AI Agent 元年,于 2025 开启
序言
近年来,AI领域迎来了颠覆性变革,以大语言模型(LLM)为核心的生成式技术正以前所未有的速度重塑人机交互的边界。以ChatGPT的对话式突破到Gemini、Claude的多模态跃迁,LLMs不仅展现出对人类语言的深刻理解,更逐步演化为知识推理与创造性表达工具。然而,这仅是智能革命的起点——当LLMs与智能体(Agent)技术深度融合,AI开始突破“被动应答”的局限,迈向自主感知、决策与行动的“主动智能”新时代。
Agent智能体作为具备目标驱动能力的AI实体,正在通过LLMs获得自然语言交互、逻辑推演与环境适应的关键能力。从AutoGPT的自动化任务分解到GPT-4o的实时多模态交互,从科研Agent加速药物发现到企业级Agent重构工作流程,这一融合正催生“数字员工”、“AI协作者”等新范式。技术进化的背后是LLMs赋予智能体类人的认知泛化力,而Agent智能体则为LLMs搭建起连接虚拟与物理世界的行动桥梁。两者的协同,既在攻克复杂场景的可靠性、可解释性等挑战,也在伦理对齐与安全可控层面引发深层思考。
LLM发展历程
早期萌芽阶段(1950s-1956s)
- 艾伦·图灵提出图灵测试(
1950),定义机器智能的哲学目标,成为AI领域的理论基石; - 达特茅斯会议首次提出人工智能概念(
1956),规划自然语言处理、机器学习等研究方向,但受限与算力与数据规模,早期AI仅能处理符号逻辑推理等简单任务。
早期探索阶段(1950s–1990s)
- 规则驱动方法
- 基于
Noam Chomsky生成语法理论(1957),构建句法解析系统(如SHRDLU,1970); - 依赖人工编写正则表达式,难以处理复杂语言现象(如歧义句
Time flies like an arrow)。
- 基于
- 统计方法革命
- 机器学习兴起(
1980),以统计学习和数据驱动为核心,专家系统(如DENDRAL、XCON)在特定领域展现潜力,但泛化能力有限; IBM引入Brown Corpus(1990)与隐马尔可夫模型(HMM)进行词性标注;n-gram模型与统计机器翻译(如IBM Model 1-5)成为主流;- 谷歌早期搜索引擎采用
PageRank与TF-IDF统计方法改进检索效果。
- 机器学习兴起(
神经网络与词嵌入阶段(2000s–2010s中期)
- 神经语言模型奠基
Bengio团队于2003年提出神经网络语言模型(NNLM),首次引入词嵌入技术,解决“维度灾难”问题;Word2Vec(2013)通过分布式表征提升语义理解能力,通过Skip-Gram和CBOW模型实现高效语义表征(如“国王 - 男人 + 女人 = 女王”)。
- 序列模型发展
- 循环神经网络(
RNN)与长短期记忆网络(LSTM)增强序列建模能力。LSTM(1997)和GRU(2014)通过门控机制缓解梯度消失,但处理超长文本时效率低下。
- 循环神经网络(
Transformer深度学习架构突破(2017s–2018s)
- 自注意力机制
- 谷歌提出
Transformer架构(2017-06),通过自注意力机制解决长距离依赖问题,提升翻译流畅度(如BLEU分数提升30%+); - 基于自注意力机制实现并行化序列建模,彻底革新
NLP范式,为LLM奠定技术基础。
- 谷歌提出
- 预训练范式确立
OpenAI发布GPT-1(2018-06),参数达1.17亿,采用单向自回归预训练,首次将Transformer与大规模无监督预训练结合,验证语言模型的通用生成能力;GPT的核心原理,是把Transformer解码器拿出来,在没有标号的大量文本数据上训练一个大语言模型,来获得一个预训练模型,之后在子任务上做有监督的微调得到每一个任务所要的分类器(多任务学习,Multitask learning),类似于计算机视觉上的做法——半监督学习(GPT里边叫自监督学习,semi-supervised learning),但微调会有过拟合问题,微调后的泛化效果在实际应用中不一定就很好;- 谷歌推出
BERT(2018-10),引入双向遮蔽语言模型(MLM)任务,开启预训练语言模型(PLM)时代;思想和GPT不一样,它把Transformer编码器拿出来,收集一个更大的数据集用作预训练,效果比GPT-1好很多,BERT有俩模型,分别是BERT-Base、BERT-Large; OpenAI随后推出GPT-2(2019-02),参数达15亿,相较于GPT-1,GPT-2沿着原来的路线,收集了一个更大的数据集,训练了一个更大的模型,深入挖掘语言模型的潜力,虽然综合效果并没有BERT-Large好,但在新意度方面提出了zero-shot(prompt则是实现zero-shot能力迁移的关键技术手段),相较于Multitask learning,做到下游任务时,不需要下游任务的任何标注数据,也不需要对下游任务训练模型,也就是训练一个模型,在任何地方都能用,让模型理解prompt后输出,GPT-2模型比BERT-Large还要大。
大模型爆发期(2020s–2023s)
- 参数规模跃升
OpenAI发布GPT-3(2020-05)参数达1750亿,推动LLM从实验室迈向实际应用;GPT-3尝试解决改善GPT-2的效果,回到了GPT一开始的few-shot设定,就像现实生活中人类学习也要从少量样例学习后做拓展一样,只不过人类在样本的有效性上做的比较好,只需要一点样本就好了,但语言模型需要大量样本,few-shot在每个子任务上只补给成本可控的样本,不用太多;因模型太大,GPT-3在子任务训练的时候,并不做梯度更新,不做微调,拼的就是模型的泛化性,不做训练,只做预测。在GPT-3中,meta-learning其实就类似GPT-2里边的Multitask learning,in-context learning其实就类似zero-shot、one-shot或few-shot,只不过是为了和之前GPT模型区分开来才出现的新词而已。GPT-3不更新梯度,定义好任务之后,真正做任务之前,one-shot告诉模型一个例子,模型看到例子对应的整个句子后,能从句子中提取有用的信息来帮助后面的推理,虽然例子是训练样本,但不会对模型做梯度更新,而是在模型做前向推理时,能通过注意力机制处理较长的序列信息,从而从例子中间抽取出有用的信息来帮助下面的推理,这也就是上下文学习的由来。few-shot是对one-shot的拓展,之前就给一个样本,现在给多个样本,例子可以更长,但更长不一定有用,不一定能抽取出长句子的信息,取决于模型处理的序列长度的能力。GPT-3对新任务更友好,不需要调超参,只需要做预测就行了,但坏处就是训练样本就是特别大(比如英语翻译法语任务,可以在网上找到几百上千个样本来帮助翻译),想放到模型里边是很难的事情,模型有可能处理不过来,第二个问题就是有一个效果还不错的训练样本,每一次预测都得给到模型,因为梯度未更新,并没有存到模型。GPT-3比GPT-2数据和模型都大了100倍,效果做出来不出意外地也非常好,实际应用的效果非常惊艳,纯属暴力出奇迹;- 开源社区崛起,
Meta推出LLaMA系列,降低大模型使用门槛;多模态模型(如GPT-4、Gemini)实现文本、图像、音频的跨模态融合; - 后续模型如
GPT-4(2023)、LLaMA(2023)突破万亿参数规模。
- 技术优化方向
- 稀疏注意力机制、混合专家系统(
MoE)降低计算成本;多模态融合与指令微调增强任务适应性。
- 稀疏注意力机制、混合专家系统(
多模态与专业化升级(2023s-2025s)
- 垂直领域渗透
LLM技术深入行业场景(2023),医疗、金融、教育等领域涌现专业化模型(如DeepSeek-R1、Claude),在医疗诊断辅助、金融风险评估、教育个性化推荐等场景加速落地,模型通过自我进化机制(如数据进化、模型进化)提升复杂推理能力,强调推理能力与垂直领域的适配性;
- 安全与标准建设
- 国际标准《大语言模型安全测试方法》发布(
2024),推动LLM伦理对齐与安全可控;混合专家架构(MoE)、联邦学习等技术优化模型效率与隐私保护;
- 国际标准《大语言模型安全测试方法》发布(
DeepSeek开源(2025年初),加速AGI落地DeepSeek-R1等模型实现低成本高性能训练,结合Agent智能体技术构建自主决策能力,加速AGI技术落地。
LLM技术演进特征
- 规模增长:从统计模型(百万参数)到
LLM(万亿参数),模型规模呈指数级增长; - 能力扩展:从文本预测扩展至复杂语义理解、跨模态生成及自我优化;
- 算法创新:从单一语言理解向多模态交互、自主智能体演进,动态稀疏训练、无监督对齐等技术持续突破算力与数据瓶颈;
- 行业变革:
LLM重塑教育、医疗、制造等领域的知识服务模式(如ACLAS的全球化AI教育平台),推动生产力跃迁与全球协作; - 安全治理:开源生态与标准化建设并行,平衡技术创新与伦理风险,探索人机协作的可持续发展路径;
- 研究焦点:当前聚焦于提升推理效率、降低能耗与增强可解释性。
LLM从符号主义时代的理论萌芽,历经深度学习革命与预训练模型爆发,最终演化为多模态、专业化、安全可控的下一代AI基础设施,持续拓展人类认知与机器智能的融合边界。
AI Agent
Agent是什么
定义
AI Agent是一种概念方法论,围绕LLM建设一个生态,形成智能体。它能够感知环境、自主决策并执行任务,通过LLM作为核心大脑,结合记忆模块、规划能力和工具调用机制,实现类似人类的目标驱动行为。
- 用
prompt来引导LLM进行规划(Reflection、Self-critics、Chain-of-Thoughts、Subgoal-decomposition),进而做出正确的决策,有了一步步的输出。 - 输出给到
tools,去做真正的action,也就是执行。 memory在规划中也有很大的作用,通常大模型和外部的交流和接触是通过memory去获取的。
LLM-Agent的两种架构
LLM + 记忆 + 规划 + 工具 + 反馈
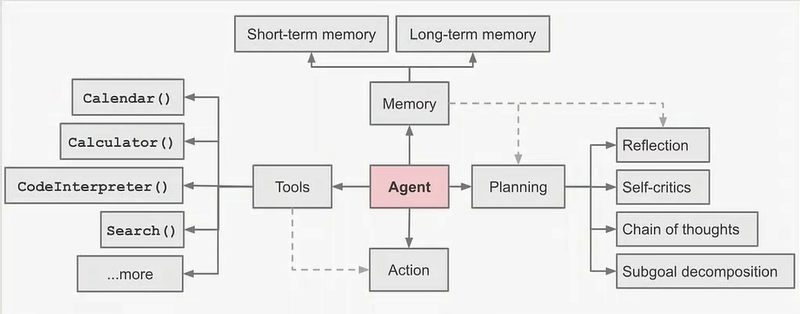 AI Agent 架构
AI Agent 架构生物学角度理解
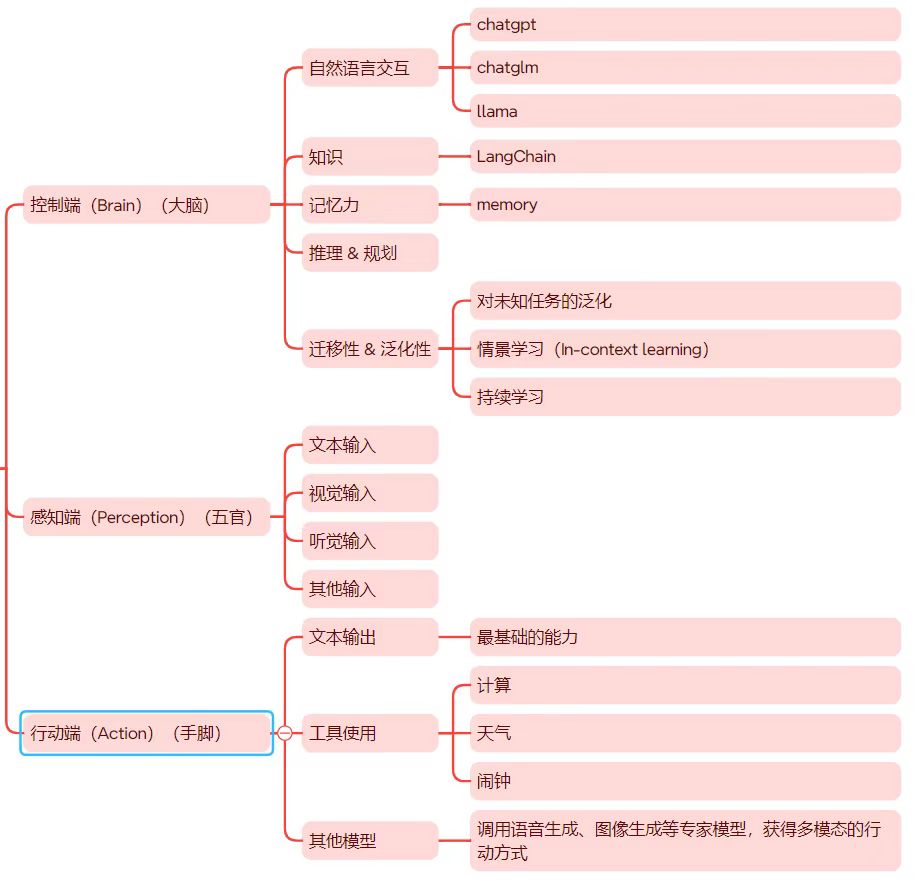 AI Agent 架构(生物学角度理解)
AI Agent 架构(生物学角度理解)
Agent为什么出现?
用户输入-LLM模型输出的模式,从功能看起来更像是一个大脑决策(任务规划)的角色,AI Agent是大语言模型能力的外延(LLM+插件+执行流程),大模型能力是有上限的,端到端虽然理想,但是复杂问题很难解决,Agent这种拆解形式,会更加流行。AI Agent让LLM具备目标实现能力,并通过自我激励循环来实现给定的目标。LLM与LangChain等工具相结合,释放了内容生成、编码和分析方面的多种可能性,目前在ChatGPT插件中比较有代表性的插件就是code interpreter。在通往AGI通用人工智能的路上,AI Agent是必经之路。
LLM的缺点
- 它是基于训练数据的概率统计规律,并非是真实逻辑,会产生幻觉;
- 结果并不总是真实的;
- 对时事的了解有限或一无所知;
- 很难应对复杂的计算;
- 缺少垂直领域的数据。
Agent的优势
- 给模型加各种外挂,添加五官和手脚,实现感知和动作,让专业的人做专业的事。
- 给概率统计规律,连接了真实世界的逻辑,所以更加强大。
- 直接由
LLM端到端实现AGI,当前不太可能,就像聪明的人类会使用工具一样,把LLM作为Agent中心,将复杂任务分解,在每个子步骤实现自主决策和执行。 LAM(Large-Agent Models)成为当前主流。- 外部工具,比如谷歌搜索(获取最新信息)、
PythonREPL(执行代码)、Wolfram(进行复杂的计算)、外部API(获取特定信息)等。
Agent的组成
记忆、规划、工具
记忆 Memory
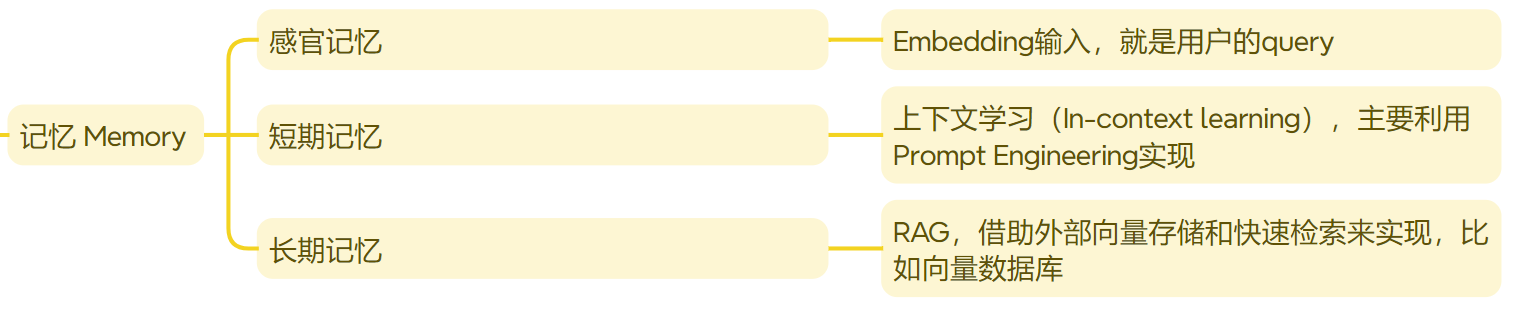 AI Agent Memory
AI Agent Memory
规划 Planning
一项复杂的任务通常涉及许多步骤,Agent必须了解任务是什么并提前进行规划,通常通过Prompt提示词工程来实现。
任务分解
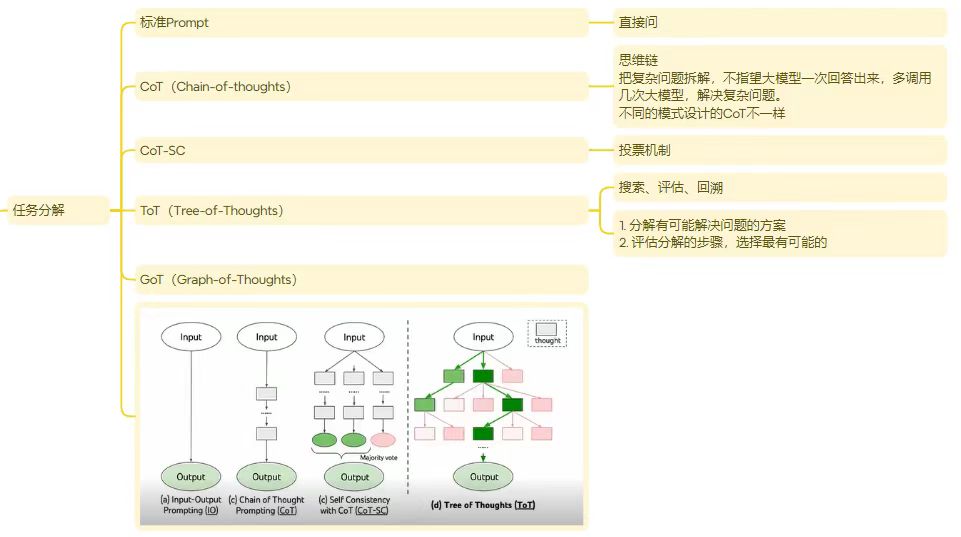 AI Agent Planning 任务分解
AI Agent Planning 任务分解
自我反省
自我反省,允许Agent通过完善以往行动决策和纠正以往错误来迭代改进。
- ReAct
- 将动作空间扩展为一个任务特定的离散动作和语言空间的组合,将推理和动作集成在
LLM中,引导LLM如何输出和思考; - 融合
Reasoning和Acting的一种Prompt范式,仅仅包含thought-action-observation步骤,很容易判断推理的过程的正确性。
 AI Agent Planning ReAct
AI Agent Planning ReAct - 将动作空间扩展为一个任务特定的离散动作和语言空间的组合,将推理和动作集成在
- Self-ask
- 一种
follow-up的使用范式,仅仅包含follow-up,immediate answer步骤; Self-ask需要一个/少量Prompt来引导LLM如何回答Prompt问题。整个过程中,会大量的跟搜索引擎或向量知识库交互,不断地自我问答,来提升大语言模型(绿色背景为LLM输出,白色是LLM的输入,下划线为Inference-time)。
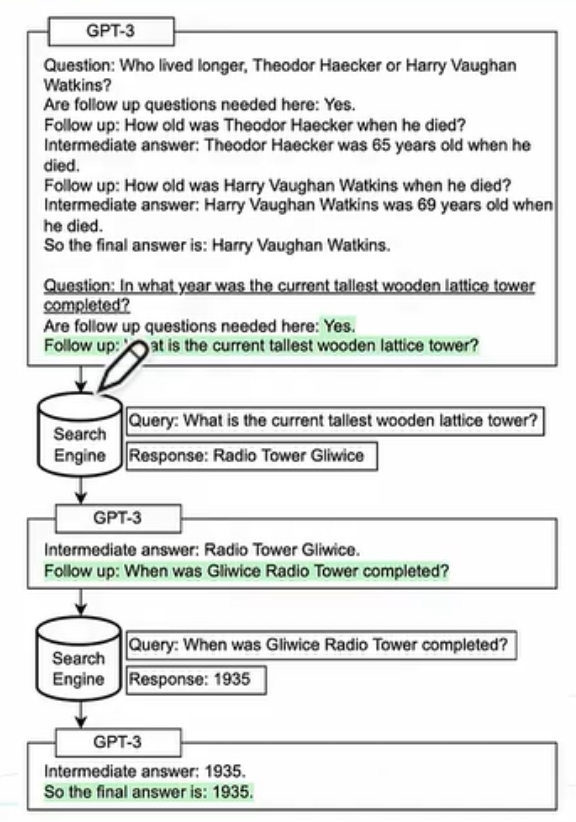 AI Agent Planning Self-ask
AI Agent Planning Self-ask - 一种
工具 Tools
借助外部API工具,补充LLM缺少的行动能力,让专业的人做专业的事。Action,有了工具,就可以执行了。
 AI Agent Tools
AI Agent Tools
Agent热门应用
- 模拟智能体(
Simulations Agent)- 在模拟器中包括一个或多个
Agent相互作用; - 主要组成包括长期记忆、模拟环境,多个
Agent之间相互作用,离不开对环境的依赖; - 比较著名的例子,比如斯坦福“西部世界”(
Generative Agent)、Role-Playing框架(CAMEL)等。
- 在模拟器中包括一个或多个
- 自动化智能体(
Automatic Agent)- 给定一个或多个长期目标,独立执行这些目标;
- 比如
AutoGPT、BabyGPT、AgentGPT。
- 多模态智能体(
Multimodal Agent)- 除了
NLP信息外,还可以拓展到图像、语音、视频的交互; - 比如
Visual ChatGPT、AssistGPT、HuggingGPT等。
- 除了
Agent问题和挑战
- 目前
Agent需要人为设计; - 依赖大模型的核心能力,大模型本身够强才行;
- 链路过长,某一环节出错,前功尽弃;
- 多次调用大模型,效率不高;
- 迁移能力弱,换模型需要重新写提示词;
- 能力强弱,取决于写提示词的水平;
- 无论是
AI技术,还是Agent发展,都处于探索阶段,离AGI还有一段距离,当前可以把它作为一个助手使用,提高效率,并不能完全托管。
结语
AI Agent的崛起标志着AI从被动响应迈向主动创造的新纪元。作为LLM的“行动化身”,它正以三种范式重构人机交互。
- 从工具到伙伴:通过自主规划与工具调用,
AI Agent突破传统AI的“指令-执行”边界,成为能独立完成复杂任务的智能体(如自主科研实验设计、跨平台商业决策); - 从孤岛到生态:多智能体协作系统(
Multi-Agent Systems)正在形成动态网络,通过角色分工与博弈机制实现群体智能涌现(如自动驾驶车群协同、供应链博弈优化); - 从感知到创造:结合多模态感知与具身智能(
Embodied AI),AI Agent开始突破数字世界,在物理空间中操作机器人、调控工业设备,催生“硅基生命”的早期雏形。
这一进程不仅将重塑生产力范式(据Gartner预测,到2027年50%企业流程将由AI Agent主导),更在叩击人类文明的核心命题——当机器具备目标拆解、策略迭代和自我进化能力,我们亟需在技术狂飙中构建价值锚点:如何在效率革命与伦理约束间取得平衡?如何定义人机协作的“可控边界”?这或许才是AI Agent时代留给人类的最大课题。
数字世界的“认知革命”已然启幕,而真正的颠覆,或许才刚刚开始。
2025 Agent元年 于 北京 记