白话BERT
Overview
BERT
BERT,全称Bidirectional Encoder Representations from Transformers,翻译成中文,就是Transformer双向编码器特征。
BERT本质上是一个两段式的NLP模型。
- 第一个阶段叫做
Pre-training,跟WordEmbedding类似,利用现有无标记的语料训练一个语言模型。 - 第二个阶段叫做
Fine-tuning,利用预训练好的语言模型,完成具体的NLP下游任务。
BERT的主要贡献是进一步将这些发现推广到深层双向架构,使得相同的预训练模型可以成功应对一组广泛的NLP任务。
双向怎么理解?
BERT模型,使用了Transformer里边的Encoder。把每个词输入Encoder,前面能看到后面所有的词,后面也能看到前面所有的词,没有任何遮掩(mask),是一个双向的学习过程。
BERT预训练模型有哪些?
BERT的作者提出了两种标准配置:BERT-base和BERT-large。
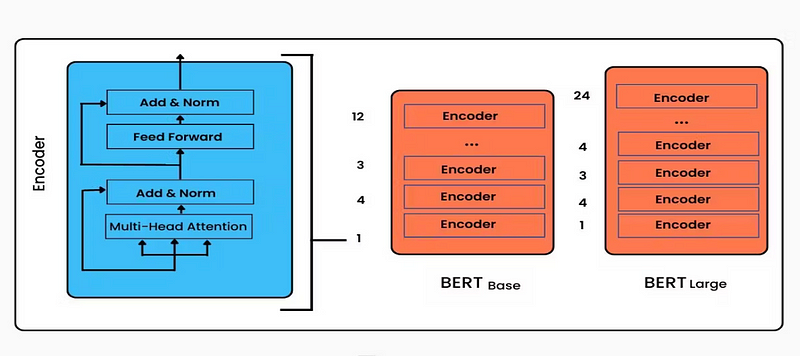 BERT-Base & BERT-Large(图片来自网络)
BERT-Base & BERT-Large(图片来自网络)
为了在计算资源有限的情况下使用BERT,研究者们提出了几种更小的模型配置,分别是BERT-tiny、BERT-mini、BERT-small、BERT-medium。这些模型在参数量和计算复杂度上进行了简化,但仍然保留了BERT的核心特性。
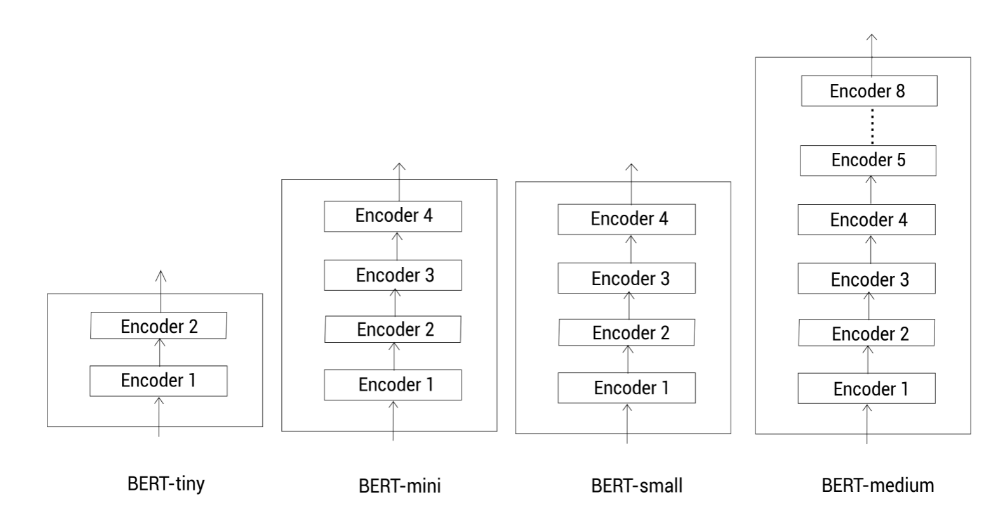 BERT 更小的模型配置(图片来自网络)
BERT 更小的模型配置(图片来自网络)
Pre-training
Google已经投入了大规模的语料和昂贵的机器帮我们完成了Pre-training过程。
输入
针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的向量由其对应的词向量(Token Embedding)、段向量(Segment Embedding)和位置向量(Position Embedding)相加产生。
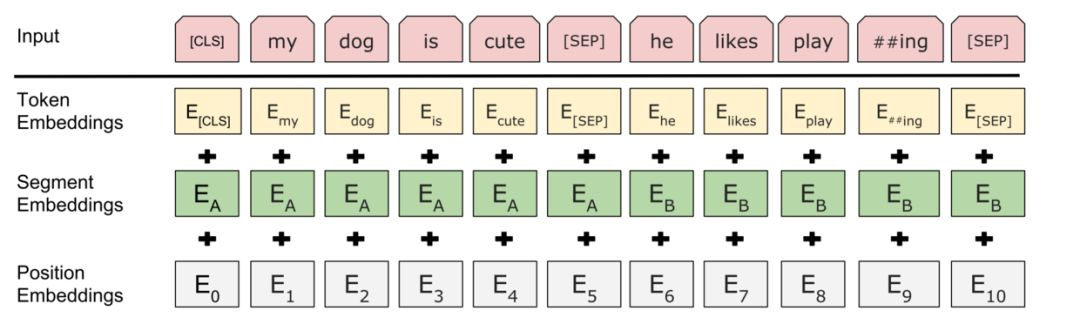 BERT Input(图片来自网络)
BERT Input(图片来自网络)
词向量很好理解,也是模型中关于词最主要信息所在;
段向量是因为BERT里有下句预测任务,所以会有两句拼接起来,上句与下句,上句有上句段向量,下句则有下句段向量,也就是图中A与B。此外,句子末尾都有加 [SEP] 结尾符,两句拼接开头有 [CLS] 符;
位置向量则是因为Transformer模型不能记住时序,所以人为加入表示位置的向量。
之后这三个向量拼接起来的输入会喂入BERT模型,输出各个位置的表示向量。
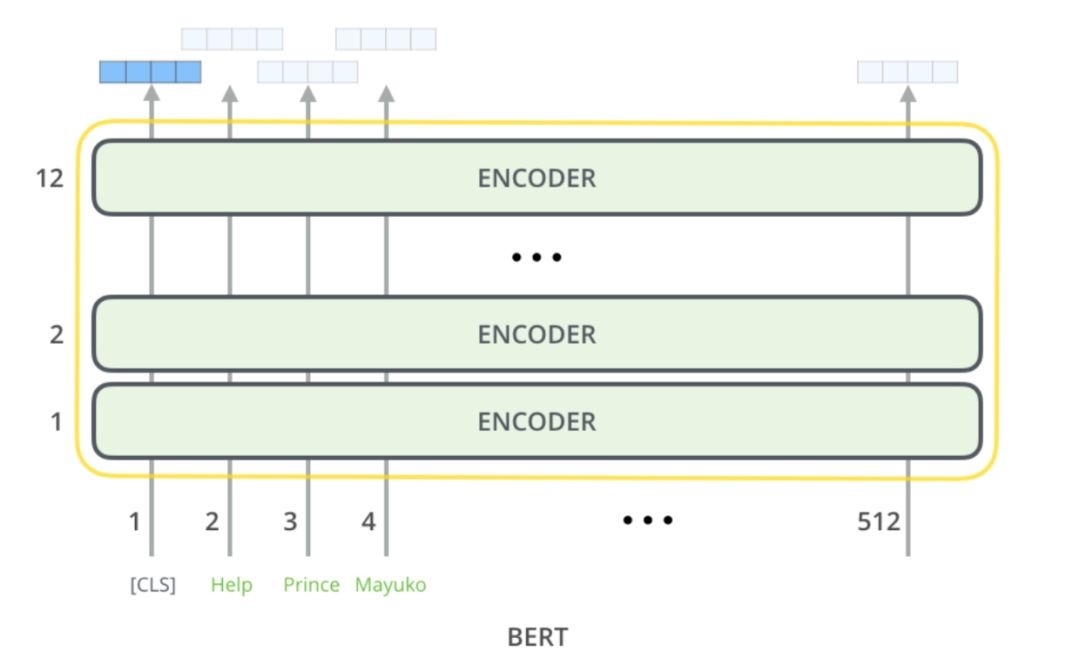 BERT 模型向量表征(图片来自网络)
BERT 模型向量表征(图片来自网络)
- 对于英文模型,使用了
Wordpiece模型来产生Subword从而减小词表规模;对于中文模型,直接训练基于字的模型。 - 模型输入需要附加一个起始
Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。 - 模型能够处理句间关系。为区别两个句子,用一个特殊标记符
[SEP]进行分隔,另外针对不同的句子,将学习到的Segment Embeddings加到每个Token的Embedding上。 - 对于单句输入,只有一种
Segment Embedding;对于句对输入,会有两种Segment Embedding。
预训练策略
在训练语言模型时,确定训练目标是一个难题。 BERT采用了两种预训练策略,分别是MaskedLM (MLM,掩语言模型) 和Next Sentence Prediction (NSP,下句预测)。
MLM(完形填空)
通过随机掩盖一些词(替换为统一标记符[MASK]),然后预测这些被遮盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息。
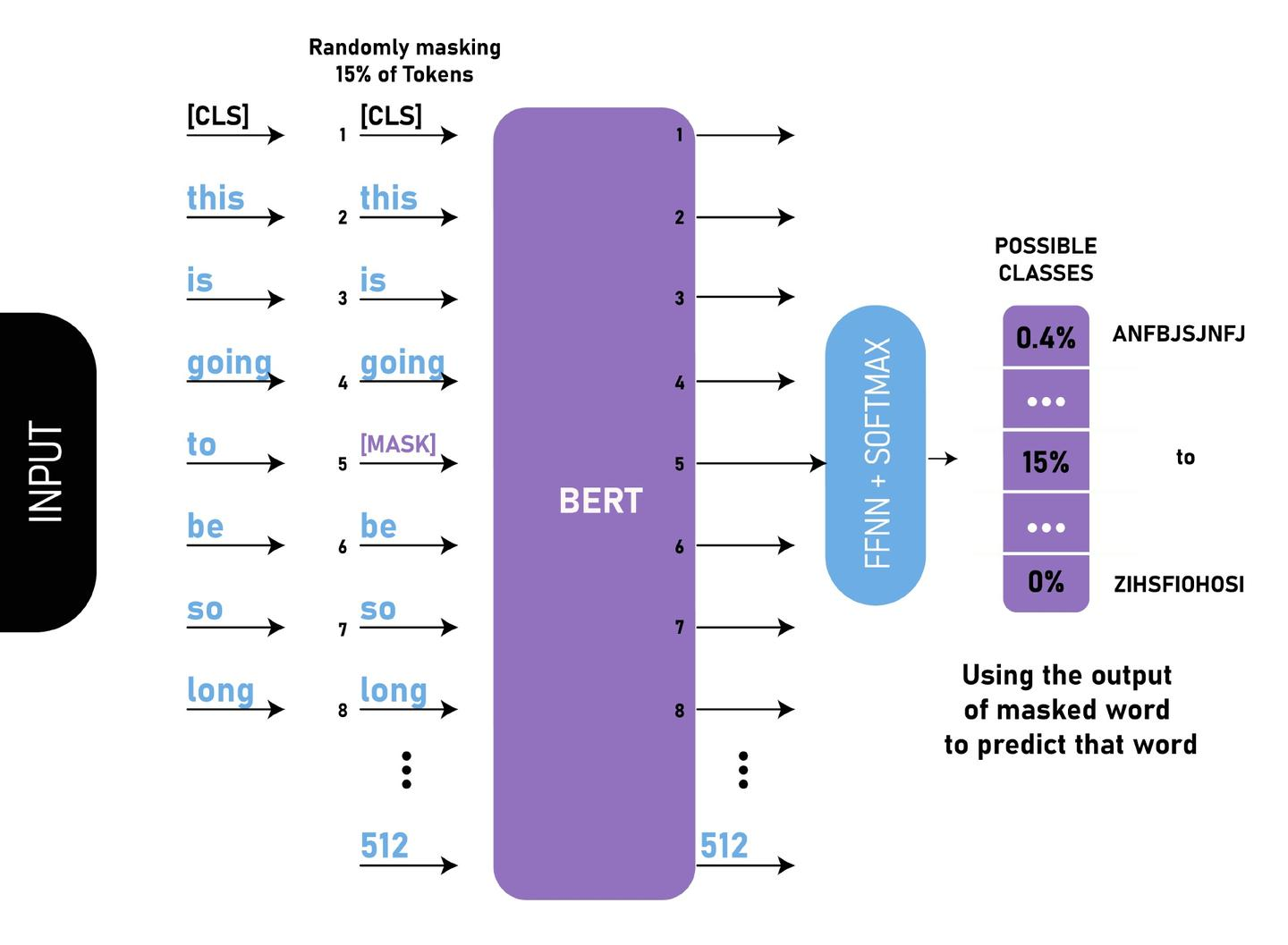 BERT MLM(图片来自网络)
BERT MLM(图片来自网络)
这样做会产生两个缺点:
- 会造成预训练和微调时的不一致,因为在微调时
[MASK]总是不可见的; - 由于每个
Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。
对于第一个缺点的解决办法是,把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于Transformer Encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。
对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
NSP
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。
这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
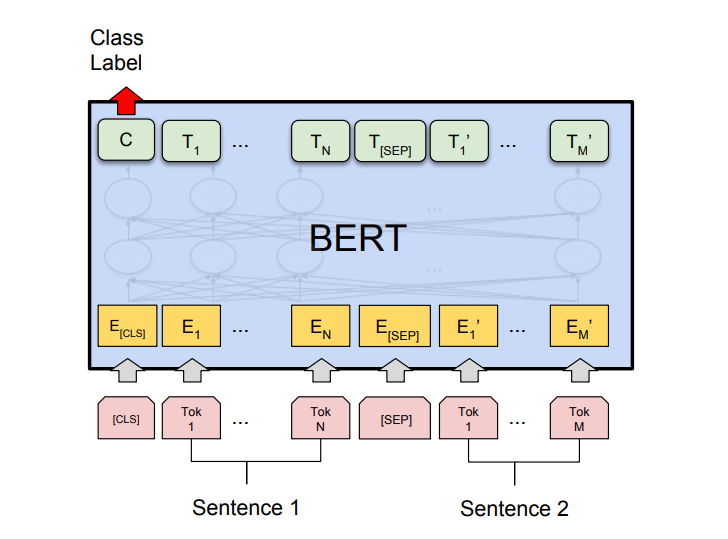 BERT NSP(图片来自网络)
BERT NSP(图片来自网络)
预训练模型-网络拓扑
论文中,模型同时使用MLM和NSP进行训练,以最小化两种策略的综合损失函数。
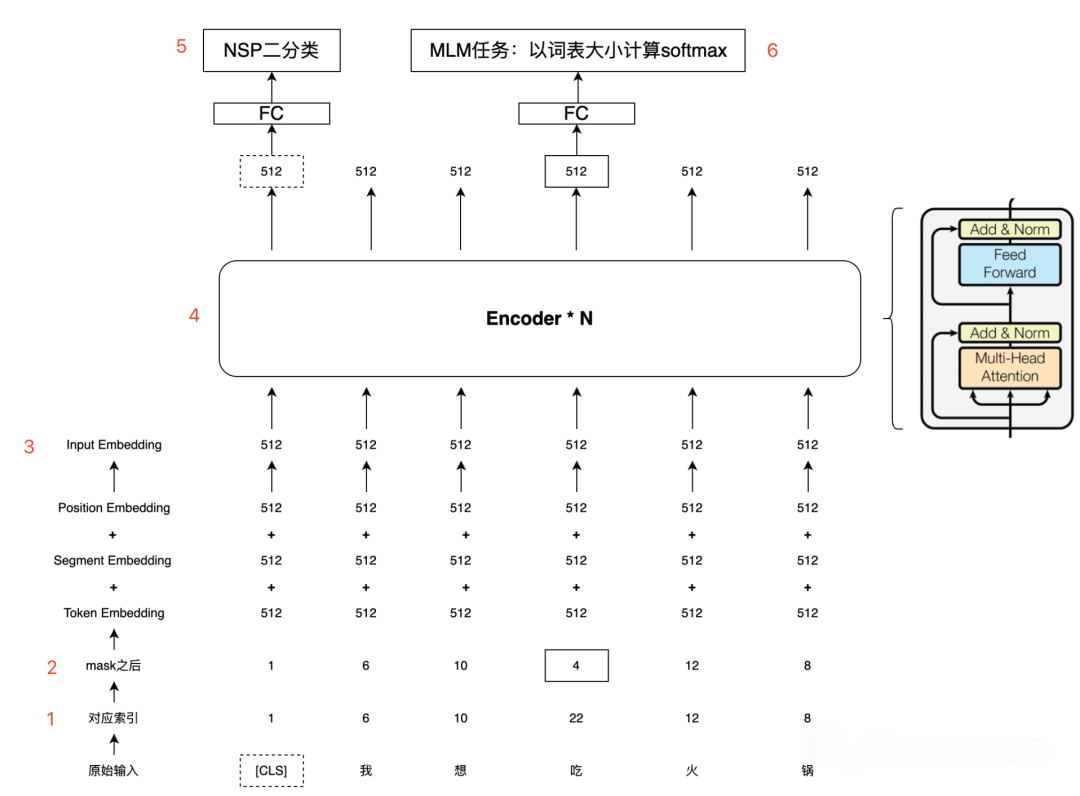 BERT model(图片来自网络)
BERT model(图片来自网络)
Fine-tuning
BERT预训练模型就像宰好待烹的猪,finetune便是烹饪之法,猪头能用来做成香糯浓醇的烧猪头肉,猪蹄能用来做成劲道十足的红烧猪蹄,身上的梅花肉,五花肉,里脊肉也各有各的做法。于是对于Bert finetune,也就有各种料理之法。
针对不同的NLP下游任务,微调BERT预训练模型,需要根据任务场景,指定输入和输出,以及微调训练所需要收敛的损失函数,训练出模型的效果才能更好地适应下游任务。
Joint BERT模型
Joint BERT模型,基于BERT的架构,使用其强大的双向上下文表示能力。它通过在BERT的基础上进行简单的微调(fine-tuning),来同时处理意图分类和槽位填充任务,属于对抗性多任务学习。
Joint BERT模型通过使用BERT的隐藏状态来同时预测意图和填充槽位。具体来说,它使用特殊标记[CLS]的第一个隐藏状态来预测意图,而其他标记的最终隐藏状态则用于通过softmax层分类槽位填充标签。
Joint BERT模型的优化目标是最大化条件概率p(yi, ys|x),即给定输入x时,意图yi和槽位序列ys的联合概率。这通过最小化交叉熵损失来实现端到端的微调。