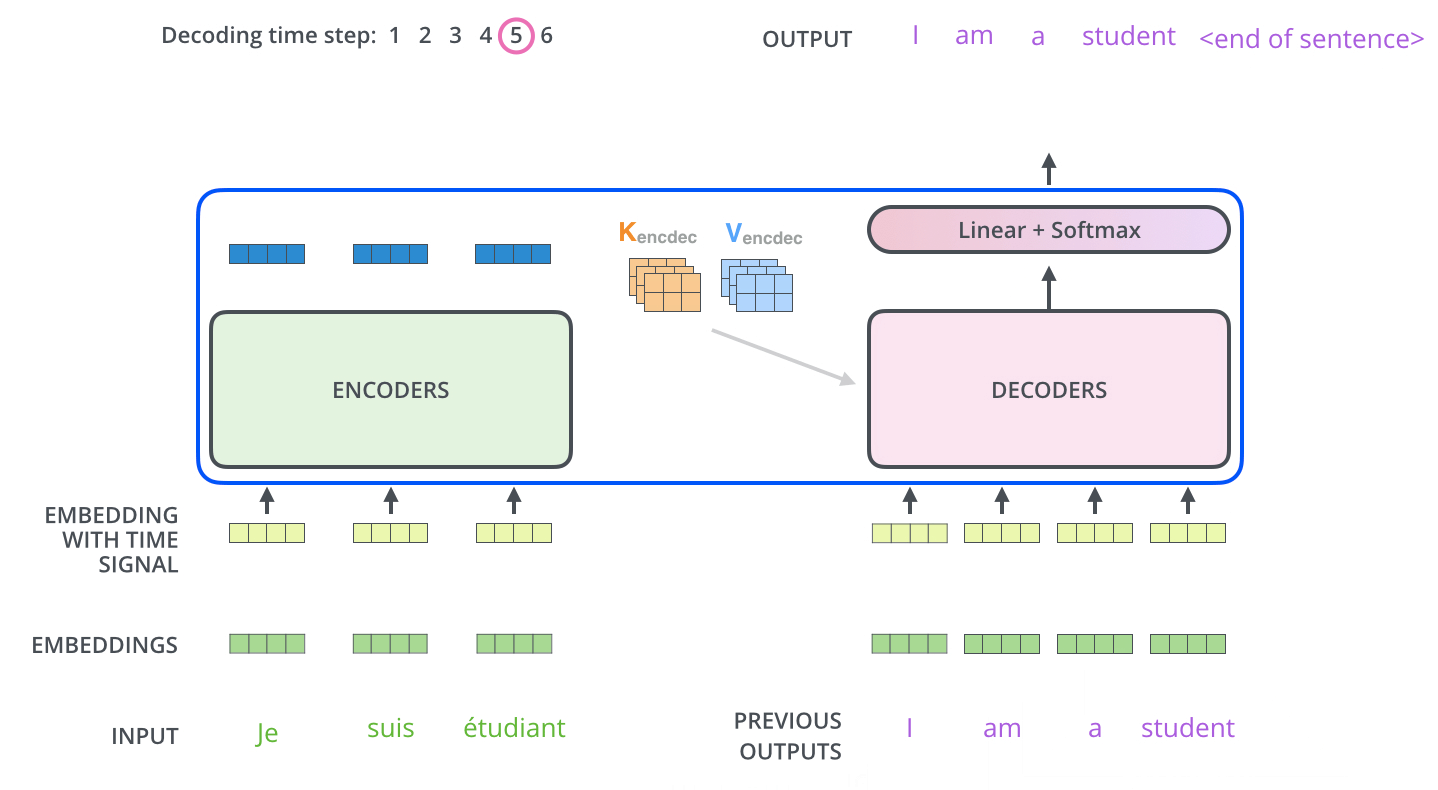 Decoder 全部处理过程-动态图
Decoder 全部处理过程-动态图
解码器中的自注意力层的工作方式与编码器中的略有不同。
在解码器中,自注意力层只允许关注输出序列中的较早位置。通过在自注意力计算中的softmax步骤之前屏蔽未来的位置(将其设置为-inf)来实现的。这一步骤也叫Casual Multi-head Self-attention。
Encoder-Decoder Attention层的工作原理,除了它从下面的层创建Q矩阵,并从编码器堆栈的输出中获取K和V矩阵,与多头自注意力一样。这一步骤也叫Memory-base Multi-head Cross-attention,或者Intra-attention。
The Final Linear and Softmax Layer
Decoder输出一个floats向量,如何把它变成一个词?这就是Linear层+Softmax层的工作。
Linear层是一个简单的全连接神经网络,它将Decoder产生的向量投影到一个更大的向量中,称为logits向量。
假设模型知道10000个独特的英语单词(模型的“输出词汇表”),这些单词是从它的训练数据集中学习到的。这将使logits向量的宽度达到10000个单元格,每个单元格对应一个唯一单词的分数。这就是我们如何解释线性层后面的模型输出。
然后,softmax层将这些分数转换为概率(全部为正,加起来为1.0)。选择概率最高的单元格,并产生与之相关的单词作为此时刻的输出。
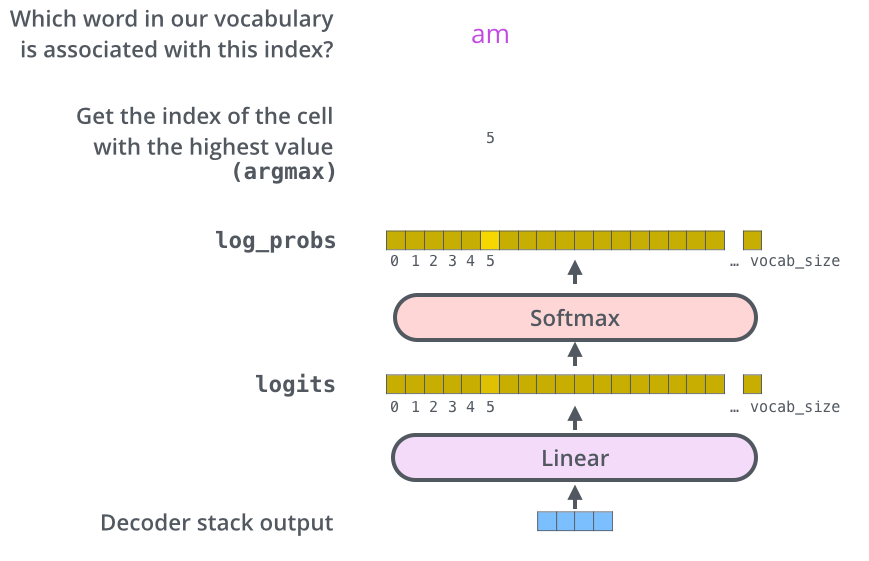 Linear + Softmax
Linear + Softmax
这张图从底部往上看,以Decoder的输出向量为起点,然后将其转换为输出单词。
Training
现在我们已经通过一个训练好的Transformer完成了整个前向传递过程,看看训练模型的过程会对理解很有帮助。
在训练过程中,未经训练的模型将经历完全相同的前向传递。但因为是在标记的训练数据集上训练它的,所以可以将其输出与实际的正确输出进行比较。
为了直观地展示这一点,假设输出词汇表只包含六个单词(a、am、i、谢谢、学生和<eos>(句末的缩写)),模型的输出词汇表是在我们开始训练之前的预处理阶段创建的。
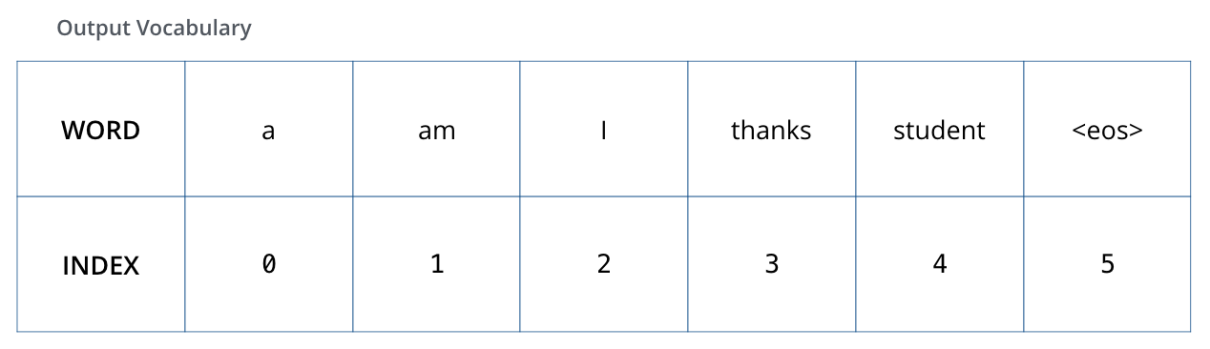 词汇表
词汇表
一旦我们定义了输出词汇表,就可以使用相同宽度的向量来表示词汇表中的每个单词,这也被称为one-hot编码。例如,我们可以使用以下向量表示单词am,
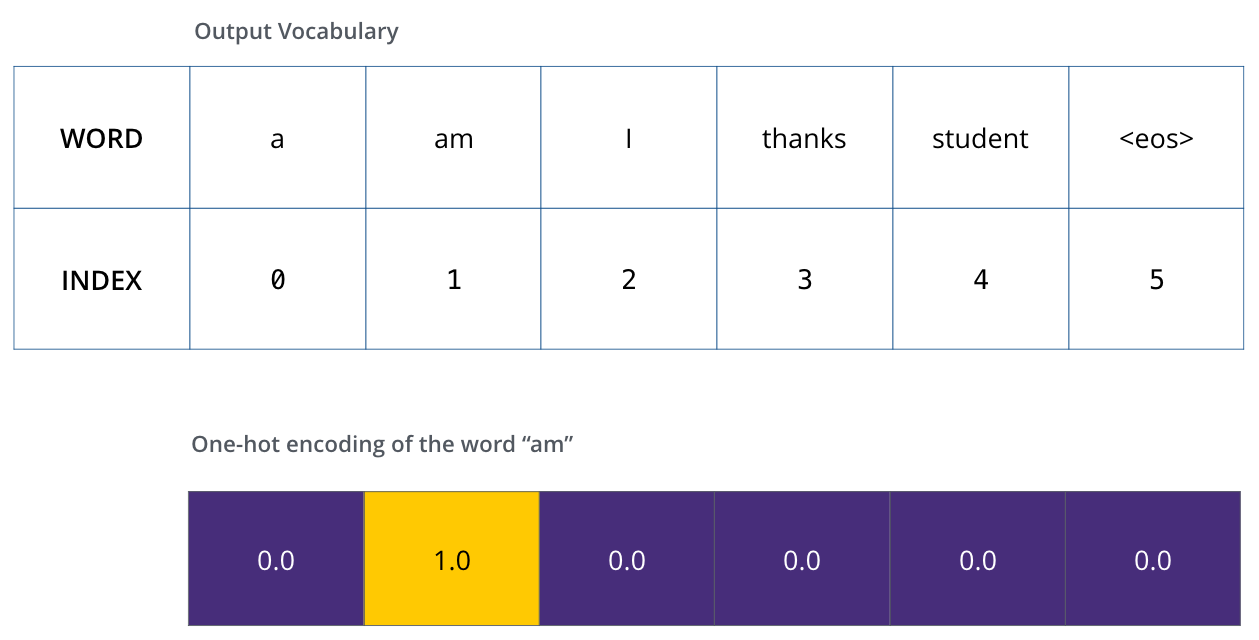 词汇表 one-hot
词汇表 one-hot
示例,输出词汇表的一个one-hot编码
之后,讨论一下模型的损失函数——我们在训练阶段优化的指标,以得到一个训练过的、希望非常准确的模型。
The Loss Function
假设正在训练模型,这是在训练阶段的第一步,正在用一个简单的例子来训练它——将merci翻译成thanks。
这意味着,希望输出是一个表示thanks这个词的概率分布,但由于该模型尚未经过训练,因此目前不太可能发生这种情况。
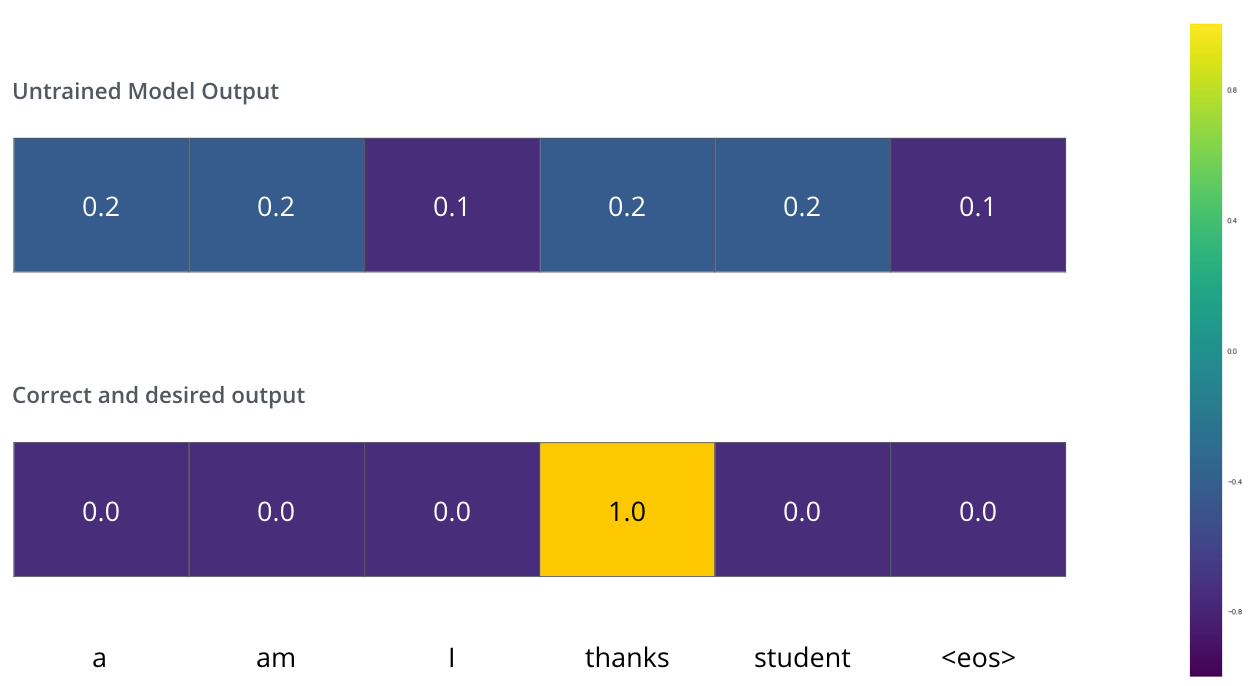 损失和真值期望
损失和真值期望
由于模型的参数(权重)都是随机初始化的,(未经训练的)模型为每个单元格/单词生成具有任意值的概率分布。我们可以将其与实际输出进行比较,然后使用反向传播调整模型的所有权重,使输出更接近所需的输出。
如何比较两种概率分布?我们只是从另一个中减去一个。有关更多细节,请查看cross-entropy 和 Kullback–Leiblerdivergence。
注意,这是一个非常简单的例子。实际上,我们会用比一个单词更长的句子。
例如,输入:je suisétudiant,预期输出:i am a student。
这意味着,我们希望模型能够连续输出概率分布。
其中:
每个概率分布都由一个宽度为vocab_size的向量表示(在我们的简单示例中vocab_size为6,但现实中可能是像30000或50000这样的数字)。
第一个概率分布在与单词i关联的单元格处具有最高概率。
第二概率分布在与单词am关联的单元格处具有最高概率。
以此类推,直到第五个输出分布指示<end of sentence>符号,该符号在10000个元素词汇表中也有一个与之关联的单元格。
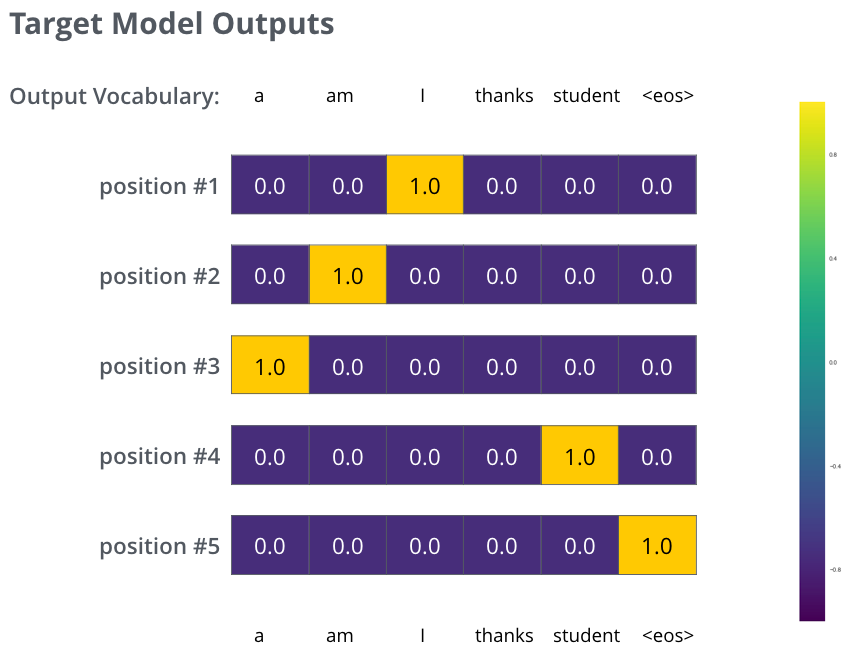 以上是,在一个样本句子的训练示例中,训练模型的目标概率分布
以上是,在一个样本句子的训练示例中,训练模型的目标概率分布
在足够大的数据集上,训练模型足够长的时间后,希望生成的概率分布看起来像这样,
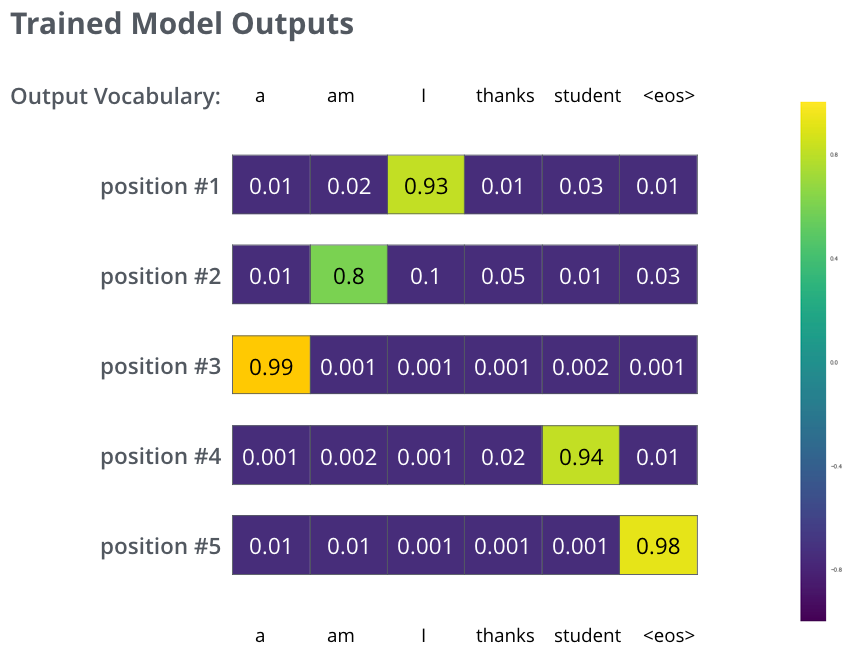 模型在实际被训练后的概率分布
模型在实际被训练后的概率分布
希望经过训练,模型能够输出我们期望的正确翻译。当然,这并不能真正表明这个短语是否是训练数据集的一部分(参见:cross validation)。注意,每个位置都有一点概率,即使它不太可能是该时刻的输出——这是softmax的一个非常有用的属性,有助于训练过程。
现在,因为模型一次产生一个输出,可以假设模型正在从概率分布中选择概率最高的单词,并丢弃其余的单词。这是一种方法(称为贪婪解码,greedy decoding)。
另一种方法是,找到前两个单词(例如I和a),然后在下一步中运行模型两次:一次假设第一个输出位置是单词I,另一次假设第二个输出位置为单词a,并且保留位置1和2产生较少错误的版本,对位置2和3等重复此操作。这种方法被称为beam search。
在例子中,beam_size为2(这意味着,在任何时候,两个部分假设(未完成的翻译)都保存在内存中),top_beams也为2(意味着我们将返回两个翻译)。这两个参数都是你可以去试验的超参数。
END