MQ选型
序言
业务发展初期,基础设施不够完善,基础架构人员正在为消息队列选型头疼,没有统一、可靠、稳定的消息队列中间件可供使用。某些业务场景需要使用消息队列的生产/消费机制来实现异步解耦,这个时期的业务特点是数据量不大,场景也不复杂,只是需要缓冲实现立即/延时异步分发消息,并没有用到消息队列的高级功能,比如事务消息、顺序消息、死信队列这些。为了及时满足业务需求,可以暂不使用业界标准的消息队列,业务开发人员自己使用Redis实现具有简单生产/消费功能的消息队列SDK,业务服务集成SDK后,每个业务服务的pod都是一个消费者,通过定时服务注册和队列分配等机制来实现一个分布式的简单消息队列。
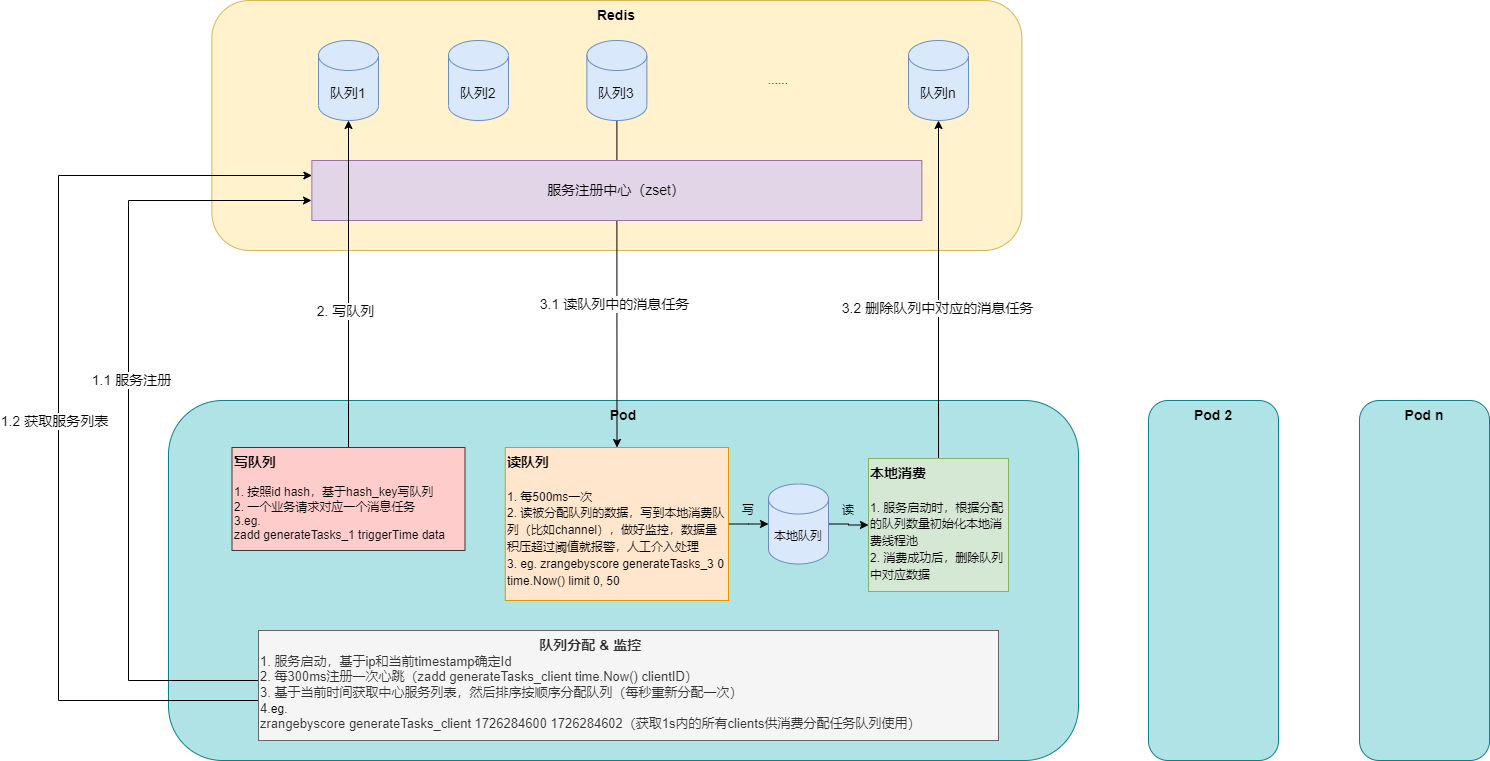 使用Redis实现简单的分布式消息队列
使用Redis实现简单的分布式消息队列
但这样,一方面无疑增加了业务开发人员的工作量,日常还需要维护自己实现的这款消息队列,说不定还会有一些隐藏比较深的bug,比如由于某些单机分配到队列但没有消费线程而导致饥饿消费等,大大消耗了业务开发人员的精力。另一方面,随着业务数据量的增长,Redis不能满足业务场景需求,数据存储在内存,Redis宕机重启有丢失数据的风险,没及时消费会打爆内存,存的消息数据过大也会有性能和稳定性问题。
在整体技术架构中,根绝业务场景和数据量的特点尽快选型并引入一款或多款合适的标准消息队列中间件,非常有必要。
MQ发展历程
标准消息队列的发展时间线如下,
 消息队列发展时间线
消息队列发展时间线
从功能需求发展上看,发展趋势是消息–流–消息和流融合;从架构发展来看,则是单机–分布式–云原生/Serverless。
消息是指业务消息,在业务架构中用来作消息传递,用作系统的消息总线。
流是指在大数据架构中用作大流量数据削峰,日志吞吐就是一个典型场景。
最开始(2000年左右),以IBM MQ和AMQP为代表的消息队列主要解决了业务对消息的需求,如异步、解耦。
随着移动互联网发展,大数据兴起(2010年左右),传统消息队列在架构上已经无法满足大流量的吞吐需求,涌现了以Kafka为代表的消息队列,解决大吞吐、大流量场景需求。消息队列也进入分布式时代,出现了分区、副本、一致性概念。
随着业务场景越来越复杂,业务消息的数据量越来越大,基于开源AMQP的RabbitMQ在性能和架构上已经无法满足消息场景的需求,于是出现了RocketMQ。
随着云原生/Serverless理念的兴起,基于弹性/成本的考虑,架构往云原生/Serverless方向演变(利用云上的弹性计算、存储等基础设施实现架构的Serverless,按需使用、按量付费,让使用方感受到免运维、低成本)。基于云原生架构设计的Pulsar开始逐渐成熟,出现了计算存储分离、分层存储、多租户、弹性计算等概念。
从降低成本角度来看,消息队列对弹性计算的需求提出计算存储分离架构,对低存储成本的需求提出分层存储概念,对资源复用的需求提出多租户概念。消息队列也都在提高竞争力,从功能、容灾、多架构、生态等方面着手建设。
AMQP是一个消息队列协议规范,它不是一款具体的消息队列。
因为不同消息队列的访问协议不一样,导致不同的消息队列需要用不同的SDK访问,客户的切换成本很高。2003年,多个金融服务机构希望制定一个消息队列的协议规范,希望不同消息队列的协议都根据这个标准实现,这样就可以不用重复开发SDK,不同应用程序之间的交互和切换可以更简单方便。
MQ选型
RabbitMQ功能丰富,支持延时消息、死信队列、优先级队列、事务消息等,低流量下稳定性较高;缺点则是在大流量场景下有明显的瓶颈和稳定性问题。那时Kafka刚开源不久,功能比较简单,只有生产和消费,RabbitMQ因为功能丰富,稳定性较高,成为主流选择。
基于JMS协议的ActiveMQ存在生态、功能、稳定性问题,用的人比较少。
RocketMQ在定位上和RabbitMQ很像,功能丰富,在业务消息中经常用,可以看作是RabbitMQ的高可用、分布式升级版。RocketMQ是在移动互联网浪潮下发展起来的,业务场景更加复杂,支持更多功能,比如消息Tag、消息轨迹、消息查询等等。在架构和性能层面,RabbitMQ设计较早,当时分布式设计理念还不成熟,在架构层面存在较大缺陷,大流量/高并发场景下容易出现集群不可用、网络分区等情况。RocketMQ在分布式架构上的实现相对合理,在大流量/高并发场景下稳定性、数据可靠性的表现都不错,性能介于RabbitMQ和Kafka之间。
Pulsar和Kafka很像,主要定位在流领域,主打大吞吐的流式计算,Pulsar后边有同时发展消息和流两个方向的趋势。Kafka的功能比较简单,支持基本的发布订阅、幂等、事务消息。Pulsar在满足这些功能的基础上,也想支持RocketMQ和RabbitMQ的功能,功能最丰富。在架构和性能层面上,Pulsar的架构设计比Kafka更符合云原生架构,支持比如计算存储分离、弹性、多租户,可以看作Kafka的升级版,主要解决Kafka当前的一些痛点问题,比如集群扩缩容慢、分区迁移需要Rebalance、无法支持超多分区等。目前性能和Kafka没有特别大的差别,但Pulsar发展时间较短,架构较复杂,功能支持较多,目前在稳定性上Kafka会比Pulsar好很多,Pulsar的稳定性还有待提升。
RabbitMQ是国外Rabbit公司使用AMQP协议的Erlang开源的,RocketMQ是阿里开发的,Kafka是Pulsar是Yahoo开发的。除了开源的,商业化闭源的MQ也有很多,比如微软在1997年推出MSMQ、AWS在2004年推出SQS,IBM MQ则在金融、证券行业用的最多。
总结一下
- 业务消息场景,优先选择
RocketMQ。RocketMQ性能高,社区活跃,集群化架构稳定,功能也非常丰富,RabbitMQ当前架构存在缺点,单机存在瓶颈,在高QPS场景表现不是那么好,并且可能出现网络分区。从功能、性能、稳定性出发,优先推荐使用RocketMQ。 - 流方向场景,优先选择
Kafka。Kafka本身性能和吞吐表现非常优越,延时和可靠性表现也不错。虽然Pulsar主打替换Kafka,并且功能丰富,架构设计理念先进,但发展周期较短,很多功能还不稳定,当前的现网运营表现不好。虽然Kafka存在扩容、Rebalance方面的缺陷,但从稳定性、性能出发,还是会优先使用Kafka。 - 在日常使用中,也可能会根据业务需求同时运营多款消息队列,比如
RocketMQ/RabbitMQ+Kafka。
RocketMQ支持程度
- 多协议支持(
HTTP、TCP、MQTT、AMQP、Kafka) - 协议扩展(
OpenMessaging) - 多语言支持(
Java、C++、Go) - 一致性(
Raft) - 多订阅模式(集群广播)
- 定时消息
- 延时消息
- 消息顺序(局部顺序、全局顺序)
- 消息压缩
- 消息重试
DLQ(死信队列)- 多租户模型
- 事务性消息
- 消息堆积+持久化
优先级队列- 消息过滤(
SQL92的过滤语法) - 批量发送(应用同步模式避免消息丢失)
Consumer与分区关系限制(<=分区数)- 监控面板
- 消息轨迹
- 消息查询
- 访问安全(
TLS & Token) - 扩容能力(不友好,消费者可能收到重复消息,需要在消费端通过唯一标识保证幂等性)
- 故障恢复(不友好,
nameserver与broker部署到一起,broker假死会引起机器重启) - 跨区域部署
Kafka支持程度
- 多协议支持(
Kafka) - 多语言支持(
C/C++、Python、Go、Java、Erlang、.NET、Ruby、PHP、Rust、Swift) - 一致性(
request、required、acks) - 多订阅模式(同一个
Topic,会广播给不同的Group;一个Group,只有一个consumer可以消费该消息。) 定时消息延时消息- 消息顺序(分区有序)
- 消息压缩(
Gzip、Snappy、Lz4、Zstd) 优先级队列消息重试(本身不支持,但很多SDK支持)`DLQ`(死信队列)- 多租户模型
- 事务性消息
- 消息堆积+持久化
消息过滤(本身不支持,客户端业务自行过滤)- 批量发送(提供一个
RecordAccumulator消息收集器,将发送给相同Topic的相同Partition分区的消息缓冲一下,当满足条件时,一次性批量将缓冲的消息提交给Kafka broker。) - Consumer与分区关系限制(
consumer <=分区数) - 监控面板(
Monitor/Manager/Eagle可视化监控) - 消息轨迹(支持两种方式回溯,一种是基于消息偏移量回溯,一种是基于时间点的消息回溯。)
- 消息查询
- 访问安全(
SSL认证、SASL密码认证) - 扩容能力(横向扩容节点不友好,可能数据丢失)
- 故障恢复(
3台以上就可以组成一个可用的zookeeper集群,只要集群中存在超过一半的机器能正常工作,那么整个集群就能正常对外服务。) - 跨区域部署
RabbitMQ支持程度
- 多协议支持(
HTTP、STOMP、MQTT、AMQP) - 多语言支持(
Java、Erlang、C#) - 一致性(
Mirror queue,Erlang专属一致性方案) - 多订阅模式(自身有一套极灵活的路由模式)
- 定时消息(有,但队列会阻塞)
延时消息消息顺序消息压缩- 优先级队列
消息重试DLQ(死信队列)多租户模型事务性消息(不支持,实现Exactly-Once语义;不支持,最终一致性)- 消息堆积+持久化(积压后性能表现差,大量积压会导致应用崩溃)
- 消息过滤
- 批量发送
Consumer与分区关系限制(3.7以上无限制)- 监控面板(
rabbitmq-management项目重监控,指标较为丰富) - 消息轨迹(
Tracing插件,会影响性能) 消息查询- 访问安全(
TLS、Token) - 扩容能力(相对友好,
Erlang天生具备分布式特性) - 故障恢复(脑裂问题严重,恢复较难)
跨区域部署