白话BGE
Overview
BGE,BAAI General Embedding,北京智源人工智能研究院(BAAI)在2023年推出的Bert类通用文本嵌入模型。
BGE论文中,提出了C-PACK,一个中文Embedding领域的资源包,C-Pack包括三个关键资源:C-MTEB、C-MTP和C-TEM。
C-MTEB为中文Embedding领域的benchmark;C-MTP为中文语料库中提取的成对数据集;C-TEM是一套涵盖多种参数规模的Embedding模型。
BGE还介绍了使用到的特殊训练方法。
RetroMAE预训练(数据集:悟道、Pile)- 通用文本上
fine-tune(数据集:C-MTP unlabeled) - 特定任务上
fine-tune(数据集:C-MTP labeled)
BGE有3个参数版本,small(24M)、base(102M)、large(326M),还区分不同中英版本,已开源。
C-PACK
C-MTEB
在过去的几年里提出的研究中文Embedding的几个数据集如CMNLI、DuReader等都是独立策划的,每个数据集只关注Embedding的一个特定功能。论文中提出的C-MTEB(Chinese Massive Text Embedding Benchmark)是为建立适当的benchmark,作为MTEB的中文扩展,可以全面评估中文Embedding的所有功能。C-MTEB包括35个公共可用数据集,数据集根据它们评估的Embedding的任务进行分类,分为6类,
- 检索任务(
Retrieval):对于每个查询,它在语料库中查找Top-k个相似的文档。 - 重排序(
Re-ranking):根据Embedding的相似度对候选文档重新排序。 - 语义文本相似度(
STS):基于两个句子的Embedding相似度来衡量它们的相关性。 - 分类任务(
Classification):基于label做输入embedding预测。 - 文本对分类(
Pair-classification):这个任务处理一对输入句子,它们的关系由Embedding相似度来预测。 - 聚类任务(
Clustering):聚类任务是将句子分成有意义的类。
我理解是按照定义这里的分类任务应该表述为回归任务。另外上述有几个任务可能不好区分,STS和Pair-classification都基于Embedding相似度来实现的。但STS是判断两个文本是否表达相似的语义,Pair-classification是判断两个文本是否具有一定的关系(如:标题与文章的关系)。
C-MTP
C-MTP(Chinese Massive Text Pairs),是一个庞大的数据集,从labeled和unlabeled的中文语料库中提取,用于训练Embedding模型。
unlabeled的数据主要来自网络,对于每一篇文章,提取(标题、段落)形成一个文本对。从网络和其他公共资源中挑选的文本对不能保证密切相关,因此,本文使用了一种简单的策略进行过滤:第三方模型Text2VecChinese2来对每个文本对的关系强度进行评分,并删除得分低于阈值的样本。labeled的数据使用的是T2-Ranking、DuReader等公开数据集,虽然它比unlabeled的数据少得多,但大多数数据都是从人工注释中整理出来的,从而确保了相关性的高可信度。
C-TEM
C-TEM(Chinese Text Embedding Models),是一套涵盖多种参数规模的Embedding模型,有三种可选的参数规模:小型(24M)、基础(102M)和大型(326M),它们为用户提供了在效率和有效性之间进行权衡的灵活性。C-TEM中的模型已经经过了良好的预训练,并且对各种任务具有很强的通用性。同时,如果将Embedding应用于特定场景,它们也可以进一步微调。
训练方法
RetroMAE预训练
RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
基于掩码自编码器(Masked Auto-Encoder)的面向检索导向的预训练范式,用Wudao纯文本语料训练,利用了RetroMAE,重建污染的编码向量;
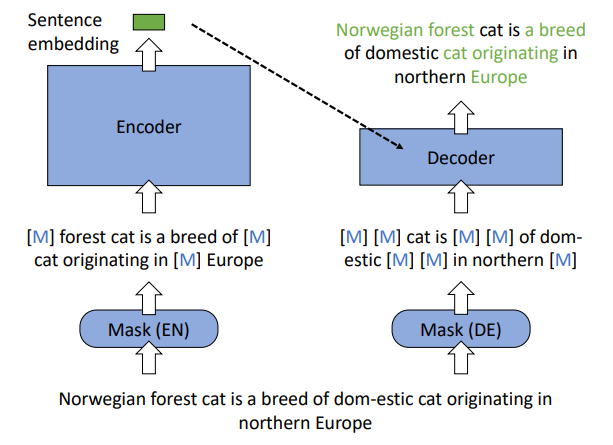 RetroMAE预训练(图片来自网络)
RetroMAE预训练(图片来自网络)
关键设计
- 训练时使用
mask过的文本输入encoder,得到句子embedding;再次对文本输入mask后,与句子embedding拼接,共同输入decoder,得到重建后的句子。 - 非对称的模型结构,
encoder拥有像BERT一样全尺寸的transformer,decoder只有一层的transformer。 - 非对称的掩码比例,
encoder:15%-30%,decoder:50%-70%。
核心思想
auto-encoding对编码质量的要求更高,传统的自回归模型在解码过程中更关注前缀,而传统的MLM模型只掩盖一小部分(15%)的输入。相比之下,RetroMAE对解码过程中的大部分输入进行了激进的掩码,因此,重构不仅依赖解码器的输入,还更依赖句子嵌入,这将强制编码器深入捕捉输入的语义。
具体方法
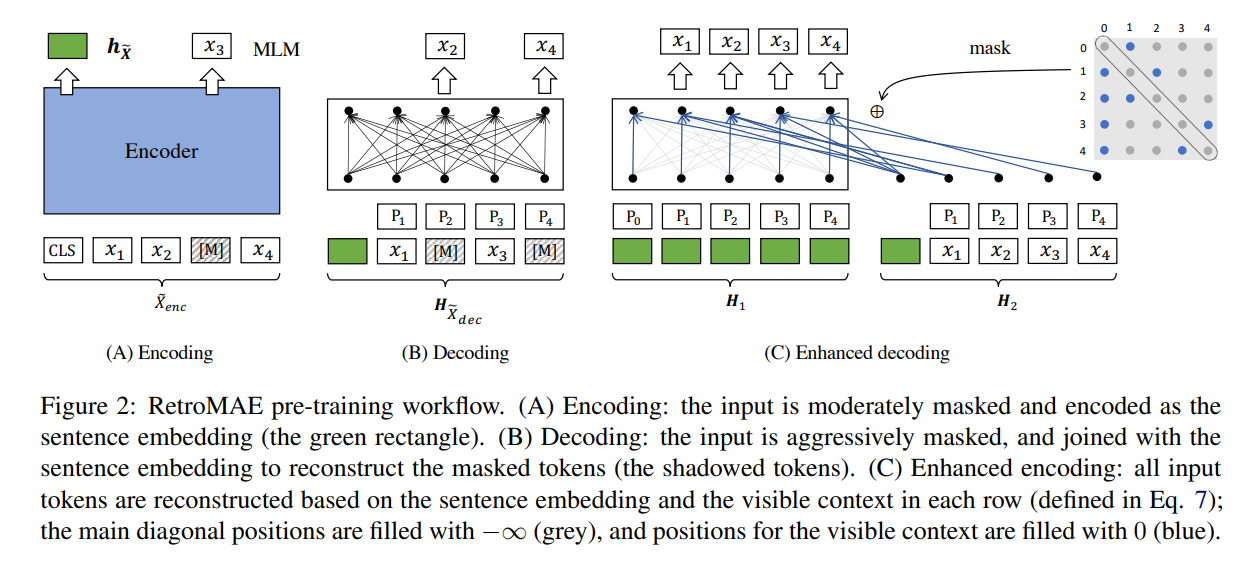 RetroMAE预训练方法(图片来自网络)
RetroMAE预训练方法(图片来自网络)
Encoding
- 随机用特殊
token把输入文本mask掉,然后输入BERT(12层,hidden_dim=768)。 - 最终输出的
[CLS] token作为整句的embedding。 - 像
BERT一样预测被mask的token,计算损失,得到𝐿𝑒𝑛𝑐
Decoding
- 再次对输入文本进行
mask,然后将输入文本的encoder得到的句子embedding与输入文本的embedding进行拼接,送进单层transformer。 - 使用所有被
mask的token与真实词的交叉熵的和作为decoding阶段的损失𝐿𝑑𝑒𝑐。
Enhanced Decoding
这是RetroMAE论文最特殊的地方,作者认为原有的decoding策略得到的信息不够,主要体现在以下方面,
- 交叉熵的计算仅仅基于被mask掉的那部分
token。 - 每个被
mask的token在重建时都基于同一个上下文信息,也就是说在经过decoder得到一个hidden state后,所有token的重建都是基于这个hidden state的。
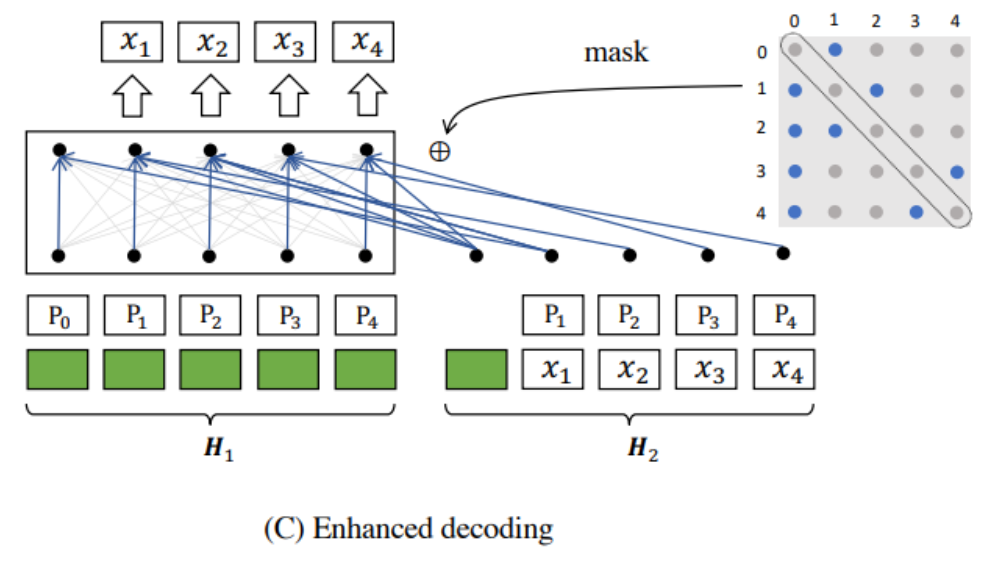 RetroMAE Enhance Decode(图片来自网络)
RetroMAE Enhance Decode(图片来自网络)
基于此,提出了新的enhanced decoding,从输入的句子中得到更多的训练信号(训练信号就是让损失函数收敛的信号),根据不同的上下文执行重建任务。
通过双流注意力(two-stream self-attention,同时处理局部和全局信息)和特定位置注意掩码(position-specific attention mask,动态控制解码时可见的上下文范围),M掩码率很高,同时可以利用除了特殊tokens之外的所有tokens来训练模型,确保所有token参与重建过程,这样一来,训练语料的利用率很高,提升语义利用效率。
这种设计既增加了训练信号的多样性,又避免了传统MLM仅利用15%掩码token的局限性。
假设输入的token序列长度为𝑁−1
- 将
encoding阶段获得的句子embedding(也就是前面得到的[CLS] token)重复𝑁份,变成长度为𝑁的序列,并加上位置编码,作为decoder的其中一个输入𝐻1。 - 将
encoding阶段获得的句子embedding,和输入的token序列(没有mask)拼接,组成长度为𝑁的序列,并加上位置编码,作为decoder的第二个输入𝐻2。 decoder做attention计算时,𝐻1作为𝑄,𝐻2作为𝐾和𝑉。- 使用
mask矩阵把attention矩阵mask掉,逻辑如下:每个token能看到的token都是通过采样得到的(但看不到自己),且都能看到首个token,因为首个token是encoder产出的句子embedding的信息。 - 用
enhanced decoding生成的向量做句子重建,使用所有被mask的token与真实词的交叉熵的和作为decoding阶段的损失𝐿𝑑𝑒𝑐。
Loss
训练loss即为上述的𝐿𝑒𝑛𝑐+𝐿𝑑𝑒𝑐。
通用文本上fine-tune
用C-MTP无标签(unlabeled)数据集训练,对比学习从负样本中如何区分出成对的文本。
特定任务上fine-tune
用C-MTP有监督(labeled)数据集训练,由于标签数据是多任务的,所以加入了指令微调实现多任务下的微调。
BAAI/bge-large-zh-v1.5
举个例子,bge-large-zh-v1.5
https://huggingface.co/BAAI/bge-large-zh-v1.5