白话MySQL分库分表
为什么要分库分表?
当然是数据库有了性能瓶颈,IO或CPU瓶颈会导致数据库的活跃连接数增加,可能会达到可承受的最大活跃连接数阈值,导致应用服务无连接可用,造成灾难性后果。可以先从代码、SQL、索引、硬件条件(比如CPU、内存、磁盘IO、网络带宽)等方面优化,如果这几项没有太多优化空间,就该考虑分库分表了。
分库可以提高
MySQL集群的并发能力和数据容量,分表可以降低单表的数据量,提高查询效率。
- 库表指标合理的参考范围(仅供参考),具体情况应具体分析
- 单表记录数,
500w-1000w- 单一DB实例,并发峰值
1500-2000 qps,数据容量1TB
IO瓶颈
- 磁盘读
IO瓶颈:对于热点数据,数据库缓存放不下,查询时产生大量磁盘IO,查询慢导致产生大量活跃连接。- 使用一主多从,读写分离,多个从库分摊查询流量;
- 分库 + 水平分表。
- 磁盘写
IO瓶颈:数据库写入频繁,频繁写IO会产生大量活跃连接。- 只能分库,用多个库来分摊写入压力;
- 水平分表后,单表存储的数据量还会减少,插入数据时索引查找和更新的成本会更低,插入速度更快。
CPU瓶颈
SQL中包含join、group by、order by,非索引字段条件查询等增加CPU运算的操作,会对CPU产生明显压力。SQL有优化的空间,就针对SQL进行优化,也可以把计算量大的SQL放到应用中处理;单表数据量太大(比如超过
1000w),查询遍历数据的层次太深,或者扫描行数太多,SQL效率会很低,也会非常消耗CPU,可以根据业务场景分库分表(水平拆分、垂直拆分)。
为什么InnoDB单表的容量瓶颈大概在500w-1000w?
先看MySQL InnoDB单表的容量瓶颈是怎么来的?从性能上来说,MySQL采用B+树类型做主键索引,B+树有个特点,记录数超过一定量的时候,B+树索引树的高度就会增加。而每增加一层高度,数据检索时就会多一次磁盘IO。在单表数据量超过经验阈值时,索引树深度的增加会带来磁盘IO次数的增加,进而导致查询性能的下降。
MySQL InnoDB引擎做磁盘IO的单位,不是磁盘块,而是一个数据页。 磁盘上读数据,是以块为单位来读的,一个块大小1-4KB(可以配置),我们可以认为一块就是4KB。块相对来说比较小,为了减少磁盘读取的次数,不是需要哪块读哪块,而是多读一点(预读),进行IO时单位一般都不是磁盘块,是一页一页读的(PageCache),PageCache大多是4个磁盘块,比如InnoDB默认每页大小为16KB,这跟参数配置有关。
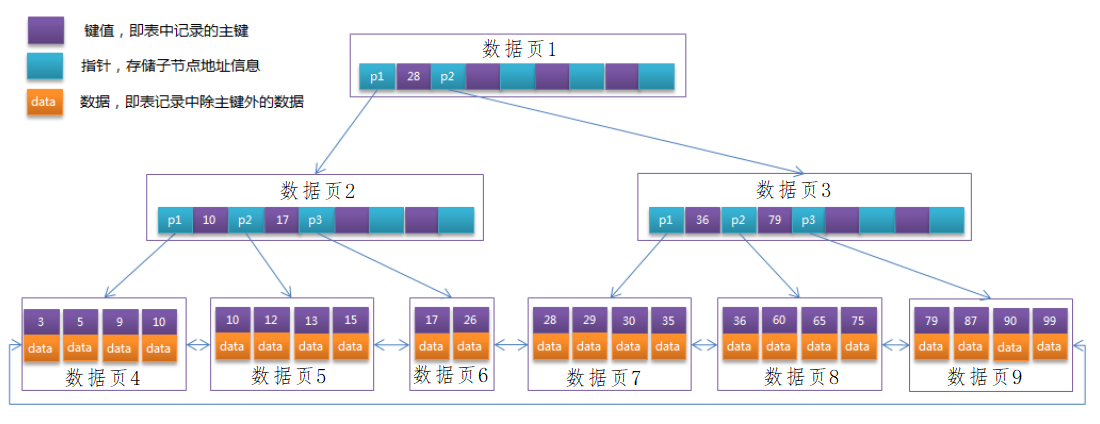 B+树结构示意图(图片来自网络)
B+树结构示意图(图片来自网络)
非叶子节点中,存储的是索引的键值和下一层的指针p1(指向的是磁盘地址)。中间的这些值(比如28)是键值(有序的)。树上的每一个节点都是一个Page,读的时候是以一个Page为单位读的,如果树越深,IO次数就越多(只读根节点,发生一次IO就够了,如果树有两层,比如找79,就得先读第一页,再读第三页,做两次IO)。树的高度,对性能的影响太大了,高度越矮越好。IO性能很低,而且页在磁盘上的物理位置不是顺序写。
根节点大小是固定的,一个页16KB,根节点就是16KB,根节点常驻内存,但是从第二层开始就不是常驻内存了。
B树,数据和键值(或者说索引)是在一块存储的,我们知道键值很小,有的主键就是8个字节的长整型,但是数据很大(一条记录后边有content,甚至还有长长的text,一条记录大小有2-3M),一页能放几条记录很难说,假设1K一条记录,一页才能放16个数据,B树每个节点放的数据记录很少的话,这就导致新节点的扩充,树就变得又瘦又高。每增加一层,查找就增加一次磁盘IO。用B树一下子就干到10层,甚至100层,性能怎么能快的起来呢。
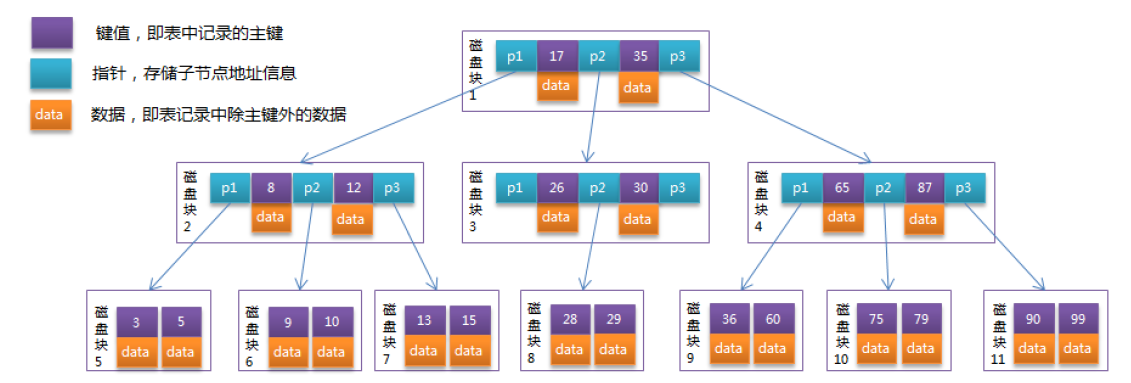 B树结构示意图(图片来自网络)
B树结构示意图(图片来自网络)
B+树和B树的根本区别,B+树把数据部分从非叶子节点,迁移到叶子节点里边去。非叶子节点省下来的磁盘页空间专门用来放键值和索引,查找时我们都是用键来检索,又不是全文检索,用不到数据来查找。用非主键查找,建好非主键的索引(非聚簇索引),找到主键后再回表查。
简单推算下,
一页16KB,16KB能放多少条索引记录?一条索引记录分两部分,键值(BIGINT 8字节)、下一页的物理地址(8个字节),加起来16字节,一页能放16KB/(8+8)=1K个键值,为了方便估算,取10^3。
100w,就是10^3 * 10^3,就两层就够了。理想情况下,三层就是10^3 * 10^3 * 10^3,10亿条记录。实际上,每个节点可能不能完全填满,如果没能填满,10亿条可能就得4层或者5层了。
所以可以估算1000w就是2层多一点,可能就是3层,1000w以上可能就得到4层或5层以上了。
综上所述,1000w条记录的B+树高度一般在2-4层。
3层要发生多少次IO操作呢?InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说,查找某一键值的行记录时最多只需要1~3次磁盘IO操作。
B+树,根本在减少树的深度,进而减少磁盘IO次数。
怎么评估分库分表的规模?
参见存储架构篇
为什么官方建议使用增长主键作为索引?为什么不能使用UUID作为索引的值?
减少页分裂和移动的频率
结合B+树结构的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。
为什么会产生页的分裂?
- 回头看
B+树的结构,叶子节点中,如果是聚簇索引,data就是数据,如果是非聚簇索引,data就是主键。键是有序的,方便做二分查找。- 如果插入数据时,键值是不断增长的,插入数据只需要往后增加即可,不需要改前面的,不需要前面的节点做分裂。
从B+树出发介绍了垂直拆分表的意义
为了减少磁盘IO,就应该减少每一页中单条记录的大小,每一页就尽可能多放一点记录,读出来的数据行就会更多,在查询时就会减少IO次数。
- 列数多,读一个范围的数据可能要读好几页。
- 假设
100列,每列10个字节,一行就是1kb,一个Page16k,16行
- 假设
- 列数少,读一个范围的数据可能只用读一页一次
IO就够了。- 假设
50列,每列10个字节,一行就是512byte,一个Page16k,32行
- 假设
分库分表时,分片键怎么选择?
分片键选择的时候,大概要考虑两个维度,一个是尽可能减少数据倾斜,一个是提高检索性能。
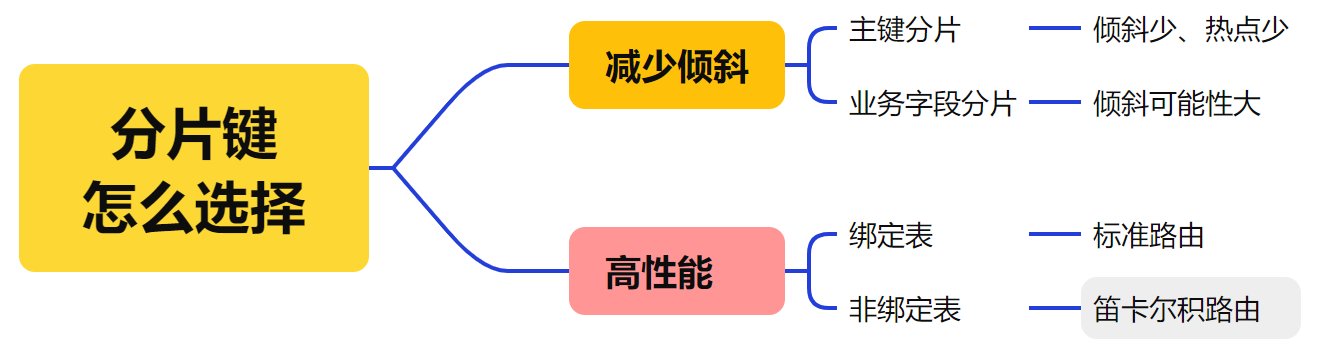 怎么选择分片键
怎么选择分片键
两大维度不仅涉及到分片键的选择,还涉及到关联关系的考量。选择分片键不止看一个表,还会看周边的关联表,考虑到业务本身,要查哪些表。
梳理下路由规则,看哪些是高性能的,哪些是低性能的。
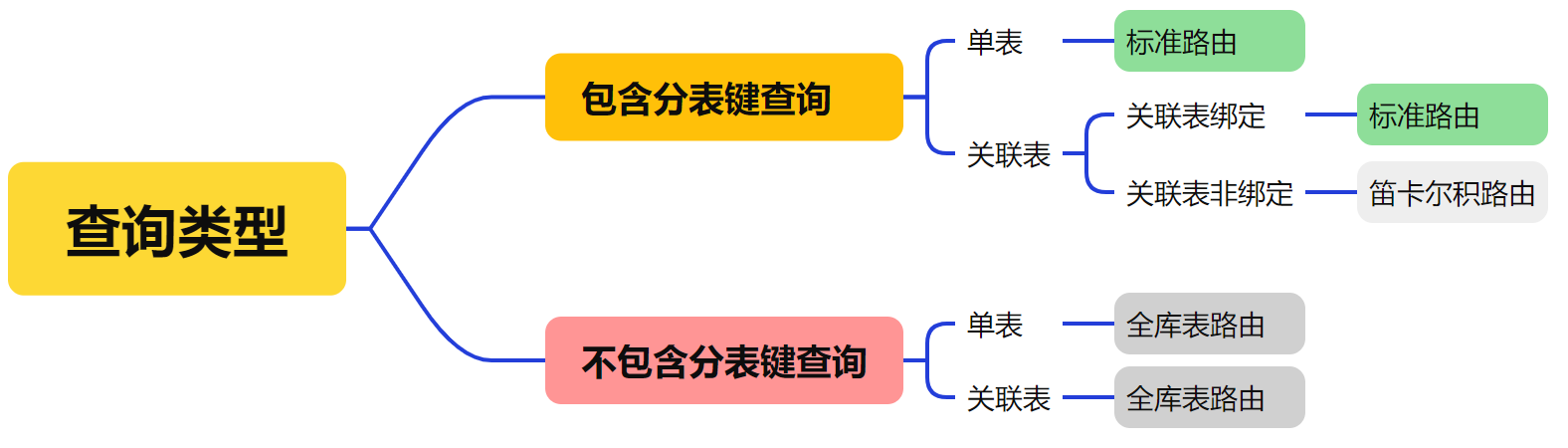 sharding查询类型
sharding查询类型
不包含分片键查询,全库表路由的性能是比较低的,尽可能携带分片键查询。比如,分100张表,用年龄来查询,每张表都会去查询,一次查询相当于走了100次数据库访问。不携带分片键查询的场景比较多,或者比较复杂,怎么提高它的性能?其中一种方案是用NoSQL解决方案
总结
- 关联表场景下面,尽量减少笛卡尔积路由(笛卡尔积路由有很多无效查询);
- 对于标准路由来说,优化空间比较大的
case,是关联表绑定(主表、子表)。绑定表要求两个表是同一个分片键,非常适合主子表模式; - 使用主键分片,会比较少的产生热点,因为主键在设计的时候,会保证均匀递增;
- 做分库分表设计的时候,要注意一个大问题,要关联的数据,分片必须要分在同一个库,上面说的所有路由策略,都没有跨库。
 sharding非跨库关联查询
sharding非跨库关联查询
基因法
用户的订单不在同一个库,查的时候是查不出来的,希望同一个用户的订单路由到同一个库,避免跨库。用户表和订单表,无法通过绑定表的方式实现避免跨库,只能用基因法实现分库基因。
业务:查询用户的所有订单、查询订单详情
字段:用户ID、订单ID
普通水平切分:
- 根据订单
ID切分,则无法一次查询用户的所有订单;- 根据用户
ID切分,则需要先查订单所属用户。
基因ID算法:在分库分表算法一样的情况下,分片的尾数值一样。
什么是分库基因?
通过uid分库,假设分为16个库,采用uid % 16的方式来进行数据库路由,这里的uid % 16,其本质是uid的最后4个bit决定这行数据落在哪个库上,这4个bit,就是分库基因。
基因法
32位是1个G,60位能存放2^18个G,足够用了。
如上图所示,uid=666的用户发布了一条订单(666的二进制表示为:1010011010),
- 使用
uid % 16分库,决定这行数据要插入到哪个库中- 分库基因是
uid的最后4个bit,即1010- 在生成
id时,先使用一种分布式ID生成算法生成前60 bit- 将分库基因加入到
tid的最后4个bit- 拼装成最终
64bit的tid- 这就保证了同一个用户发布的所有订单的
tid,都落在同一个库上,tid的最后4个bit都相同- 通过
uid%16能定位到库,tid%16也能定位到库- 全局唯一
ID也可以通过表自增位置和自增范围实现,比如用户ID哈希为1的表,自增位置为1,自增范围为10
分库分表之后怎么进行join操作?
首先看是哪种
join,join大致分为左连接、右连接、内连接、外连接、自然连接。
Shardingjdbc不支持跨库关联,之前路由都是说的同一个数据源里边。尽可能使用策略,让查询的数据分到同一个库里。
分库的join怎么解决?
- 比如经常用左外连接,两个表用相同的分片键,并进行表绑定,防止产生数据源实例内的笛卡尔积路由。使得
join的时候,一个分片内部的数据,在分片内部完成join操作,再由shardingjdbc完成结果的归并,从而得到最终的结果。 - 另外,可以用基因法。
分库分表后,跨库关联怎么解决?模糊条件查询怎么处理?
这两个问题可以用相同的方案解决,采用查询和存储分离的方案,即索引和存储隔离架构。在结构化存储里完成基础的工作;对于复杂检索或跨库关联,不在shardingjdbc做了,引入NoSQL。
业内比较标准的架构
- 使用结构化的
RDBMS(比如MySQL)存储基础数据,完成日常操作(业务通过分片键查询MySQL);- 对于检索的数据,存在
es,走高速检索(通过条件查询es索引数据);- 不是所有数据都需要检索,有大量字段不需要检索,把全量数据存在海量存储
hbase里(通过rowKey查询hbase全量数据)。
引入这么多的中间件(包含结构化数据、搜索数据、全量海量数据),怎么保障数据一致性?查询大致分为两类,
- 带着分片键的,就走分库分表;
- 复杂模糊查询或者跨库,把符合条件的
id从es里边查出来,拿到id取数据交给hbase。
hbase,Hadoop体系下的分布式海量存储中间件,根据rowKey查询(前缀树),可以优化到50wqps。
- binlog同步保障数据一致性的架构
在很多业务情况下,我们都会在系统中加入redis缓存做查询优化, 使用es做全文检索。如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。这种数据同步的代码跟业务代码糅合在一起会不太优雅,可以把这些数据同步的代码抽出来形成一个独立的模块。数据来源是MySQL,把增删改同步到es和hbase里边,使用Canal + MQ,订阅MySQL Binlog日志,发送到消息队列,同步到多个目标。