白话意图识别
定位
意图识别,是自然语言处理(NLP)的一个分支领域——自然语言理解(NLU)/口语理解(SLU)。
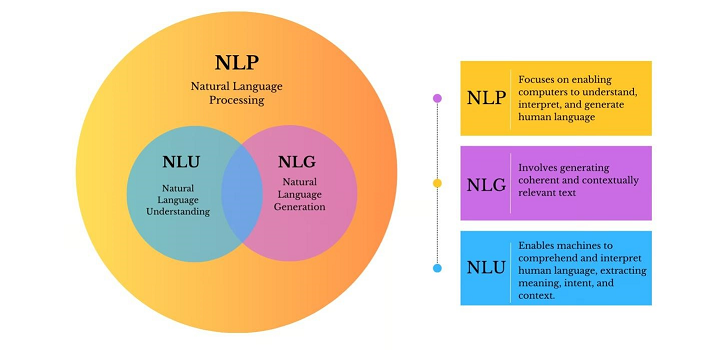 NLP、NLU、NLG之间的关系(图片来自网络)
NLP、NLU、NLG之间的关系(图片来自网络)
理解——对话系统场景+意图识别
举个例子
举个正常对话的例子,
1
2
3
4
5
6
7
8
9
10
11
>> 用户:帮我推荐一家餐厅
>> Bot:几个人?
>> 用户:2个人
(Bot赶紧拿出本本记下)
>> Bot:好的,请问什么时候去吃?
>> 用户:今天晚上,差不多6点左右到
(Bot赶紧记下)
>> Bot:好的,想吃中餐还是西餐?
>> 用户:想吃牛排!算了算了都快200斤了,而且单位附近貌似没有,那就吃椰子鸡吧!
(Bot努力理解了一下,然后打开地图APP开始寻找附近的椰子鸡)
>> Bot:找到一家,距离我们2.4km
理解NLU
在对话系统中,寻找椰子鸡、拿小本本记下等操作不是自然语言,这一类操作称为对话动作(dialog action),如果这里Bot是个机器人,就是系统动作(system action)。如果用户通过自然语言的方式发出了类似的指令,比如“帮我推荐一家餐厅”,那么用户发出的自然语言命令就称为用户动作(user action)。用户动作可以看作用户输入的语义表示,将用户动作从用户的自然语言文本,或语音中解析出来的过程,称为自然语言理解(NLU)或口语理解(SLU)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 上述第一轮对话中,用户问,帮我推荐一家餐厅?
// 意图识别的输出数据样例,应如下所示,
{
"text": "帮我推荐一家餐厅",
"domain": "restaurant",
"intent": "QUERY",
"slots": {
"name": "餐厅",
"person_num": "",
"timestamp": "",
"type": ""
}
}
上述样例,在智能客服对话系统中,用户输入帮我推荐一家餐厅,系统可以通过意图识别判断用户意图,是查询一家合适餐厅,并填充提前设计好的槽位。但很难通过一轮对话就把所有提前设计好的必选槽位填满(除非用户说了能填满所有槽位的一句话,Bot你好,帮我推荐一家餐厅,2个人,今天晚上6点,想吃椰子鸡)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Bot你好,帮我推荐一家餐厅,2个人,今天晚上6点,想吃椰子鸡
// 意图识别的输出数据样例,应如下所示,
{
"text": "帮我推荐一家餐厅",
"domain": "restaurant",
"intent": "QUERY",
"slots": {
"name": "餐厅",
"person_num": "2",
"timestamp": "今天晚上6点",
"type": "椰子鸡"
}
}
在对话系统的NLU中,意图识别(Intent Detection)和槽位填充(Slot Filling)是两个子任务,意图识别可以看作NLP分类任务,槽位填充可以看作序列标注任务。意图识别和槽位填充息息相关,甚至说高度互相依赖,将两个任务进行联合,充分利用意图和槽位中的语义关联,这两个任务joint training是一个很常用的方式。
从目前的趋势来看,大体上做法有两大类,
- 多任务学习:按
Multi-Task Learning的套路,在学习时最终的loss等于两个任务的loss的weight sum,两者在模型架构上仍然完全独立,或者仅共享特征编码器。- 交互式模型:将模型中
Slot和Intent的隐层表示进行交互,引入更强的归纳偏置,研究显示,这种方法的联合NLU准确率更高。
NLU的作用
- 有效引导对话流程
- 提高对话效率
- 增强用户体验
怎么理解意图和槽位?
从对话动作在计算机中的表示出发,一种简单的想法,就是把每个action表示成全局唯一的id,但action与action之间经常存在很深的耦合关系。
比如预定附近的椰子鸡与预定椰子鸡之间是上下位关系,预定西二旗附近的椰子鸡与预定西三旗附近的椰子鸡有一个共同的父action——预定椰子鸡。
所以把所有的action打平成平级的表示肯定不合理,但要完全建模也非常不容易,因此一种折中的方式就是表示成“意图+槽位”,用意图来表示一个模糊的目标,使用该意图预定义的一系列槽位来限制这个模糊目标,使得目标具体化。
1
2
3
4
5
6
7
8
9
例如,预定西二旗附近的椰子鸡就可以表示成
{
"domain": "restaurant",
"intent": "订餐"
"slots": {
地点: 西二旗,
餐厅名: 椰子鸡
}
}
订餐就是PM预定义的一堆意图中的一个,这个意图下PM预定义了一堆槽位及其可能的取值,其中地点和餐厅名就是预定义的槽位,很可能还预定义了其他槽位,比如就餐人数,菜系,联系方式等,只不过在这个case中的取值统统都是None了。
实际产品中的意图和槽位设计可能要复杂的多,比如有的槽位是不可枚举的(比如时间),槽位有冲突,甚至槽位内要嵌套槽位等,这些得具体情况具体分析。
当对话系统cover的领域很多时,可能意图会多达成百上千,这时意图识别模型的决策空间变得过大,且各个意图共享同一个模型,每增加一个新意图就要重训模型,导致其他意图也受影响了。不仅导致意图识别模型难训,而且会导致系统变得难以维护。一种更好的办法是在意图识别之前再加一级领域分类(domain classification)。
使用姿势——NLU阶段输出的意图和槽怎么用?
意图识别(单轮对话)
自然语言输入到用户动作这种结构化语义表示的过程就是NLU,以上的NLU说的都是单轮意图识别,仅针对用户的单句输入进行意图判断,聚焦于独立的、一次性的用户表达,不考虑之前或之后可能的对话内容。
单轮意图识别中,意图和槽位按需输出使用即可。如果场景不需要信息抽取,只需判断用户意图即可用于后续处理,就不用填充槽位。如若需要信息抽取,可以按照SMP2019数据集格式给出slot槽位的内容。
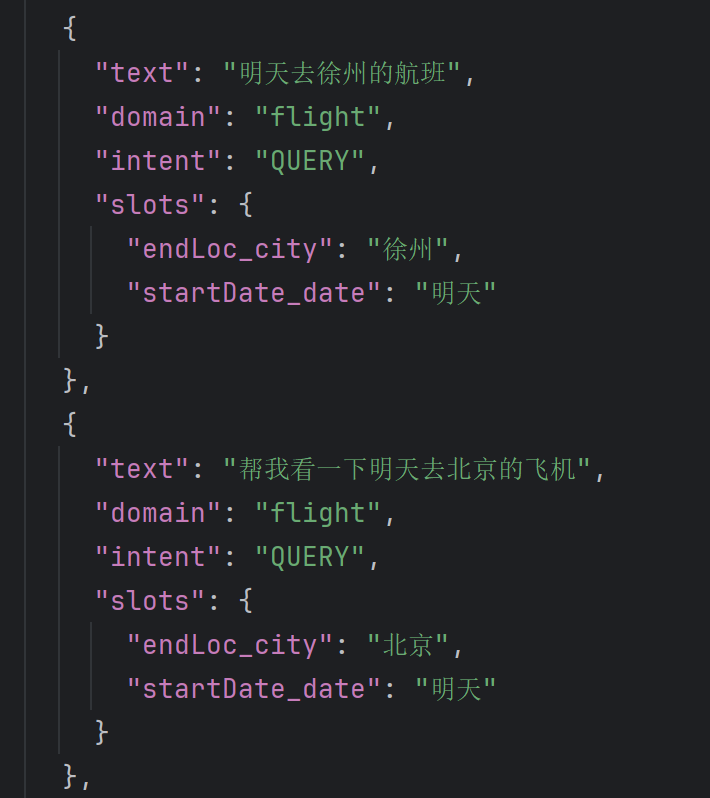 SMP2019数据集样例
SMP2019数据集样例
另外,意图识别数据需要不断的收集与维护,初始数据集不用很多,但要在项目中做好数据采集与清洗,定期进行模型训练并更新,对于一些bad case需要人为判断缺陷并改善数据集中的类似case,正确率才会越来越高。
意图识别(多轮对话)
对话系统pipeline
在对话系统pipeline中,仅使用当前query往往不一定能给出整个多轮对话的正确意图,还需要查看历史的对话信息。多轮意图识别系统需要能够及时捕捉到这种意图的转变,并准确理解每个意图在整个对话流程中的作用,可以基于上下文槽位来关联。
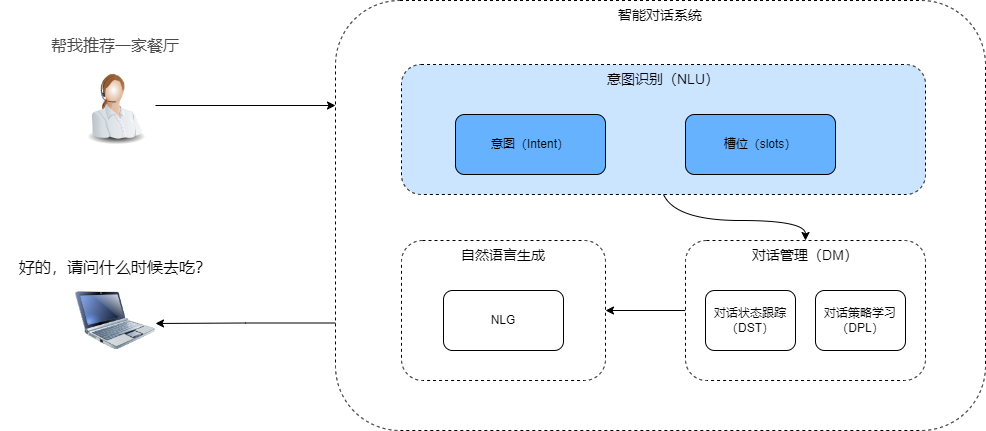 智能对话系统pipeline(从rasa中抽象得出)
智能对话系统pipeline(从rasa中抽象得出)
- NLU模块,对用户的
utterance进行理解,包括意图识别和槽位填充。例如:I need something that is in the east part of the town" -> "Inform: location = east
DST模块,以每个对话turn的NLU模块输出作为输入,输出的是dialog state。例如:USR: I am looking for a moderate price ranged Italian restaurant; SYS: De luca cucina is a modern European restaurant in the center; USR: I need something that is in the east part of the town.-> inform: price = moderate, location = east
DPL模块,输入是DST模块输出的dialog state,输出的是dialog act(包括intent和slot-value pairs)。例如:inform: price = moderate, location = east" -> "provide: restaurant_name = Curry prince, price = moderate, address = 452 newmarket road
NLG(Natural Language Generation) 模块,输入是dialog act,输出一句完整的、通顺的话,作为机器的回复。例如:provide: restaurant_name = Curry prince, price = moderate, address = 452 newmarket road" -> "Curry Prince is moderately priced and located at 452 newmarket road.
承上启下——对话管理模块
多轮对话的核心是对话管理模块(Dialog Management,DM),它主要包含2大部分,分别是对话状态跟踪(Dialog State Tracking,DST)和对话策略学习(Dialog Policy Learning,DPL)。这里说的,承上是NLU,启下是NLG。
人可以进行多轮对话,很大程度和我们能记住并使用沟通过程中产生的信息和共识,这里有两个关键的能力,一个是记住,另一个是使用。
对话管理承担了多轮对话中信息的记录和使用,记录就是DST,使用就是DPL。
这点和我们日常聊天很像,我们在对话过程中,一方面是能接收双方交换的信息,另一方面也会根据自己的目标或想法制定不同的对话策略,从而达到自己的目标。
想个问题,意图和槽位,在多轮对话系统中,一般是怎么使用的?
为了摸清楚用户的具体意图(把该填的槽填上,该解决的取值冲突解决掉),往往要像上面Bot有个小本本来记下对话的关键信息,以供对话策略模块使用,帮助进行每一轮的决策。
这里的这个小本本就称为对话状态(dialog state),完成这个小本本更新的过程就称为DST。
这里的关键信息主要就是意图和对应的槽位取值,DST是个小本本,负责记录整个对话全过程积累下来的重要信息。那么这个对话状态该怎么描述呢?显然最容易想到的就是NLU中用“意图+槽位”的方式来描述。
多轮决策——完成对话目标
系统可以根据当前轮NLU模块解析出来的用户动作和小本本(积累的对话状态)来完成相应的“推理”(完成这个过程的模块被称为对话策略模块),决定下一步是去澄清意图,say goodbye还是其他什么动作,并且后续NLG模块(自然语言生成)也会根据DP模块输出的对话决策(系统动作)来决定回复的内容(即结构->文本)。
最后生成——NLG
假如我们的pipeline多轮对话系统最终可以作出合理决策(action)了。比如用户说“好的,谢谢”,那么我们的系统经过NLU、DST和DP,得出了“说再见”的系统动作,于是就要有一个模块将系统动作(即结构化语义表示)来翻译成自然语言输出,比如“不客气哦,下次再见啦~”这种结果,完成这个结构->文本的模块就是NLG。
算法——意图识别
常见的算法
| 大类 | 类别 | 示例 | 详述 |
|---|---|---|---|
| 传统方法 人工编写大量规则来解析语义 灵活性不够 语义理解深度有限 上下文感知能力不足 | 基于规则 | jieba、hanlp、正则等 | 基于规则的方案往往需要应用到分词器,比如hanlp等。通过分词后,会返回预先设置的关联短语或词汇(没命中返回空即可),然后返回意图。 |
| 相似度算分 | 余弦相似度、Jaccard相似度、欧式距离、 词向量+余弦相似度等 | Jaccard相似度适合短文本集合比较;余弦相似度适合高维稀疏文本; 欧式距离适合数值型数据匹配(需标准化); 词向量+余弦相似度可以处理语义深度分析。 | |
| 机器学习 | 最大熵、SVM、HMM等 | 在处理文本时,大多聚焦于局部的状态转移概率,对上下文连贯的长序列信息整合能力欠佳。 | |
| 传统向量检索 | TF-IDF、BM25等 | 基于词频统计(TF-IDF)、概率模型(BM25)生成稀疏向量,仅关注词汇匹配,缺乏跨模态和语义泛化能力。 | |
| 深度学习 使用深度学习做意图识别 一般是文本分类深度学习框架 需要人工设定分类类别和标注数据 使用分类模型训练与推理部署 | CNN | TextCNN | 堆叠多尺寸卷积核提取局部语义特征,适用于电商评论分类、用户意图粗粒度识别等场景。 |
| 注意力+CNN | SENet | 动态加权不同特征通道的重要性,提升细粒度意图识别能力。 | |
| 分层注意力网络 | Hierarchical Attention Networks for Document Classification | 采用层次化注意力架构,先对词级特征加权,再聚合为句级表示。 | |
| 序列模型 | RNN、LSTM | RNN与LSTM增强序列建模能力,LSTM和GRU通过门控机制缓解梯度消失,但处理超长文本时效率低下。 | |
| Transformer架构 注意力机制 | 自注意力 | Transformer | 基于自注意力机制的全新架构范式,可直接捕捉长距离依赖,例如我要订明天从北京到上海的机票中订与机票的强关联。流程: 输入文本 → Token嵌入 + 位置编码 → 多层自注意力编码 → 全局平均池化 → 分类层输出意图标签。 |
| 向量检索 | BGE 论文重点在样本数据和训练方法, 训练方法如下, 1.RetroMAE预训练 2.通用文本上fine-tune 3.特定任务上fine-tune | 基于Transformer架构的通用向量生成模型,将用户输入编码为语义向量;通过向量相似度计算匹配预定义的意图类别。不直接参与分类决策,而是优化特征表示层以提高下游任务的性能。 向量检索的目的是将输入 query匹配到知识库里面与之相似的其他query。这里需要使用 embedding(向量化)和retrival(检索),向量化的模型很多,例如bge、simcse和promcse等;检索的工具也有很多,例如 Faiss、Milvus和Hologres等。通过向量检索后,会返回top3相似query及相似度值。 | |
| 大模型 Encoder-Only Eg. BERT | 预训练模型 (RoBERTa、ALBERT等) + TextCNN | 中小规模预训练模型(大模型技术)与轻量级CNN的混合架构。 | |
| Joint BERT BERT for Joint Intent Classification and Slot Filling 对抗性多任务学习 | Joint BERT的核心是联合训练意图分类与槽位填充两个任务,通过共享底层BERT编码器的参数,实现语义特征的统一提取,同时优化两个目标。 | ||
| 大模型 Decoder-Only 生成的方式做分类问题, 天生时效性不好 | 大模型 + Prompt | 不需要微调,开发成本低,适用于需要快速上线,对延时要求不高,分类相对简单的场景。 缺点: 对垂类领域分类的识别有一定局限性; 由于对模型推理能力有一定要求,选用大尺寸模型会带来一定延迟开销。 | |
| 大模型 + Prompt + RAG | 不需要微调,RAG解决垂类领域知识的问题,直接使用prompt的形式给到大模型,然后大模型返回意图结果。缺点: 需要做数据预处理,有一定开发成本; 知识库内容较多或质量不佳时,可能引起模型幻觉和分类冲突; 相比上一种方案,会增加向量召回部分的延迟,且模型要求依然在 14b以上,有一定延迟问题。 | ||
| 大模型 + 微调 基模选择:比如Qwen | 使用小尺寸模型进行SFT(Supervisor Fine-Tune),需要微调,意味着需要人工标注一定量的数据,然后给大模型微调训练。通过小尺寸模型解决延迟问题,通过微调解决数据增强问题。选用 LoRA方式进行微调用大模型微调需要注意以下几点: 1.大模型选择; 2.文本长度设置; 3.标注数据的质量和数量; 4.后续模型迭代的便捷性等。 |