线上服务紧急告警,CPU篇
背景
回想下上次的服务过载报警,是因为流量突增带来的疯狂GC,耗尽了CPU和内存资源,在优化GC参数后,针对当时的服务流量负载得到了不错地解决。
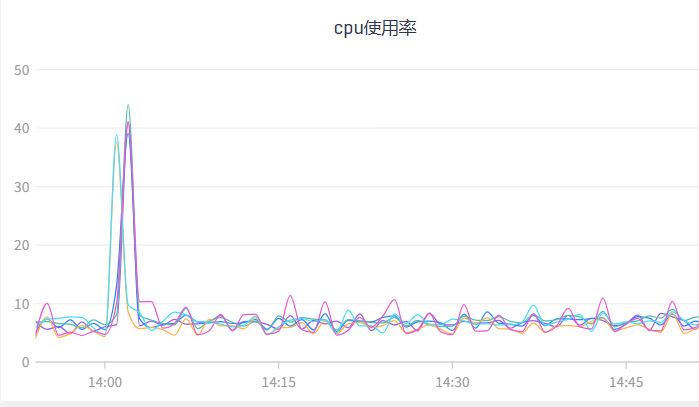
今天遇到的突发流量,比之前的峰值又翻了一倍,导致了服务过载报警,继续观察系统指标,如下,
业务请求量,较之前峰值翻倍激增,
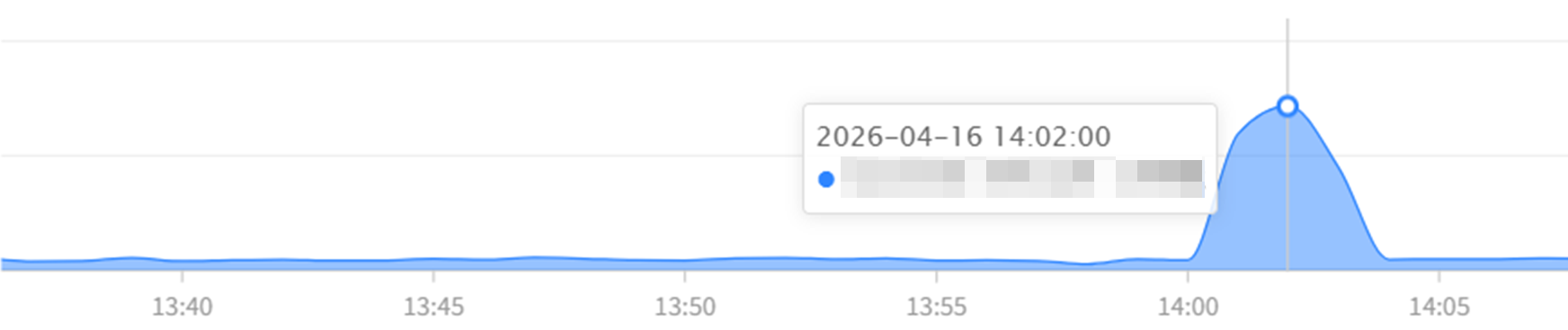 业务请求量翻倍激增
业务请求量翻倍激增
参数分析
在之前配置基础上,分析JVM运行情况,现在线上的jvm gc参数,如下,
1
2
3
4
5
6
7
8
9
10
11
12
-Xms2g -Xmx2g
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:MaxTenuringThreshold=6
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=75
-XX:+CMSParallelRemarkEnabled
-XX:+CMSScavengeBeforeRemark
-XX:+UseCMSCompactAtFullCollection
-XX:ParallelGCThreads=2
-XX:MetaspaceSize=128m
-XX:MaxMetaspaceSize=256m
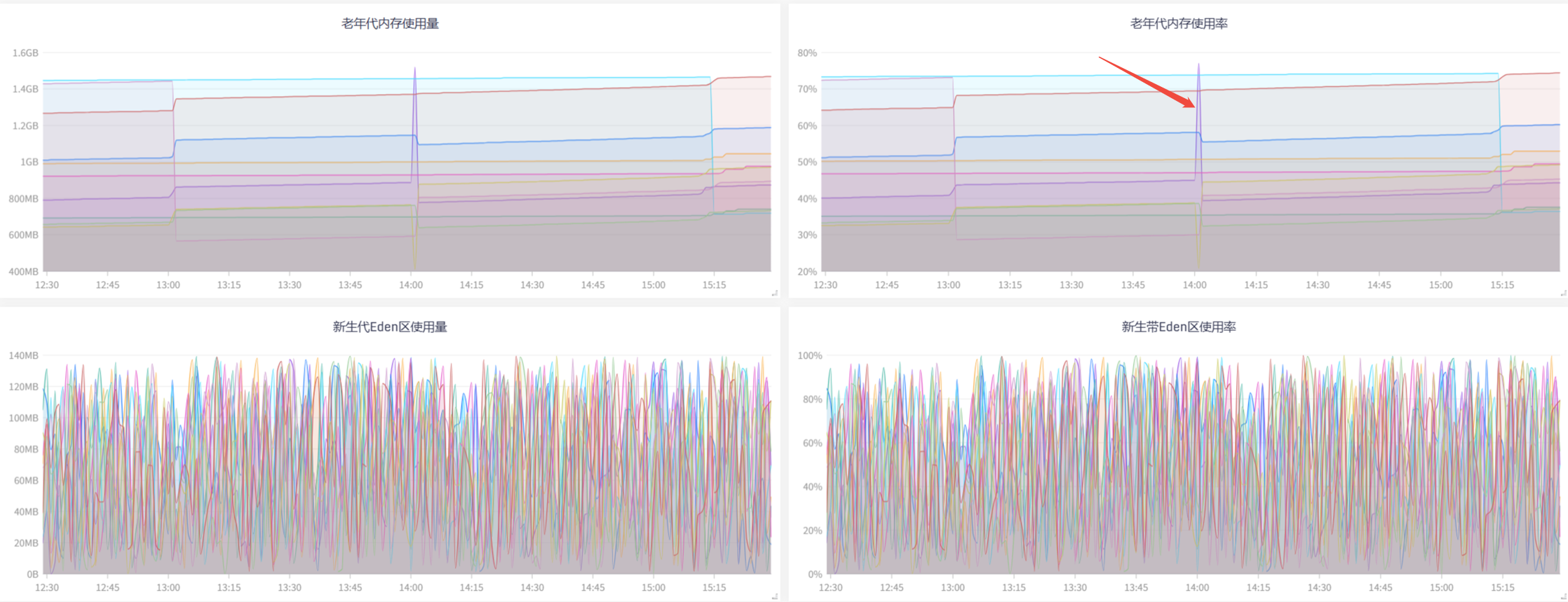
14:00左右,新生代晋升老年代的内存量飙升,老年代使用率快速突破75%(触发CMS阈值),
触发1次CMS GC,且因晋升过快,最终触发Serial Old Full GC,单次耗时近2秒左右,
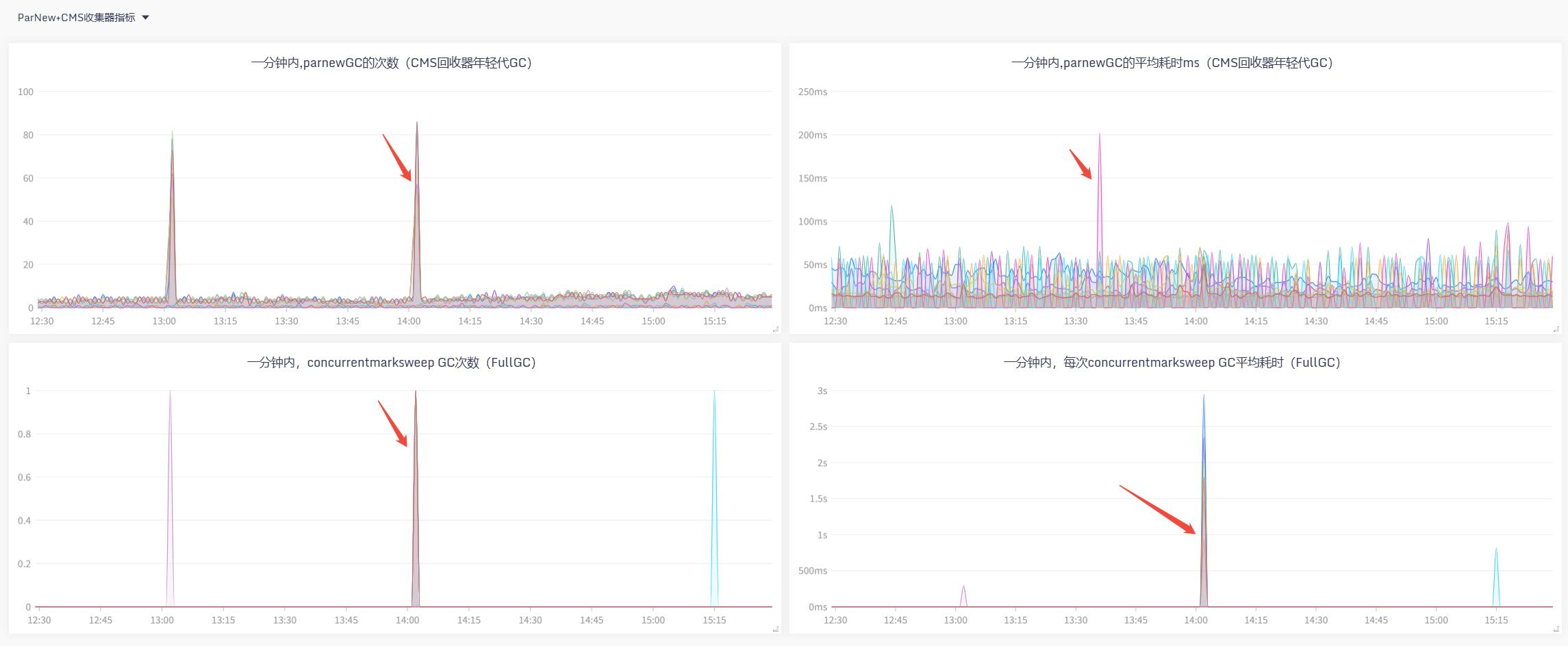
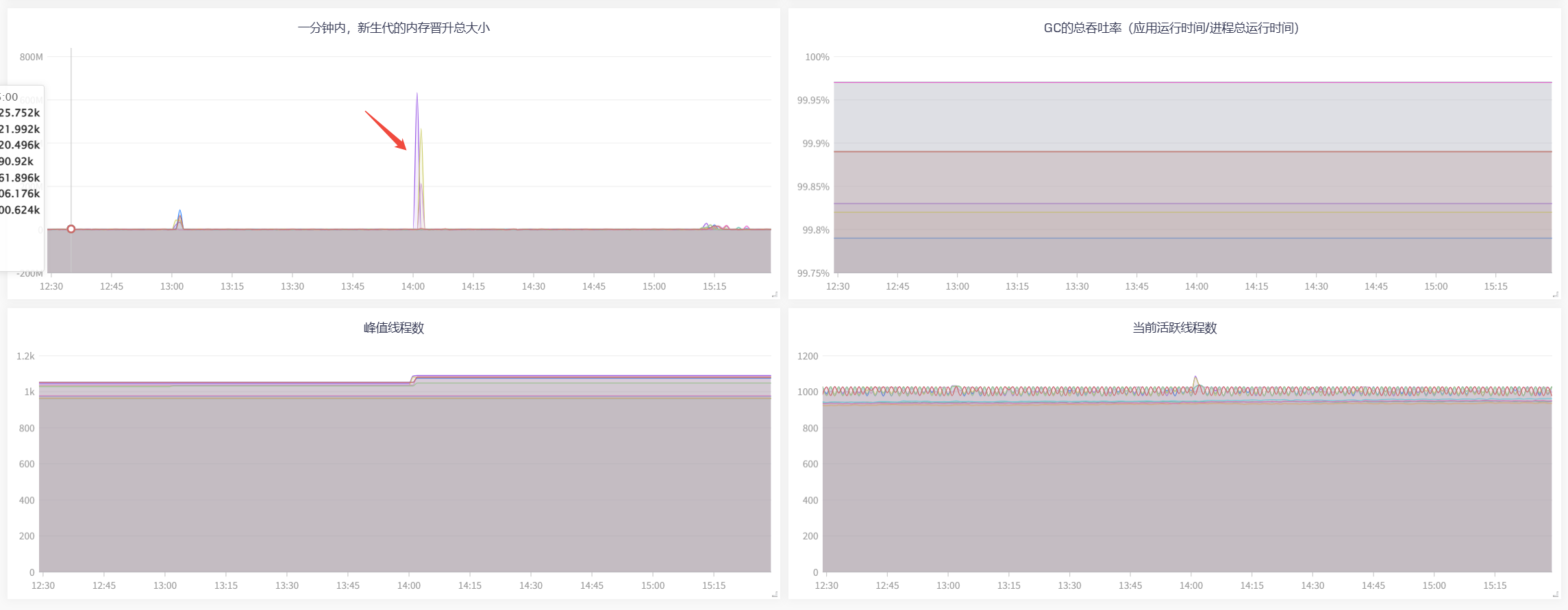
CPU、内存指标,如下,
CPU使用率,40-60是健康水位,这次这个指标表现良好,低于40%,说明CPU资源未充分利用,线程数可能偏少,请求处理效率低;高于60%,说明接近CPU饱和,若突发流量容易导致GC卡顿、线程上下文切换飙升,响应时间变长。
 |  | 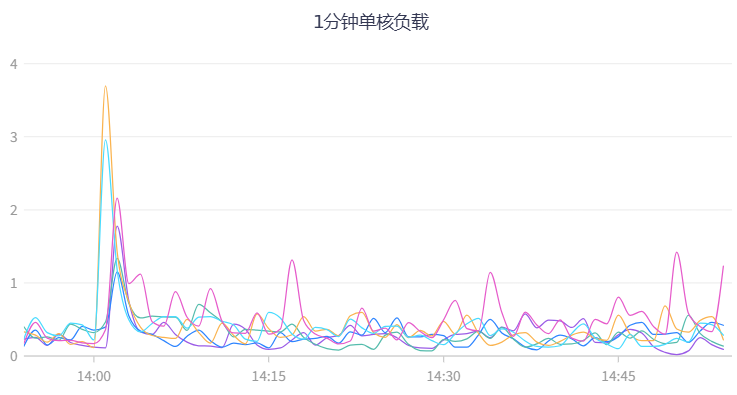 |
1分钟单核负载,表示单个CPU核心在1分钟内,平均有多少个任务(线程/进程)在等待CPU执行+正在CPU上执行。1分钟单核负载是3-4之间,表示3-4个任务抢一个核。单核负载高,CPU使用率低,说明大量线程在等IO;单核负载高,CPU使用率高,CPU才是不够用了。这个时候CPU资源没有利用充分,需要增加服务的线程数,来进一步调优服务器性能。
解决方案
优化线程数,改成多少合理呢?
参考IO密集型对应的业界线程数评估的公式,
1
最优线程数 = CPU核心数 × (1 + IO等待时间/CPU执行时间)
理论上要比对IO等待时间和CPU时间,一般来说,Dubbo服务大部分都是大量时间等IO,业务代码执行时间很短,比如Tomcat的默认线程数也是200,
当前这里Dubbo线程池的线程和队列,分别默认是100、200,threads线程的默认大小是100,最大和核心数一样,队列是线程数的2倍,也就是200。
稍微激进点的配置,两个指标可以先各自扩大一倍,继续观察线上服务运行效果,
1
2
3
4
{
"threads":200,
"queues":400,
}
需要注意的是,适配2C4G的资源约束,要多观察修改之后的线上服务运行状况,这个修改有以下影响,需要评估并注意到,
- 服务器总内存
4G,JVM堆占2G,剩余2G分给系统 +Dubbo线程栈(每个线程栈默认1M,-Xss1m); - 若线程数超过
200,仅线程栈就会占200M+,再加上系统进程/文件缓存,易导致内存紧张; 2核CPU同时只能执行2个线程,线程数过多(如超过30)会导致大量线程处于等待CPU调度状态,反而降低处理效率。
当前的配置,从理论上已经算是在极致的压榨机器的性能了。结合监控动态调整,配置后监控以下指标,再微调,
CPU使用率:理想状态下,业务高峰期CPU使用率严格控制在40-60%,超过55%就应该触发告警(过高说明线程数/业务逻辑有问题);- 线程池队列长度:长期满队列,说明线程数/队列长度需调大,比如长期超过队列容量的
70%,说明流量超过处理能力,需要扩容或限流;长期空队列,说明线程数偏多; - 线程池活跃数:若长期接近
300(max),说明核心线程数200不够,可适当调大core(如300),减少线程创建/销毁的开销; - 内存使用率:监控
JVM堆外内存(线程栈),若物理内存使用率超过80%,需调小-Xss(如-Xss512k),降低单个线程栈内存占用; Dubbo请求响应时间:响应时间稳定且无大量超时,说明配置合理。
JVM还有更激进一点的优化空间,比如,
-Xmn1g,增大Eden区空间,降低Young GC触发频率;-XX:SurvivorRatio=6,扩大Survivor区容量(6:2:2),让临时对象在新生代多存活几轮GC,减少提前晋升;-XX:MaxTenuringThreshold=6,对象晋升年龄阈值偏小,调大让短生命周期对象在新生代完成回收,减少老年代晋升量,可以调大到15;-XX:CMSInitiatingOccupancyFraction=75,流量过来,2C并发回收速度跟不上对象晋升速度,让CMS更早触发并发回收,避免老年代快速填满,比如调小到65。
实际项目服务里,初始线程池都是怎么配置的?
- 核心线程数和最大线程数:先根据经验、项目实际业务需求和硬件资源,拍一个合适的数量上线,之后观察线上服务运行情况,根据实际运行状况调整线程数,直到达到一个合适的水准,适配实际业务的
IO/CPU占比。 - 队列:一旦触碰到拒绝策略,或者长期超过队列的
70%,说明服务器资源不足,流量超过处理能力,应考虑扩容或者限流。
手动排查方法
top + jstack命令定位问题
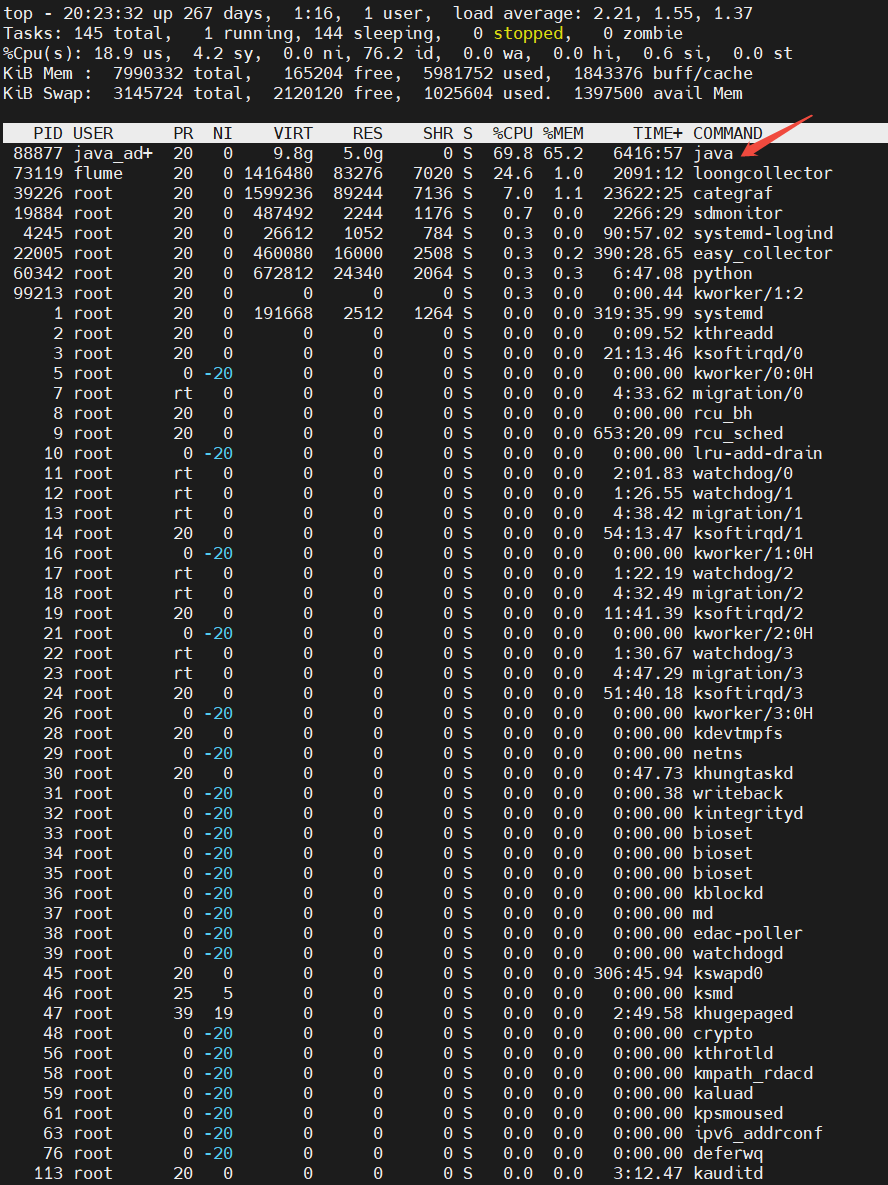
执行top命令,查看CPU占用情况,找到进程的pid
很容易发现,PID为88877的java进程的CPU占比最高(69.8%),且一直很稳定。
1
$ top
 top
top
使用top -Hp命令定位线程
使用top -Hp <pid>命令(Java进程的id号)查看该Java进程内所有线程的资源占用情况(按shift+p按照cpu占用进行排序,按shift+m按照内存占用进行排序)。
1
$ top -Hp 88877
此处按照cpu排序,可以看到现在的服务状态还是可以接受的健康,
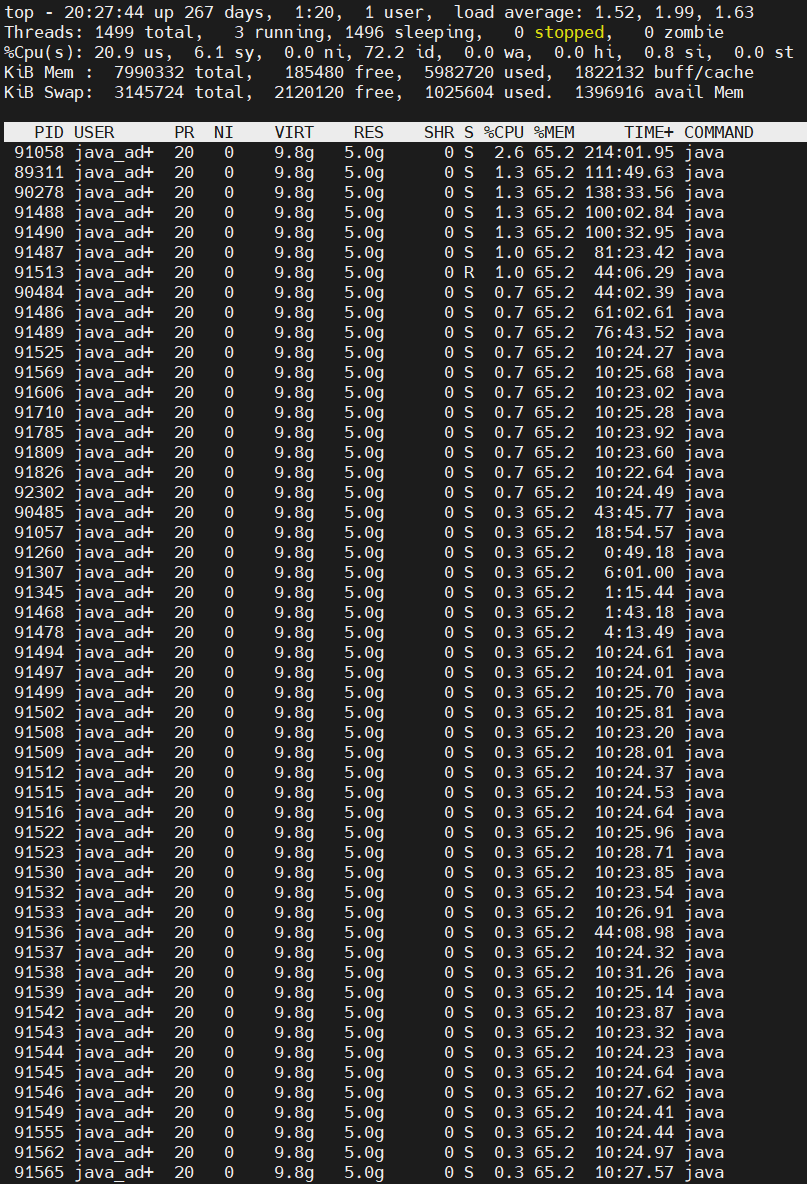 某进程内所有线程的资源占用
某进程内所有线程的资源占用
挑选线程号为91058的线程继续分析,使用jstack命令定位代码,
线程号转换为
16进制printf “%x\n”命令(tid指线程的id号)将以上10进制的线程号转换为16进制,1 2
$ printf "%x\n" 91058 163b2
转换后的结果为
163b2,由于导出的线程快照中线程的nid是16进制的,而16进制以0x开头,所以对应的16进制的线程号nid为0x163b2。采用
jstack命令导出线程快照通过使用
jdk自带命令jstack获取该java进程的线程快照并输入到文件中,1
$ jstack -l 进程ID > ./jstack_result.txt
命令(为
Java进程的id号)来获取线程快照结果并输入到指定文件。1
$ jstack -l 88877 > ./jstack_result.txt
根据线程号定位具体代码
在
jstack_result.txt文件中根据线程号nid搜索对应的线程描述,1
$ cat jstack_result.txt | grep -A 100 163b2
当然,这里也可以直接用
1
$ jstack <pid> | grep -A 200 <nid>
举个例子,
 jstack内容格式
jstack内容格式
main: 线程名称#1: 当前线程ID,从main开始,jvm会根据线程创建的顺序为其线程编号prio: 优先级的顺序,一般默认是5os_prio: 线程对应系统的优先级tid:java内的线程idnid: 操作系统级别的线程id,是一个十六进制
关于线程的信息:
NEW: 线程新建,还没开始运行RUNNABLE: 正在java虚拟机中运行的线程BLOCKED: 被阻塞,正在等待监视器锁的线程WAITING: 无限期等待另一个线程执行特定操作的线程TIMED_WAITING: 等待另一个线程执行操作达到指定等待时间的线程TERMINATED: 已经退出的线程
这里只是演示怎么用jstack定位到CPU资源利用率对应执行的代码,如果遇到线上CPU打满的情况,可以根据这个步骤快速定位问题代码。理论上jstack正常情况下,影响极小,生产环境可安全执行,但还是尽量低峰期执行。
jstack核心原理
jstack是向JVM发送信号(Linux下默认SIGQUIT),让JVM主动打印线程栈,而非外部强制挂起进程。
JVM收到信号后,短暂暂停所有应用线程(STW,Stop-The-World);- 遍历、采集所有线程栈信息;
- 采集完成立刻恢复业务线程运行。
实际影响
- 停顿时间极短
- 普通应用(几百个线程):
STW通常几毫秒~十几毫秒,人/业务几乎无感知。- 线程数极多(上万线程):停顿会变长,但一般也在百毫秒内。
CPU/负载
- 采集栈信息会消耗少量瞬时
CPU,执行完立刻释放,不会持续占用。- 不会宕机、不会丢请求、不会中断连接
- 只是短暂暂停执行,
TCP连接、队列、事务都不受破坏。
风险场景(需要注意)
以下情况不建议频繁/连续执行,否则会放大影响,
JVM已经卡死、死锁、Full GC频繁、OOM
- 本身
JVM状态异常,再触发一次STW,可能让卡顿加重。- 超高并发 + 线程数量上万
- 多次连续
jstack会叠加停顿,影响接口响应。- 和
jmap -dump混用
jmap堆转储STW极久、风险高,线上禁止在业务高峰期dump堆,和jstack区分开。Windows环境
Windows下jstack实现逻辑不同,部分老版本JDK偶发进程假死,线上Windows谨慎使用。
线上最佳实践
- 单次执行完全没问题,排查线程死锁、
CPU高、线程阻塞首选jstack。- 不要循环、高频每秒多次执行。
- 服务负载高、
GC频繁时,尽量低峰期执行。- 优先输出到文件,避免控制台刷屏:
jstack 进程ID > thread.log- 怀疑死锁:直接
jstack -l 进程ID(额外打印锁信息,开销几乎不变)。
arthas更方便、更安全
也可以用arthas定位,arthas和jstack展示的信息差不多,但arthas更加的方便,它的功能也比jstack丰富。
理论上会用到两个命令,dashboard命令查看top n线程,thread命令查看堆栈信息。
- 先来运行
arthas,输入1, - 输入
dashboard命令,可以看到是哪个线程占用CPU最高, - 接下来输入
thread -n 3,表示最忙的前3个线程并打印信息。
CPU占用很高的3大类型,9大场景
CPU飙升是一个常见的问题。在生产环境中,会出现由代码问题导致CPU占用很高,如何诊断出是哪行java代码导致的,是一项重要基本功。先大致梳理一下CPU占用很高的3大类型问题,9大问题场景。
业务类问题
死循环
while(true)
导致
CPU占用率高的,最简单但最具破坏性的编程错误之一,就是死循环。当程序中的循环缺乏正确的退出条件或条件从未满足时,就会出现这种情况,死循环无休止地运行,消耗过多的处理器时间,导致CPU 100%。死锁
发生死锁后,就会存在忙等待或自旋锁等编程问题,从而导致繁忙等待问题。即进程在不释放
CPU的情况下反复检查条件是否满足,会导致CPU占用率居高不下。这种低效率的资源使用会妨碍CPU执行其他任务。不必要的代码块
在不需要的地方使用
synchronized块,会导致线程竞争和上下文切换。针对这种情况的解决方案是,尽量减少同步块的使用范围。
并发类问题
大量计算密集型的任务
计算密集型的任务(比如复杂的数学计算、图像处理、视频编码等)需要大量的计算能力。在没有足够系统资源的情况下运行这些应用程序,可能会导致
CPU占用率达到100%,因为它们试图执行高要求的任务。解决方案是,优化算法,使用更高效的库,或者利用并行计算来分摊。大量并发线程
多个线程同时运行会导致对
CPU资源的竞争,尤其是当其中许多线程都是资源密集型进程时。这会导致所有线程获得的CPU时间减少,当每个线程都试图完成自己的任务时,CPU时间可能会被耗尽。大量的上下文切换
创建过多的线程,导致频繁的上下文切换。解决方案是,使用线程池来管理线程的数量。
内存类问题
内存不足
当系统内存不足时,就会将磁盘存储作为虚拟内存使用,而虚拟内存的运行速度要慢得多。这种过度的分页和交换会导致
CPU占用率居高不下,因为处理器需要花费更多时间来管理内存访问,而不是高效地执行进程。频繁
GC创建大量的短生命周期的对象,频繁触发
GC。解决方案是,优化代码,减少对象的创建,或者调整JVM的参数来优化。内存泄漏
程序持续分配内存但不释放,会导致频繁的
GC。解决方案是,使用内存分析工具VisualVM或者MAT进行检测和修复。