线上服务紧急告警,调优JVM GC
Case
相信很多微服务开发老baby经常会碰到这样一种情景,当你正沉浸式地敲着纯正老代码的时候,OnCall告警群里突然蹦出一堆线上紧急告警,告警信息里明晃晃地写着服务OverLoad过载。这时你不得不从沉浸的编码世界里抽身出来,本着线上告警优先处理的原则,观察基础/业务监控大盘和详细的服务过载日志来定位解决问题。
Tips: 如果短时间找不到问题,可以先临时扩容(虽然不一定有效),先恢复服务业务,再去定位问题,及时止损。
首先看到的是,业务流量激增,
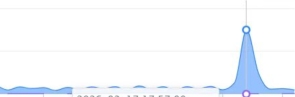 业务请求量激增
业务请求量激增
相应地,会直接带来机器负载升高,应用gc压力增大,甚至还会导致依赖的下游服务或者存储中间件耗时增加,可以调取观察机器负载(比如CPU、内存、网络、磁盘等)、JVM、外部调用及耗时指标监控,直观地获取服务运行状况的第一手资料。
| 机器负载 | ||
|---|---|---|
服务2C4G小型配置 | ||
CPU、内存短时间内过载 | ||
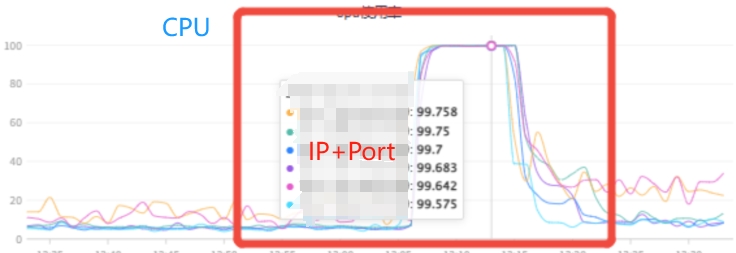 | 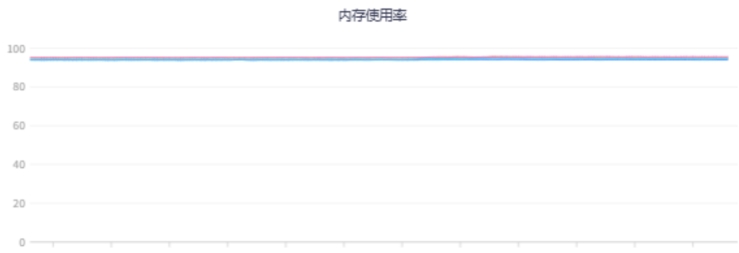 |  |
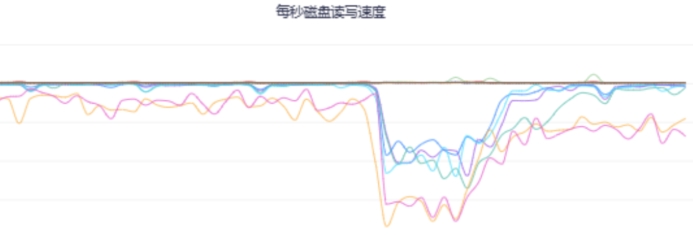 | 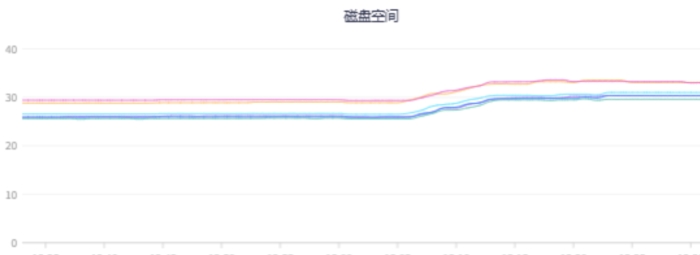 | 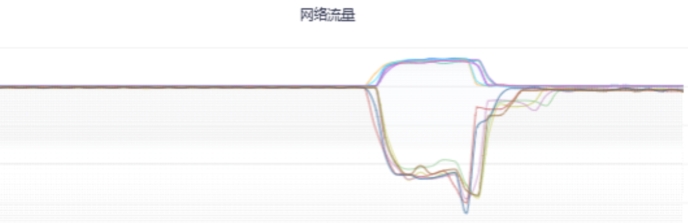 |
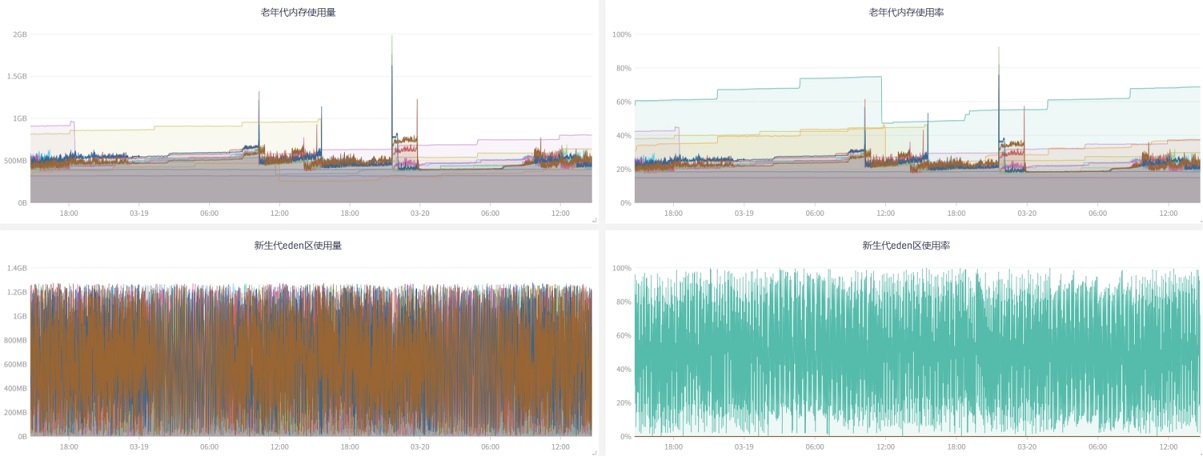
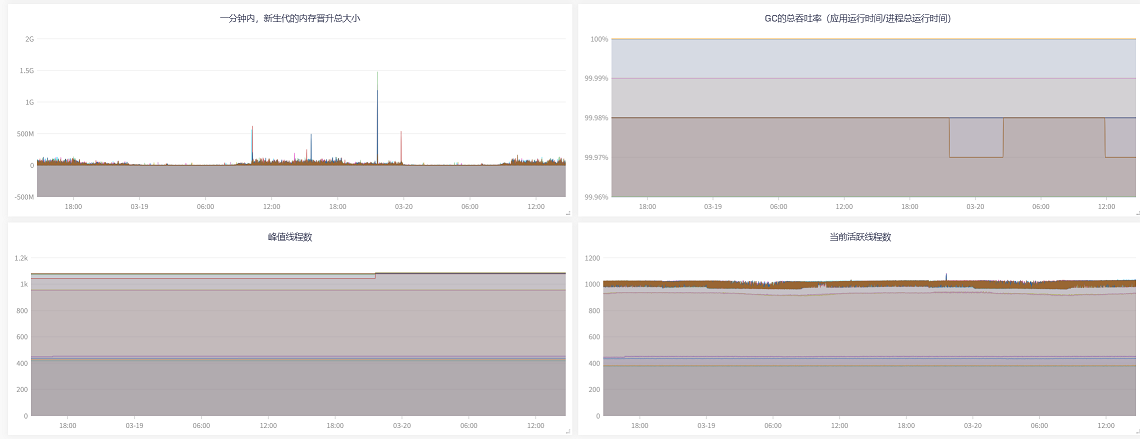
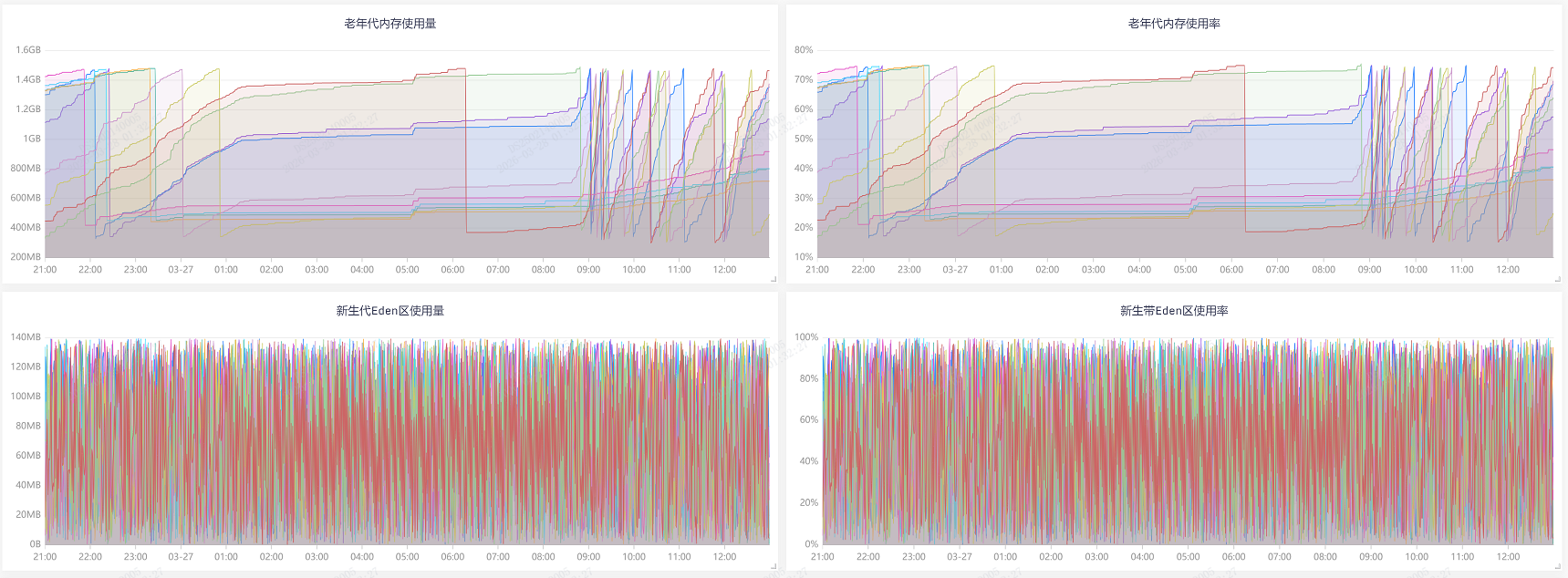
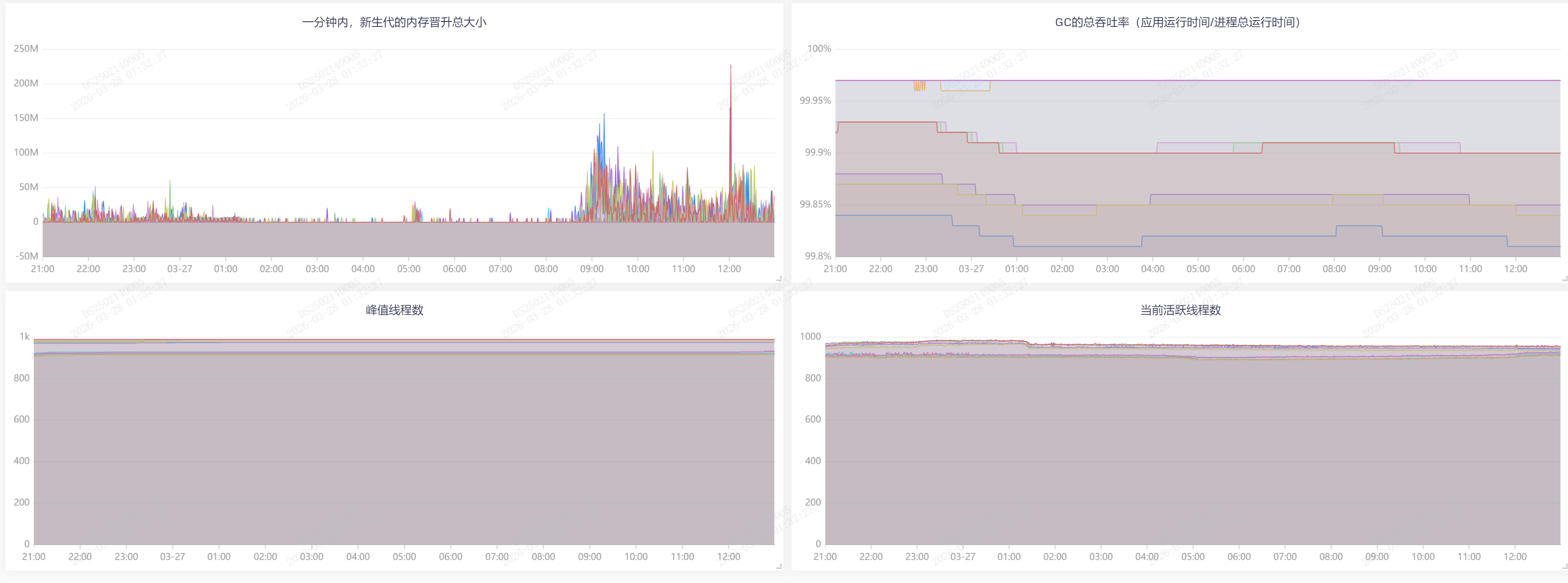
JVM,把时间线拉长一些,可以看到许多时刻有尖刺 |
|---|
 |
 |
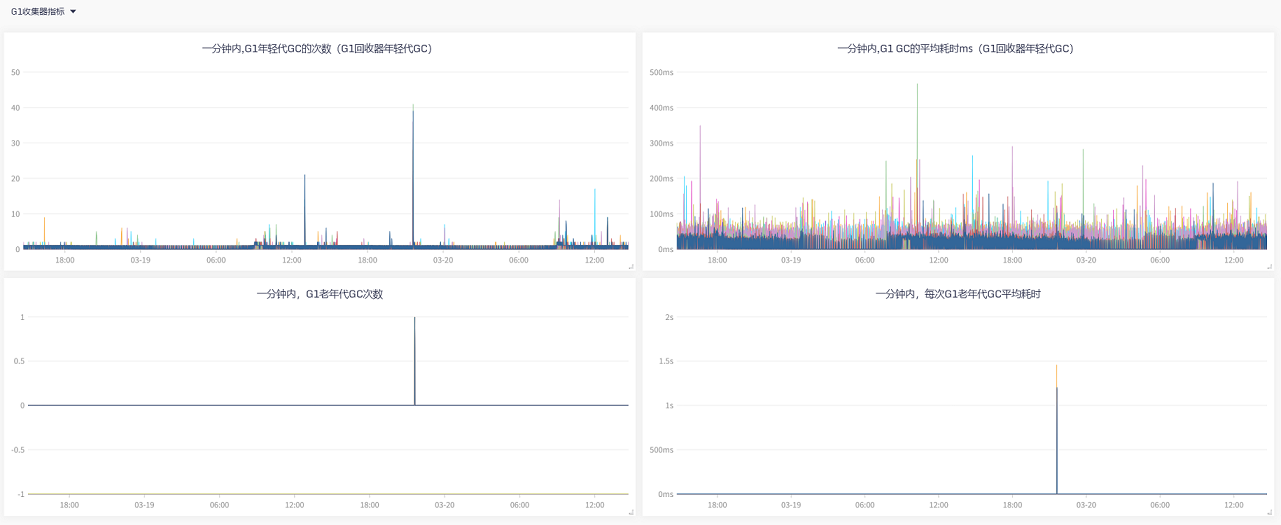 |
JVM,聚焦到尖刺的时刻,可以看到更详细直观的曲线 |
|---|
| 前提:虽有业务流量增加,但也不是能达到需要限流的地步,否则就得考虑限流或者扩容了 |
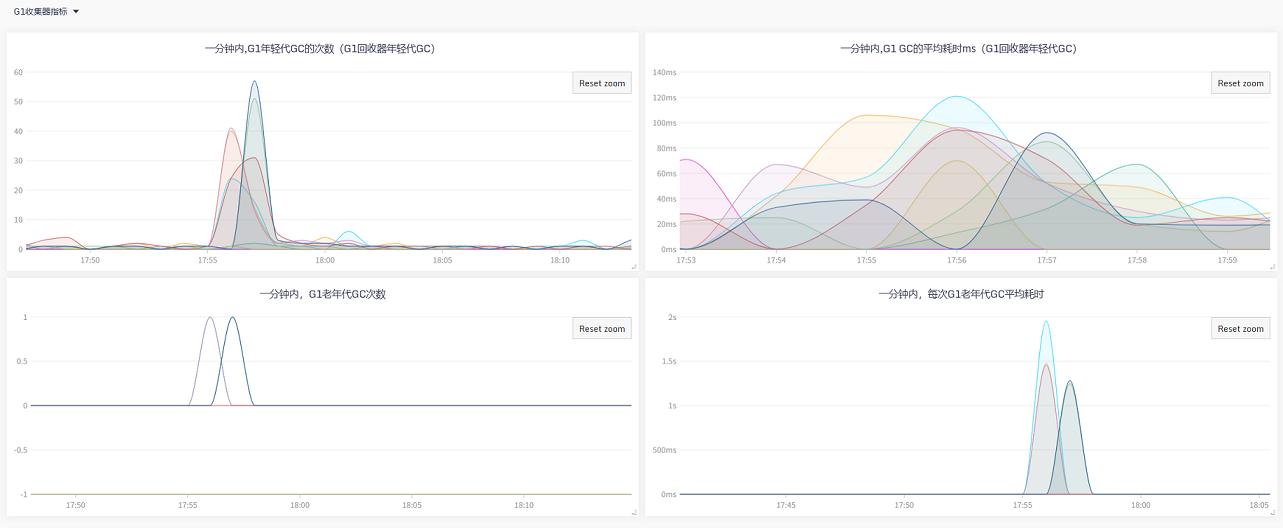
| 看图说话:老年代平常用的其实不多,当新生代疯狂gc,基本都是一次性的对象,导致CPU和内存过载 |
| 随后导致短期内新生代晋升老年代激增,老年代空间不足以容纳从年轻代晋升的对象,导致了频繁FullGC |
| 看起来2C4G配置在CPU、内存相对较小的情况下,服务用G1 Collector收益不高 |
 |
 |
 |
如有需要,还可以继续通过查看过载时打印的日志,了解过载时应用内的线程被哪些请求使用、线程stack日志,以及过载的请求明细,来进一步定位问题。
如果在一个组织健全、分工明确的团队,找到原因后,可通过以下方式针对性地去解决,否则的话,只能默认你能后端全栈了。
- 业务流量激增:先确定流量来源,之后和上游调用方确认是否是正常流量;
- 机器负载升高:找运维协助排查
CPU、内存、网络等基础因素,如果是单台机器问题,可以执行迁移;- 依赖外部系统耗时增加:找下游服务
Owner或者DBA协助排查解决;gc问题:分析服务内存,如果没有dump文件,找运维执行dump,分析dump文件(这一步最好在线下环境复现,线上dump容易产生FullGC)。
JVM参数
查看JVM参数
服务启动时,配置的JVM参数,如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ ps -ef | grep java
/usr/local/jdk1.8.0_192/bin/java \
-Dfile.encoding=utf-8 \
-Djava.awt.headless=true \
-Djava.net.preferIPv4Stack=true \
-server \
-Xms2g -Xmx2g \
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m \
-XX:CICompilerCount=4 \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/xxx/logs/xxx_logs/dump \
-XX:ErrorFile=/xxx/logs/jvm_error_file_logs/java/java_error%p.log \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=100 \
-XX:G1HeapRegionSize=4M \
-XX:ParallelGCThreads=2 \
-XX:+UseStringDeduplication \
-Dcom.sun.management.jmxremote.port=50000 \
-Dcom.sun.management.jmxremote.rmi.port=50000 \
-Dcom.sun.management.jmxremote.ssl=false \
-Dcom.sun.management.jmxremote.authenticate=false \
com.xxx.Main
参数解析
| 基础配置 | |
|---|---|
-Dfile.encoding=utf-8 | 文件编码设置为UTF-8 |
-Djava.awt.headless=true | 无头模式,服务端不需要图形界面 |
-Djava.net.preferIPv4Stack=true | 优先使用IPv4 |
-server | 使用Server模式JVM(针对长时间运行的服务优化) |
| 内存配置 | |
|---|---|
-Xms2g -Xmx2g | 堆内存固定2GB(初始=最大,避免运行时扩容) |
-XX:MetaspaceSize=128m | 元空间初始大小128MB |
-XX:MaxMetaspaceSize=256m | 元空间最大256MB |
G1垃圾收集器配置 | |
|---|---|
-XX:+UseG1GC | 使用G1垃圾收集器 |
-XX:MaxGCPauseMillis=100 | 目标最大GC停顿时间100ms |
-XX:G1HeapRegionSize=4M | G1 Region大小4MB |
-XX:ParallelGCThreads=2 | 并行GC线程数2 |
-XX:+UseStringDeduplication | 开启字符串去重(减少重复字符串内存占用) |
JIT编译配置 | |
|---|---|
-XX:CICompilerCount=4 | JIT编译器线程数4 |
| 故障诊断配置 | |
|---|---|
-XX:+HeapDumpOnOutOfMemoryError | OOM时自动生成堆转储 |
-XX:HeapDumpPath=… | 堆转储文件路径 |
-XX:ErrorFile=… | JVM崩溃日志路径(%p会替换为进程ID) |
JMX远程监控 | 通过JMX端口50000连接VisualVM/JConsole实时监控 |
|---|---|
-Dcom.sun.management.jmxremote.port=50000 | JMX端口50000 |
-Dcom.sun.management.jmxremote.rmi.port=50000 | RMI 端口同为50000 |
-Dcom.sun.management.jmxremote.ssl=false | 不使用SSL |
-Dcom.sun.management.jmxremote.authenticate=false | 不需要认证 |
JMX安全风险:ssl=false + authenticate=false,意味着任何人都可以连接JMX端口进行监控甚至执行操作,生产环境建议开启认证。
监控建议:也可以加上GC日志参数,来观察实际触发情况。
-XX:+PrintGCDetails(打印详细GC信息)
-XX:+PrintGCDateStamps(GC日志带时间戳)
-Xloggc:/xxx/logs/gc.log(GC日志输出路径)
G1内存分布
监控大盘显示,年轻代(Young Generation)在疯狂gc,我们可以根据JVM参数,估算下 G1内存分布。
从显示配置的参数中,可以知道,
- 堆大小:
-Xms2g -Xmx2g = 2GB Region大小:-XX:G1HeapRegionSize=4M
G1GC没有固定的Eden区大小,它是动态调整的,但我们可以估算其初始默认值和动态变化范围,
Young Generation默认占比:G1默认Young Gen占堆的5%-60%,初始约5%;Eden与Survivor比例:默认-XX:SurvivorRatio=8,即Eden:S0:S1=8:1:1。
G1内存区域估算 | |
|---|---|
| 堆总大小 | 2048 MB |
Young Gen初始 (5%) | ~102 MB |
Young Gen最大 (60%) | ~1228 MB |
Eden占Young Gen | 8/10 = 80% |
Eden初始大小 | ~82 MB |
Eden最大大小 | ~983 MB |
综上可知,Young Gen区在此配置下大约在102MB ~ 1228MB之间动态变化,Eden区在此配置下大约在82MB ~ 983MB之间动态变化,初始约82MB左右。G1GC会根据-XX:MaxGCPauseMillis=100的目标暂停时间自动调整Young Gen和Eden的大小。由于G1是动态调整的,我们也可以通过以下方式查看实际值。
1
2
3
4
5
# 添加 GC 日志参数
-Xlog:gc*:file=/path/to/gc.log
# 或者使用 jmap 查看
jmap -heap <pid>
这个配置下的GC触发时机
根据这个配置(G1GC + 2GB 堆 + 4M Region),GC会在以下情况被触发。
Young GC | |
|---|---|
| 最频繁 | 频率: 取决于对象分配速率,通常几秒到几十秒一次 |
| 触发条件 | 说明 |
Eden区满 | 当Eden区分配满时触发,G1会动态调整Eden大小 |
| 目标停顿时间 | G1根据MaxGCPauseMillis=100预测并调整回收的Region数量 |
Mixed GC | |
|---|---|
Young + 部分Old | |
| 触发条件 | 说明 |
| 堆占用超过阈值 | 默认InitiatingHeapOccupancyPercent=45%,即堆使用超过~920MB时启动并发标记 |
| 并发标记完成后 | 接下来的Young GC会变成Mixed GC,回收部分老年代Region |
Full GC | |
|---|---|
| 最慢,应避免 | |
| 触发条件 | 说明 |
| 晋升失败 | 老年代空间不足以容纳从年轻代晋升的对象 |
| 并发标记期间堆耗尽 | 标记速度跟不上分配速度 |
| 大对象分配失败 | 无法找到足够的连续Region(大于2MB的对象,即Region/2) |
Metaspace不足 | 元空间超过256MB |
关键配置
- 堆大小:
2GBRegion大小:4MBRegion数量:2048MB / 4MB=512个- 大对象阈值:
4MB / 2=2MB(超过此大小直接进老年代)- 触发并发标记: 堆占用
~45%≈920MB
JVM调优
问题分析
结合上面JVM参数和监控大盘的表现,来分析下导致告警的原因,以及接下来的优化方向。
| 存在问题 | |
|---|---|
2GB堆内存 | 对服务日常业务场景够用,但如果有大量并发任务或数据处理,可能需要增加(成本允许的情况下)。 |
G1在小堆上收益低 | G1适合6G+大堆,2G堆开销反而大 |
ParallelGCThreads=2 | 数值偏低,已经限制了并行度,G1优势发挥不出来。但对于2C的服务器来说,不能再高了,根本在于资源受限。如果服务器CPU核心数较多,这个值会限制GC效率。通常建议设为CPU核心数的1/4到1/2。 |
UseStringDeduplication | 需要额外CPU做字符串去重,2C下不划算,CPU资源比较重要 |
| 短生命周期对象多 | 适当加大Young区,减少Young GC频率更有效 |
MaxGCPauseMillis=100 | 对于后台任务的服务来说,是合理的,不需要特别低的延迟。 |
整体来看,上面的
JVM参数是一个针对小型后台任务服务的配置,内存适中,GC配置保守,适合资源受限的环境。 但对于2C4G且大量短生命周期对象的场景,CMS更合适,新生代可以相对给大点。
CMS + ParNew
修改对应CMS GC的JVM参数,如下,仅供参考,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
$ ps -ef | grep java
/usr/local/jdk1.8.0_192/bin/java \
-Dfile.encoding=utf-8 \
-Djava.awt.headless=true \
-Djava.net.preferIPv4Stack=true \
-server \
-Xms2g -Xmx2g \
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m \
-XX:CICompilerCount=4 \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/xxx/logs/xxx_logs/dump \
-XX:ErrorFile=/xxx/logs/jvm_error_file_logs/java/java_error%p.log \
-XX:+UseConcMarkSweepGC \
-XX:+UseParNewGC \
-XX:NewRatio=1 \
-XX:SurvivorRatio=8 \
-XX:MaxTenuringThreshold=6 \
-XX:CMSInitiatingOccupancyFraction=75 \
-XX:+UseCMSInitiatingOccupancyOnly \
-XX:+CMSParallelRemarkEnabled \
-XX:+CMSScavengeBeforeRemark \
-XX:+UseCMSCompactAtFullCollection \
-XX:ParallelGCThreads=2 \
-Dcom.sun.management.jmxremote.port=50000 \
-Dcom.sun.management.jmxremote.rmi.port=50000 \
-Dcom.sun.management.jmxremote.ssl=false \
-Dcom.sun.management.jmxremote.authenticate=false \
com.xxx.Main
参数解析
| 参数说明 | ||
|---|---|---|
-XX:+UseConcMarkSweepGC | - | 启用并发标记清除 (CMS) 垃圾收集器 |
-XX:+UseParNewGC | - | 启用并行新生代收集器 (ParNew) 与CMS配合使用 |
-XX:NewRatio=1 | Young:Old = 1:1 | Young区 = 1G,比默认大很多,可选 |
-XX:SurvivorRatio=8 | Eden:S0:S1 = 8:1:1 | Eden ≈ 800MB,可选 |
-XX:+UseCMSInitiatingOccupancyOnly | - | 只使用CMSInitiatingOccupancyFraction设置的阈值来触发CMS回收,而不是使用默认的自适应策略 |
-XX:MaxTenuringThreshold=6 | 6次 | 短生命对象不容易晋升到老年代 |
-XX:CMSInitiatingOccupancyFraction=75 | 75% | 老年代占用75%时启动CMS |
-XX:+CMSParallelRemarkEnabled | - | 启用CMS并行标记阶段的重新标记,提高CMS回收的效率 |
-XX:+CMSScavengeBeforeRemark | - | Remark前先做次Young GC,减少重标记耗时 |
-XX:+UseCMSCompactAtFullCollection | - | Full GC时对老年代进行压缩整理,减少碎片 |
CMS垃圾收集器,可以减少垃圾回收时的停顿时间,适合对响应时间要求较高的应用。
效果预期
Eden区: 从~82MB提升到~800MBYoung GC频率: 大幅降低CPU消耗: 去掉StringDeduplication后更低
| 潜在问题及应对方案 | |
|---|---|
CMS碎片化导致Full GC | 老年代用的不多,问题不大;真出现这种问题,线上服务可加-XX:+UseCMSCompactAtFullCollection,对老年代做压缩整理,减少碎片 |
Young区太大单次GC变长 | 监控Young GC时间,如果超过100ms,可调小NewRatio,或直接使用默认值(MewRatio=2) |
CMS在JDK 9+被废弃 | JDK 8没问题,暂不用担心 |
-XX:NewRatio=1 -XX:SurvivorRatio=8,也可以先不用指定,一般使用默认值就行。
这两个参数在JDK 8中的默认值如下,
| 参数 | 默认值 | 说明 |
|---|---|---|
-XX:NewRatio | 2 | 新生代与老年代的比例为1:2,即新生代占堆的1/3 |
-XX:SurvivorRatio | 8 | Eden区与Survivor区的比例为8:1:1 |
使用默认值时,堆内存分布如下,(以2G堆为例)
- 总堆:
2G - 新生代:
~682M(1/3)Eden:~546M(8/10 of新生代)S0:~68M(1/10 of新生代)S1:~68M(1/10 of新生代)
- 老年代:
~1365M(2/3)
如果不使用默认值,用当前配置,那么
-XX:NewRatio=1,新生代占1/2(比默认更大)-XX:SurvivorRatio=8,与默认相同
相比之下,使用默认值,新生代会变小(
1/3 vs 1/2),对于大多数应用,默认值是合理的,毕竟Young区太大,单次GC就会变长。 如果你的应用对象存活时间短、创建频繁(如Web服务、短任务处理),默认的NewRatio=2通常就够用了。 如果发现Young GC频繁或晋升过快,可以再考虑调大新生代。
上线观察
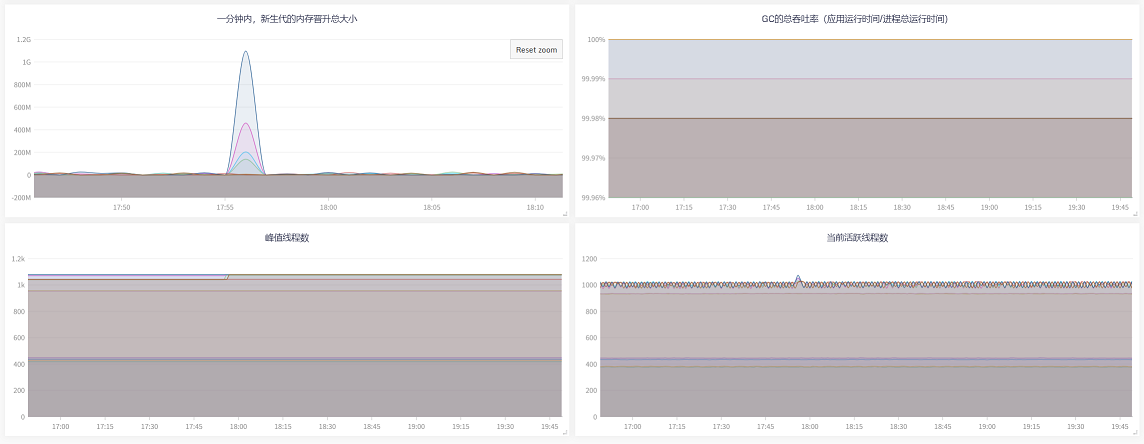
优化上线后的业务流量激增,增幅比之前还稍大点,
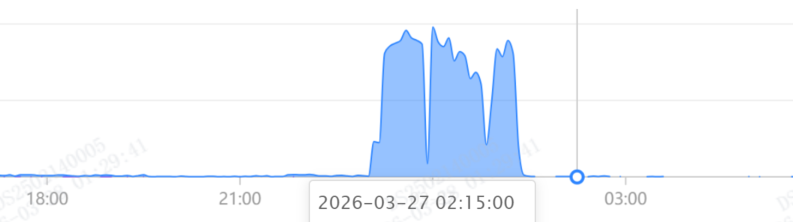 业务请求量激增(优化后)
业务请求量激增(优化后)
| 机器负载 | ||
|---|---|---|
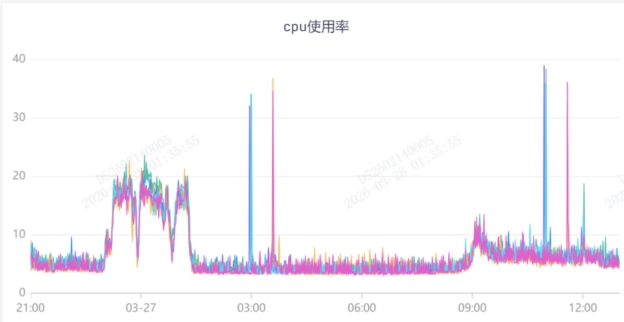
| 明显下降的关键指标 | ||
CPU、内存 | ||
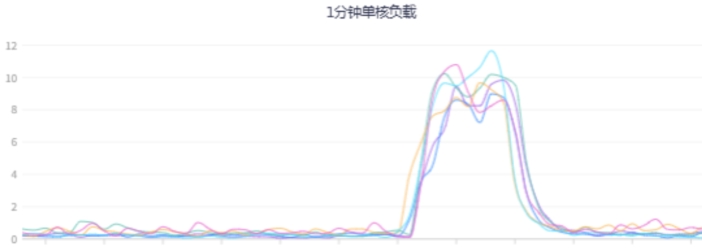
| 一分钟单核负载指标 | ||
 |  | 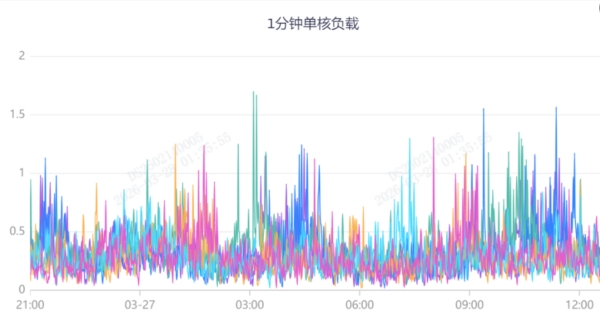 |
 |  |  |
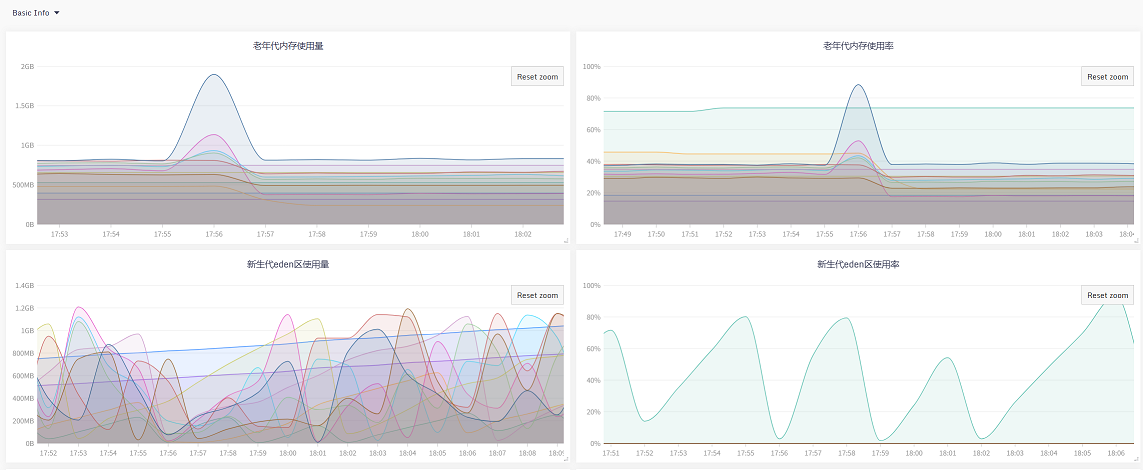
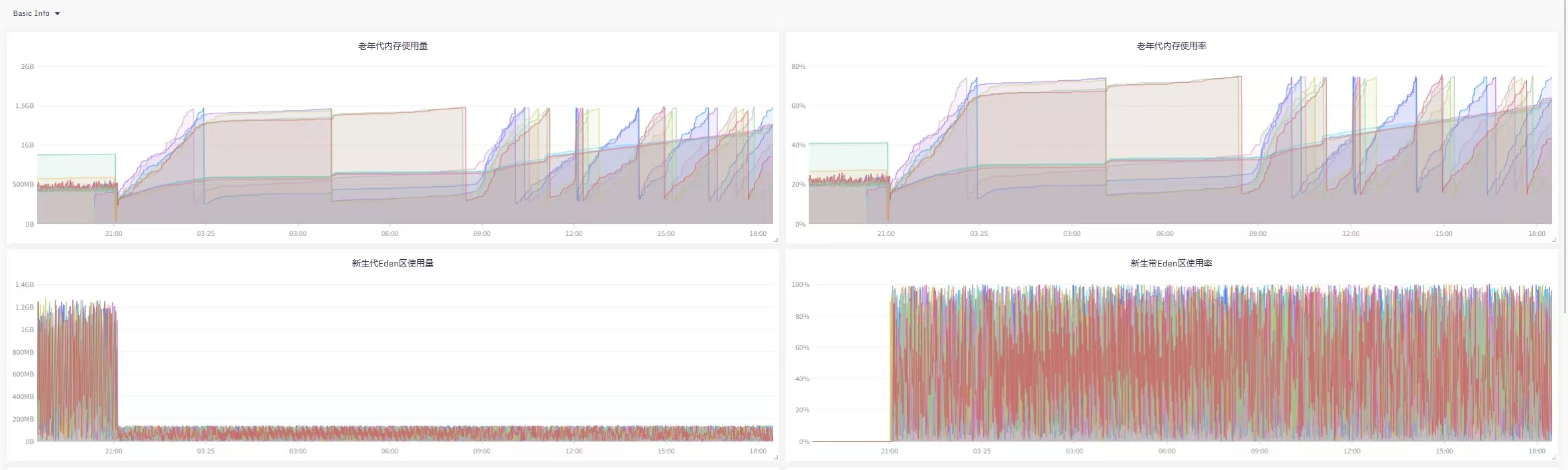
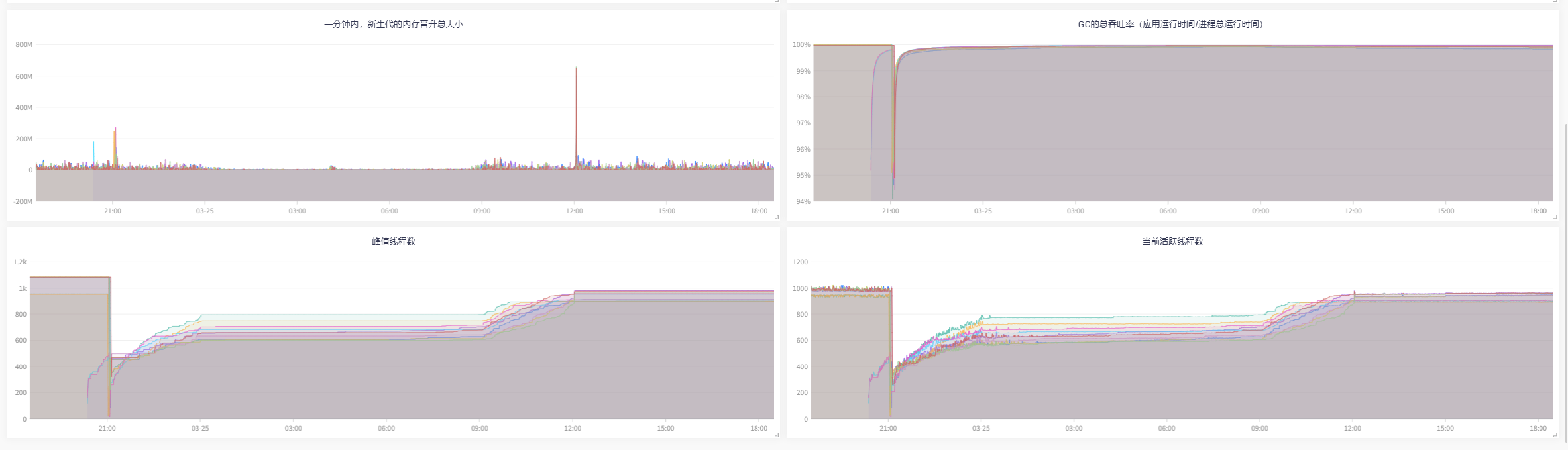
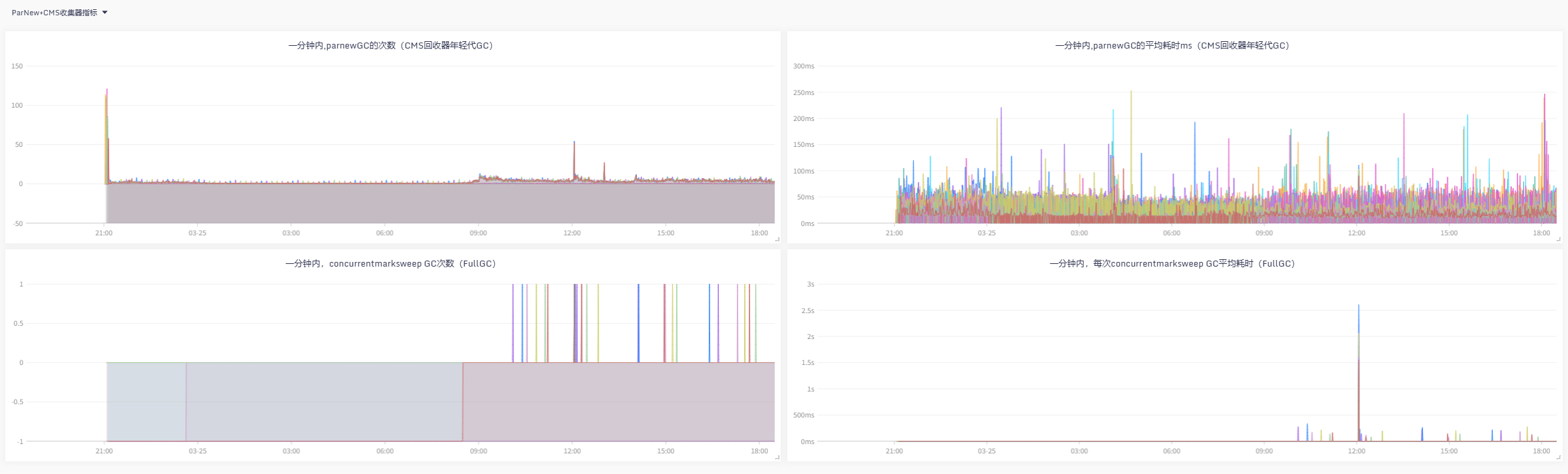
看图说话:新生代使用量降下来了,同时Young GC的CPU资源利用率也降下来了, |
|---|
虽然CMS在并发阶段也会占用一部分CPU资源,但现在不会导致用户线程停顿,效果要比G1好太多, |
目前应用不会由于CPU过载导致的短期内晋升老年代太多的问题,也就不会频繁FullGC,服务平稳运行。 |
注意:后期应持续关注应用是否会在CPU不足的情况下,有明细的卡顿现象。 |
 |
 |
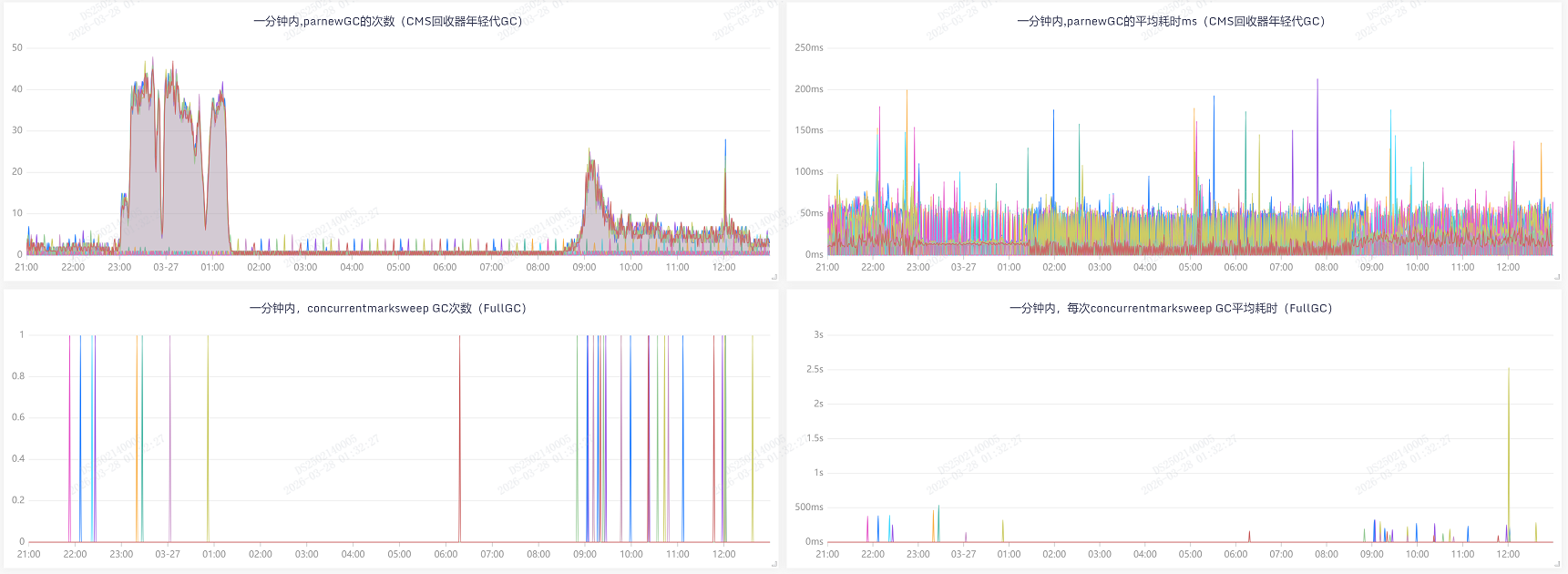 |
再看看,优化上线前后的GC指标对比,效果立马显现 |
|---|
 |
 |
 |
End 🌈🌈🌈
生活依然那么美好,可以继续撸代码了。