MQ顺序消息
序言
顺序消息,就是生产端发送的消息顺序和消费端接收的消息顺序一样。消息顺序,一般是指时间上的顺序性。
先看下MQ的消息场景,再来看实现MQ顺序消息需要考虑哪些因素。
从MQ的消息存储看,底层消息是直接写入到文件的,它是一个顺序存储结构,没有用B树、B+树等类似数据结构。一方面,复杂数据结构会影响数据写入/读取的性能;另一方面,MQ功能需求简单,不需要复杂数据结构来支持检索。
理想情况下,MQ顺序消息实现的效果应该是,生产端顺序发送消息,Broker按接收顺序存储消息,消费端按Broker存储顺序消费消息。实现顺序消息的核心就是,Broker接收到的消息顺序要和生产端发送的顺序保持一致。
实际上,多个生产者,因为发送时间不同,网络延迟不同,发送到
Broker和落盘顺序无法保证;单个生产者,异步发送,失败重试,导致Broker接收到的消息顺序和发送顺序不一致,落盘顺序无法保证;Topic有多个分区,一个生产者同步发送,存在生产分区分配策略,消息可能发到多个分区,也无法保证顺序。
顺序消息实现方案
思考下,保持MQ底层顺序存储结构不变,怎么实现顺序消息?
从上面分析可以看到,实现
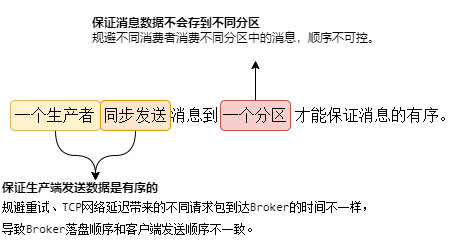
MQ顺序消息的需要满足两个条件,
- 一个生产者同步发送消息到一个分区;
- 一个分区只能给同一个消费者消费(一个分区绑定一个消费者就可以满足这个条件)。
第一个条件有三个要素,分别是单一生产者、同步发送、单一分区。如果要实现MQ的全局顺序消息,这三个要素缺一不可。
 在MQ中实现全局顺序消息的前提
在MQ中实现全局顺序消息的前提
但如果要求系统只能有一个分区,系统就会失去水平扩容能力,严重影响系统的性能。有些业务场景并不要求所有数据有序,比如电商场景,同一个用户提交订单、订单支付、订单出库,这三个消息消费者需要按照顺序来进行消费,类似这种场景的顺序消息只需要保证用户级别的消息顺序,就是局部有序(只要保证局部有序的数据写到同一个分区就行)。
局部有序常见的方案,就是根据标识将需要有序的数据写到同一分区,这种方案可以水平扩容(使用不同标识)。
这个方案有个缺点,如果某个标识的数据量很大,可能出现写入数据倾斜,导致集群
Broker之间的负载出现倾斜,影响集群的稳定性。
数据倾斜问题纯靠服务端很难解决,需要客户端配合把数据打散,这样一来就无法保证顺序了。如果既要顺序,又要解决数据倾斜,需引入复杂的数据结构,在查询时重排序,类似MySQL中使用Orderby对查询结果排序,这样复杂度比较高,对性能也有很大影响,不适合MQ。这个时候要trade-off balance了。
不同MQ的实现
主流
MQ都是通过标识来实现的,比如Kafka和Pulsar中的消息Key,RocketMQ的消息组,RabbitMQ的Route Key。被标识的数据会被路由到同一个分区进行存储,保持消息有序。
RocketMQ
RocketMQ支持消息组(MessageGroup)的概念,生产者在发送消息时,通过MessageQueueSelector指定把消息投递到哪个消息组,同一个消息组的消息会被发送到同一个分区(MessageQueue)中。
- 局部有序:一个消息组下的消息有序
- 全局有序:不同消息组下的消息有序(如果实现全局有序,就只能牺牲性能了)
Kafka/Pulsar
支持按Key Hash的生产分区分配策略将数据写入同一分区,使用起来就是给消息指定一个key,对key做Hash运算来指定消息发送到哪一个分区,实现的是分区有序。
- 分区有序:单个生产者 + 同步发送 +
HashKey
RabbitMQ
RabbitMQ在生产时没有生产分区分配的过程,是在服务端进行的,得通过Exchange和Route Key实现顺序消息。
Exchange根据传入的Route Key将数据路由到不同的Queue中存储。